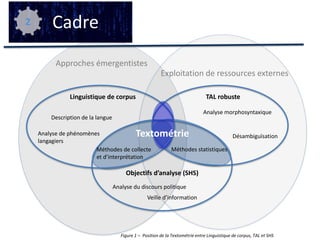
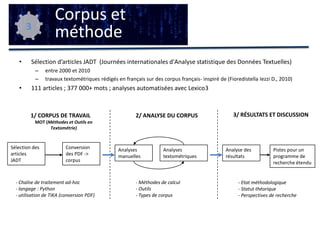
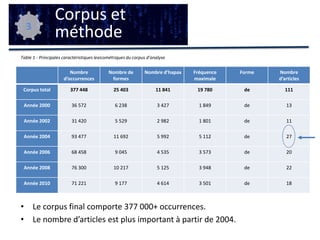
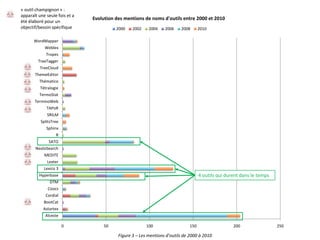
Cette étude aborde l'application de la textométrie aux corpus francophones, en examinant les méthodes d'analyse et leur intégration dans les recherches linguistiques. Elle évalue l'utilisation d'outils textométriques sur un corpus d'articles en français et propose une modélisation opérationnelle des pratiques textométriques. Les résultats mettent en lumière les tendances et les limites méthodologiques dans l'usage de la textométrie, soulignant la nécessité d'une standardisation et d'une réflexion méta-méthodologique.



![Comment articuler corpus et méthodes d’analyses pour l’étude linguistique du français ? Une question abordée par la linguistique …[PERY-WOODLEY 1995] : description linguistique de corpus[HABERT 2005] : outils de TAL pour la linguistique de corpus[PINCEMIN 2008],[RASTIER, 2001],[VALETTE, 2009] : sémantique textuelle, linguistique instrumentéeQue l’on se pose pour répondre aux besoins en recherche industrielleContexte des thèses CIFRE, sur l’apport de la Textométrie aux systèmes de veille économique et à l’analyse des opinionsNécessité de trouver des solutions rapides aux problèmes posésDistinction des différentes tâches pour une intégration fluide dans une chaîne complète de traitementProblématiqueArticulation corpus et méthodes d’analyse1](https://image.slidesharecdn.com/aflspresentationencours-110911102929-phpapp01/85/AFLS-EMM-ML-3-320.jpg)