Télécharger en tant que PDF, PPTX





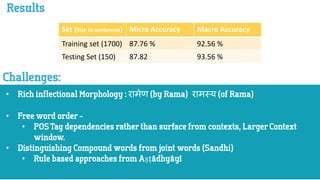


Le document présente des résultats de performances sur un ensemble d'apprentissage et un ensemble de test. La précision micro et macro de l'ensemble d'apprentissage est respectivement de 87,76 % et 92,56 %, tandis que celles de l'ensemble de test sont de 87,82 % et 93,56 %. Ces mesures suggèrent une bonne capacité de généralisation du modèle évalué.






















![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)