














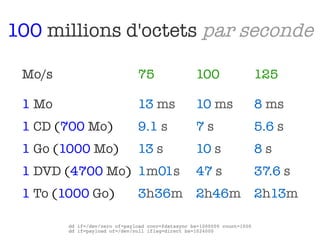
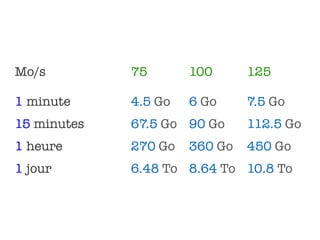

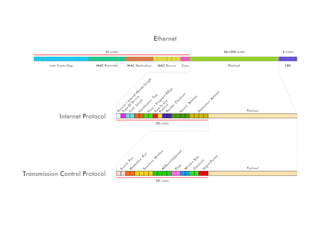












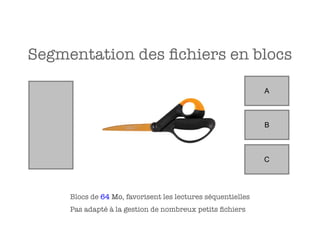

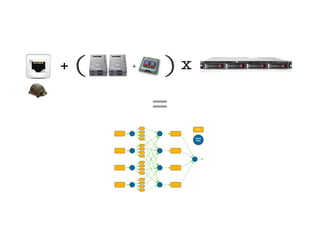
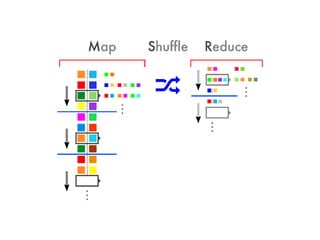





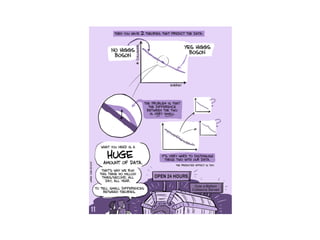







Le document aborde l'importance croissante des 'big data' en matière de volume, vélocité et variété des données, ainsi que les défis technologiques associés à leur traitement. Il souligne la nécessité d'analyser rapidement des données de plus en plus variées, y compris des données non structurées, et présente des statistiques sur les performances de traitement des données. Enfin, il met en évidence la valeur que les entreprises peuvent tirer de l'exploitation efficace de ces données.










































