Ce document présente un projet sur Riak KV, un système de gestion de bases de données NoSQL distribué, mettant l'accent sur le stockage, l'interrogation et les mécanismes de cohérence des données. Il aborde les concepts de base tels que le modèle clé-valeur, l'architecture distribuée, et les utilitaires pour l'administration. Le rapport inclut des expérimentations réalisées dans un environnement Docker avec un jeu de données JSON provenant du jeu télévisé Jeopardy.








![INSERTION ET INTERROGATION DES DONNÉES
Maintenant que les concepts globaux ont été abordés, passons à la pratique. Dans cette partie nous
allons insérer des données dans des Buckets, interroger le serveur afn de récupérer ces données ou d’y
appliquer une transformation.
Mise en place de Bucket Types et insertion
Les Bucket Type permettent le partage de mêmes confgurations entre différents Buckets. Leur
utilisation est intéressante d’un point de vue administration (on peut avoir autant de Bucket Type que l’on
veut, chacun décrivant une confguration spécifque) et essentielle d’un point de vue performance d’un
cluster . En effet, un Bucket partagé entre différentes machines devra avoir la même confguration sur l’une
ou sur l’autre ; il est donc bien plus effcace d’assigner un Bucket Type à un Bucket (la gestion des
paramètres étant alors centralisée) plutôt que d’attribuer des paramètres spécifques directement au Bucket,
dans quel cas ce serait au cluster d’aller chercher ces variables de confguration et de les diffuser auprès de
l’ensemble des serveurs.
Le Bucket Type Default
Un seul Bucket Type est disponible lors de l’installation de Riak KV : le Bucket Type default.
Remarquez le premier argument « bucket-type » passé à notre utilitaire riak-admin ; il permet d’indiquer à
Riak KV que les informations que nous demandons ici concernent la gestion des Bucket Type. Un certain
nombre d’arguments suivent alors afn de préciser notre souhait d’information.
Nous pouvons lister les paramètres qui ont été défnis pour ce Bucket Type :
9
# riak-admin bucket-type list
default (active)
# riak-admin bucket-type status default
default is active
allow_mult: false
basic_quorum: false
big_vclock: 50
chash_keyfun: {riak_core_util,chash_std_keyfun}
dvv_enabled: false
dw: quorum
last_write_wins: false
linkfun: {modfun,riak_kv_wm_link_walker,mapreduce_linkfun}
n_val: 3
notfound_ok: true
old_vclock: 86400
postcommit: []
pr: 0
precommit: []
pw: 0
r: quorum
rw: quorum
small_vclock: 50
w: quorum
write_once: false
young_vclock: 20](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-9-320.jpg)


![• Bucket Type « Map »
Un Map est un tableau associatif associant à un ensemble de clés un ensemble correspondant de
valeurs. Il a une structure similaire à un document json (« clé » : »valeur ») mais sa structure connue par
l’applicatif permet de lui appliquer un certain nombre d’opérations : ajout d’une nouvelle valeur à une
nouvelle clé, modifcation ou suppression d’une valeur de clé existante. Un Map peut aussi contenir des
booléens, des compteurs (counters vus plus tard dans le rapport), des liste d’objets uniques (sets vus plus
tard dans le rapport) ou d’autres maps.
Création d’un Bucket Type « Map »
Avec la clé « props », nous indiquons à Riak KV que les éléments qui vont suivre vont être des variables de
confguration du Bucket Type. Ici, le paramètre « datatype » nous permet de personnaliser le type de
données contenues dans un Bucket dont le Bucket Type sera « bucket_type_map ».
Le Bucket Type est créé mais n’est pas encore actif :
12
#riak-admin bucket-type create bucket_type_map '{"props":{"datatype":"map"}}'
bucket_type_map created
WARNING: After activating bucket_type_map, nodes in this cluster
can no longer be downgraded to a version of Riak prior to 2.0
# riak-admin bucket-type status bucket_type_map
bucket_type_map has been created and may be activated
young_vclock: 20
w: quorum
small_vclock: 50
rw: quorum
r: quorum
pw: 0
precommit: []
pr: 0
postcommit: []
old_vclock: 86400
notfound_ok: true
n_val: 3
linkfun: {modfun,riak_kv_wm_link_walker,mapreduce_linkfun}
last_write_wins: false
dw: quorum
dvv_enabled: true
chash_keyfun: {riak_core_util,chash_std_keyfun}
big_vclock: 50
basic_quorum: false
allow_mult: true
datatype: map
active: false
claimant: 'riak@172.17.0.2'](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-12-320.jpg)
![• Bucket Type « Set »
Un Set est une collection de valeurs uniques. Ajouter dans un Set une valeur déjà existante n’aboutira donc
à aucune modifcation de celui-ci.
Création d’un Bucket Type «Set»
Le Bucket Type est créé mais n’est pas encore actif :
Activons le :
Créons maintenant un objet Set en Java:
15
#riak-admin bucket-type create bucket_type_set '{"props":{"datatype":"set"}}'
bucket_type_set created
# riak-admin bucket-type status bucket_type_set
bucket_type_set has been created and may be activated
young_vclock: 20
w: quorum
small_vclock: 50
rw: quorum
r: quorum
pw: 0
precommit: []
pr: 0
postcommit: []
old_vclock: 86400
notfound_ok: true
n_val: 3
linkfun: {modfun,riak_kv_wm_link_walker,mapreduce_linkfun}
last_write_wins: false
dw: quorum
dvv_enabled: true
chash_keyfun: {riak_core_util,chash_std_keyfun}
big_vclock: 50
basic_quorum: false
allow_mult: true
datatype: set
active: false
claimant: 'riak@172.17.0.2'
# riak-admin bucket-type activate bucket_type_set
bucket_type_set has been activated
//Initialisation du client
RiakCluster cluster = setUpCluster();
RiakClient client = new RiakClient(cluster);
//Création d'un Objet Set d'id question_example_1, dans un Bucket jeopardy_question de type bucket_type_set
Location question_example_set =new Location(new Namespace("bucket_type_set", "jeopardy_question"), "question_example_1");
//On envoie l'information au serveur
FetchSet fetch = new FetchSet.Builder(question_example_set).build();
client.execute(fetch);](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-15-320.jpg)
![Encore une fois, l’API REST ne peut être utilisée pour l’initialisation de l’objet.
Enregistrons maintenant des données dans notre Set :
« add_all » permet l’ajout d’un ensemble de valeurs à notre Set.
Que contient maintenant notre objet ?
Les valeurs d’un Set étant uniques, cet ajout sera par exemple ignoré :
Nous pouvons supprimer une valeur du Set :
L’objet contient alors :
Dans le client Java, le type Set étant connu, il est possible de lui appliquer plusieurs fonctions classiques
(isEmplty(), contains(), size() ...)
• Bucket Type « Counter »
Comme son nom l’indique, un Counter permet de créer un objet « compteur », contenant un nombre entier
et permettant de lui appliquer des fonctions élémentaires (additions et soustraction).
Création d’un Bucket Type «Counter»
16
# curl -XPOST http://localhost:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"add_all":["2004-05-10", "George III","HISTORIC NICKNAMES"]}'
# curl -GET http://localhost:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
{"type":"set","value":["2004-05-10","George III","HISTORIC
NICKNAMES"],"context":"g2wAAAABaAJtAAAADL8Aoe8LafemAAAAAWEDag=="}
# curl -XPOST http://localhost:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"add_all":["HISTORIC NICKNAMES"]}'
# curl -XPOST http://localhost:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"remove": "HISTORIC NICKNAMES"}'
# curl -GET http://localhost:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
{"type":"set","value":["2004-05-10","George III"],"context":"g2wAAAABaAJtAAAADL8Aoe8LafemAAAAAWEDag=="}
#riak-admin bucket-type create bucket_type_counter '{"props":{"datatype":"counter"}}'
bucket_type_set created](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-16-320.jpg)
![Le Bucket Type est créé mais n’est pas encore actif :
Activons le :
Créons maintenant un objet Counter grâce à l’API REST :
Il s’agit du seul Data Type fournit par Riak KV pour lequel la création de l’objet de requiert pas un client autre
que curl.
Le compteur est initialisé :
17
# riak-admin bucket-type status bucket_type_counter
bucket_type_counter has been created and may be activated
young_vclock: 20
w: quorum
small_vclock: 50
rw: quorum
r: quorum
pw: 0
precommit: []
pr: 0
postcommit: []
old_vclock: 86400
notfound_ok: true
n_val: 3
linkfun: {modfun,riak_kv_wm_link_walker,mapreduce_linkfun}
last_write_wins: false
dw: quorum
dvv_enabled: true
chash_keyfun: {riak_core_util,chash_std_keyfun}
big_vclock: 50
basic_quorum: false
allow_mult: true
datatype: set
active: false
claimant: 'riak@172.17.0.2'
# riak-admin bucket-type activate bucket_type_counter
bucket_type_counter has been activated
# curl -XPOST http://localhost:8098/types/bucket_type_counter/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"increment": 0}'
# curl -GET http://localhost:8098/types/bucket_type_counter/buckets/jeopady_question/datatypes/question_example_1
{"type":"counter","value":0}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-17-320.jpg)


![• Création de l’index Riak Search
Nous devons maintenant créer un index Riak Search utilisant le schéma précédemment défni. Cet
index ne sera pour le moment alimenté par aucune donnée.
L’index créé « jeopardy_index » utilise bien comme schéma « jeopardy_schema ».
• Attribution d’un index à une collection de données
L’index que nous venons de créer peut désormais être lié au choix soit à un Bucket Type, soit à un
Bucket.
Dans le cas où nous le lions à un Bucket Type, toutes les données des Buckets de ce type seront indexées
dans cet index ; il sera donc nécessaire de garder une cohérence de structure forte entre les données
insérées dans ces différents Buckets afn que toutes répondent au schéma Riak Search associé. Les futures
recherches utilisant cet index pourront alors se faire à travers les données stockées dans tous ces Buckets.
L’attribution d’un index lors de la création d’un Bucket Type se ferait alors ainsi :
Nous pouvons aussi directement lier un index à un Bucket (c’est ce que nous ferons ici) :
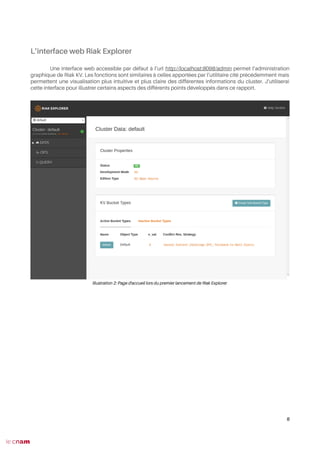
Toutes les actions précédentes peuvent aussi se faire et être visualisées grâce à l’interface Web :
21
Illustration 3: Liste des index créés avec leur schéma associé
# curl -XPUT http://localhost:8098/search/index/jeopardy_index
-H 'Content-Type: application/json'
-d '{"schema":"jeopardy_schema"}'
[info] <0.2691.0>@yz_index:core_create:284 Created index jeopardy_index with schema jeopardy_schema
# riak-admin bucket-type create mon_bucket_type '{"props":{"search_index":"leopardy_schema"}}'
# curl -XPUT http://localhost:8098/types/default/buckets/jeopardy_bucket/props
-H 'Content-Type: application/json'
-d '{"props":{"search_index":"jeopardy_index"}}'](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-21-320.jpg)
![• Alimentation de l’index
Insérons l’ensemble de notre collection de documents Jeopardy dans le bucket
« jeopardy_bucket »grâce à un script shell :
Vérifons que le Bucket et l’Index comportent le même nombre de données.
Nous pouvons récupérer le nombre de données dans le Bucket grâce à une fonction MapReduce simple :
22
Illustration 4: Détail de l'index "jeopardy_index"
#!/bin/bash
json_fle=$(cat jeopardy.json);
type="default"
bucket="jeopardy_bucket"
i=0;
for data in $(echo "${json_fle}" | jq -r '.[] | @base64'); do
((i++));
_jq() {
echo ${data} | base64 --decode;
}
json_item="'"$(_jq)"'";
insert_command=`echo curl -v -X PUT http://localhost:8098/types/$type/buckets/$bucket/keys/show_$i -H """Content-
Type: application/json""" -d $json_item`;
eval $insert_command;
done;
#curl -XPOST http://localhost:8098/mapred -H 'Content-Type: application/json' -d '
{"inputs":"jeopardy_bucket",
"query":[{"map":{"language":"javascript",
"keep":false,
"source":"function(jeopardykv) {return [1]; }"}},
{"reduce":{"language":"javascript",
"keep":true,
"name":"Riak.reduceSum"}}]}'
216770](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-22-320.jpg)
![Pour vérifer le nombre de données dans l’index, il sufft d’une requête renvoyant le nombre total de
documents (ici nous sélectionnant tous les documents ayant une clé category) :
• Interrogation de l’index
Voici quelques exemple d’interrogation de l’index nouvellement créé :
Cherchons les documents dont la catégorie est « ALL MY SON » :
La requête est passée après « q= » (pour query =). Riak Search nous indique que 5 documents
correspondent à notre requête et liste les liste avec leurs attributs stockés dans l’index.
23
# curl -XGET "http://localhost:8098/search/query/jeopardy_index?wt=json&q=category:*"
{"responseHeader":{"status":0,"QTime":52,"params":{"q":"category:*","shards":"172.17.0.2:8093/internal_solr/
jeopardy_index","172.17.0.2:8093":"(_yz_pn:62 AND (_yz_fpn:62)) OR _yz_pn:61 OR _yz_pn:58 OR _yz_pn:55 OR _yz_pn:52 OR
_yz_pn:49 OR _yz_pn:46 OR _yz_pn:43 OR _yz_pn:40 OR _yz_pn:37 OR _yz_pn:34 OR _yz_pn:31 OR _yz_pn:28 OR _yz_pn:25 OR
_yz_pn:22 OR _yz_pn:19 OR _yz_pn:16 OR _yz_pn:13 OR _yz_pn:10 OR _yz_pn:7 OR _yz_pn:4 OR _yz_pn:1","wt":"json"}},"response":
{"numFound":216770,"start":0,"maxScore":1.0,"docs":[{"round":"Double Jeopardy!","air_date":"2005-09-
27T00:00:00Z","category":"YOURE
A "STAR"","_yz_id":"1*default*jeopardy_bucket*show_70751*25","_yz_rk":"show_70751","_yz_rt":"default","_yz_rb":"jeopardy_buck
et"},{"round":"Double Jeopardy!","air_date":"2005-09-27T00:00:00Z","category":"LITERARY ____ OF
____","_yz_id":"1*default*jeopardy_bucket*show_70759*40","_yz_rk":"show_70759","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Double Jeopardy!","air_date":"2005-09-27T00:00:00Z","category":"CLARK"…...}]}}
# curl "http://localhost:8098/search/query/jeopardy_index?wt=json&q=category:"ALL MY SONS"
{"responseHeader":{"status":0,"QTime":4,"params":{"q":"category:"ALL MY
SONS"","shards":"172.17.0.2:8093/internal_solr/jeopardy_index","172.17.0.2:8093":"_yz_pn:64 OR (_yz_pn:61 AND (_yz_fpn:61)) OR
_yz_pn:60 OR _yz_pn:57 OR _yz_pn:54 OR _yz_pn:51 OR _yz_pn:48 OR _yz_pn:45 OR _yz_pn:42 OR _yz_pn:39 OR _yz_pn:36 OR
_yz_pn:33 OR _yz_pn:30 OR _yz_pn:27 OR _yz_pn:24 OR _yz_pn:21 OR _yz_pn:18 OR _yz_pn:15 OR _yz_pn:12 OR _yz_pn:9 OR
_yz_pn:6 OR _yz_pn:3","wt":"json"}},"response":{"numFound":5,"start":0,"maxScore":11.613354,"docs":
[{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4698*27","_yz_rk":"show_4698","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4704*42","_yz_rk":"show_4704","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4680*64","_yz_rk":"show_4680","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4686*51","_yz_rk":"show_4686","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4692*6","_yz_rk":"show_4692","_yz_rt":"default","_yz_rb":"jeopardy_bucket"}]}}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-23-320.jpg)
![Cherchons les documents dont la date de diffusion (air_date) est comprise entre le 01/03/2008 et le
01/12/2008 :
Il est bien sûr possible d’exploiter toutes les possibilités offertes par Solr et donc d’aller bien plus loin
(vraiment plus loin) que les deux exemples ci-dessus.
L’ Active Anti-Entropy
L’active Anti-Entropy est un processus permettant de rechercher et de corriger les incohérences et
différences entre les données stockées dans la base Riak RK et l’index Riak Search (Solr). Ces erreurs
peuvent être dues à de multiples raisons (extinction de serveur, problème matériel, problème réseau, etc.).
Le principe de l’AAE est qu’il est impossible de prévoir les pannes tant elles peuvent être diverses et parfois
diffciles à déceler ; il est alors plus effcace d’implémenter un script qui vérife en temps réel la bonne
duplication des informations voulues entre la base et l’index.
Il serait bien évidemment totalement ineffcace d’utiliser un processus qui scannerait d’un côté les données
présentes en base et de l’autre celles présentes dans l’index et de les comparer. Pour palier à ce problème,
l’AAE utilise le système des hashtrees (arbres de hashage ou arbre de Merkle).
Lors de l’insertion des données, celles-ci ont été réparties en plusieurs fragments sur le serveur (il s’agit en
fait de vnode mais nous conserverons le terme «fragment» dans cette partie pour plus de clarté. Les notions
liées à la répartition des données seront vues et expliquées dans la dernière partie de ce rapport).
24
# curl "http://localhost:8098/search/query/jeopardy_index?wt=json&q=air_date:[2008-03-01T00:00:00Z TO 2008-12-01T00:00:00Z]"
{"responseHeader":{"status":0,"QTime":8,"params":{"q":"air_date:[2008-03-01T00:00:00Z TO 2008-12-
01T00:00:00Z]","shards":"172.17.0.2:8093/internal_solr/jeopardy_index","172.17.0.2:8093":"_yz_pn:64 OR (_yz_pn:61 AND
(_yz_fpn:61)) OR _yz_pn:60 OR _yz_pn:57 OR _yz_pn:54 OR _yz_pn:51 OR _yz_pn:48 OR _yz_pn:45 OR _yz_pn:42 OR _yz_pn:39 OR
_yz_pn:36 OR _yz_pn:33 OR _yz_pn:30 OR _yz_pn:27 OR _yz_pn:24 OR _yz_pn:21 OR _yz_pn:18 OR _yz_pn:15 OR _yz_pn:12 OR
_yz_pn:9 OR _yz_pn:6 OR _yz_pn:3","wt":"json"}},"response":{"numFound":9521,"start":0,"maxScore":1.0,"docs":
[{"round":"Jeopardy!","air_date":"2008-05-
29T00:00:00Z","category":"NUMBERS","_yz_id":"1*default*jeopardy_bucket*show_70839*24","_yz_rk":"show_70839","_yz_rt":"defaul
t","_yz_rb":"jeopardy_bucket"},{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"I
DO","_yz_id":"1*default*jeopardy_bucket*show_70848*24","_yz_rk":"show_70848","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"THE 20th
CENTURY","_yz_id":"1*default*jeopardy_bucket*show_70835*57","_yz_rk":"show_70835","_yz_rt":"default","_yz_rb":"jeopardy_buck
et"},{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"THE 20th
CENTURY","_yz_id":"1*default*jeopardy_bucket*show_70841*64","_yz_rk":"show_70841","_yz_rt":"default","_yz_rb":"jeopardy_buck
et"},{"round":"Jeopardy!","air_date":"2008-05-
29T00:00:00Z","category":"NUMBERS","_yz_id":"1*default*jeopardy_bucket*show_70845*3","_yz_rk":"show_70845","_yz_rt":"default
","_yz_rb":"jeopardy_bucket"},{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"FAMILIAR
PHRASES","_yz_id":"1*default*jeopardy_bucket*show_70846*12","_yz_rk":"show_70846","_yz_rt":"default","_yz_rb":"jeopardy_bucke
t"},{"round":"Jeopardy!","air_date":"2008-05-
29T00:00:00Z","category":"FABRICS","_yz_id":"1*default*jeopardy_bucket*show_70837*57","_yz_rk":"show_70837","_yz_rt":"default"
,"_yz_rb":"jeopardy_bucket"},{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"I
DO","_yz_id":"1*default*jeopardy_bucket*show_70836*64","_yz_rk":"show_70836","_yz_rt":"default","_yz_rb":"jeopardy_bucket"},
{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"FAMILIAR
PHRASES","_yz_id":"1*default*jeopardy_bucket*show_70852*64","_yz_rk":"show_70852","_yz_rt":"default","_yz_rb":"jeopardy_bucke
t"},{"round":"Jeopardy!","air_date":"2008-05-29T00:00:00Z","category":"LITERARY
LOCALES","_yz_id":"1*default*jeopardy_bucket*show_70838*45","_yz_rk":"show_70838","_yz_rt":"default","_yz_rb":"jeopardy_bucke
t"}]}}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-24-320.jpg)
![Ces fragments peuvent être listés ainsi :
25
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,10213},{status,[]}]
Status:
{vnodeid,<<191,0,161,239,224,222,129,194>>}
Status:
{counter,20213}
Status:
{counter_lease,30000}
Status:
{counter_lease_size,10000}
Status:
{counter_leasing,false}
VNode: 22835963083295358096932575511191922182123945984
Backend: riak_kv_bitcask_backend
Status:
[{key_count,10174},{status,[]}]
Status:
{vnodeid,<<191,0,161,239,224,222,130,8>>}
Status:
{counter,20174}
Status:
{counter_lease,30000}
Status:
{counter_lease_size,10000}
Status:
{counter_leasing,false}
.
.
.
VNode: 1438665674247607560106752257205091097473808596992
Backend: riak_kv_bitcask_backend
Status:
[{key_count,10227},{status,[]}]
Status:
{vnodeid,<<191,0,161,239,226,126,207,204>>}
Status:
{counter,10227}
Status:
{counter_lease,20000}
Status:
{counter_lease_size,10000}
Status:
{counter_leasing,false}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-25-320.jpg)

![Ce système n’est pas cependant exempt de toute erreur. En effet, il est tout à fait possible d’imaginer qu’une
erreur puisse empêcher la mise à jour des hashtrees et que ceux-ci restent donc identiques, quelles que
soient les opérations faites sur la base de données. C’est pour cela que les hashtrees n’ont pas une durée de
vie illimitée ; Riak KV considère qu’au bout d’une semaine, il est nécessaire de détruire les deux arbres et de
les reconstruire entièrement afn de pouvoir les comparer à nouveau.
Testons maintenant la reconstruction d’une valeur présente dans l’index après une erreur de
synchronisation. Pour ce faire, nous couperons le service Riak Search, mettrons à jour un document dans le
Bucket « jeopardy_bucket »puis relancerons Riak Search.
Nous travaillerons ici avec le document d’id « show_4680 ».
Voici ce qui est stocké dans l’index pour ce document :
(vous remarquerez ici l’utilisation de _yz_rk qui est un champs ajouté automatiquement indexant la clé Riak
KV par Riak Search.)
27
Illustration 5: Schéma représentant le fonctionnement de l'AAE
Hashtree Riak Search
Hash racine
Partition 22835963083295358096932575511191922182123945984
Hash racine
Hash Document 1 Hash Document 2
...
Hash Clé 1
Hash Document 1 Hash Document 2
...
"air_date": "2003-06-06" answer": "Jolly Rancher" "category": "CANDY"
Hash Clé 2 Hash Clé 3
... ... ...
# curl -XGET "http://localhost:8098/search/queer/jeopardy_index?wt=json&q=_yz_rk:show_4680"
{"responseHeader":{"status":0,"QTime":15,"params":{"q":"_yz_rk:show_4680","shards":"172.17.0.2:8093/internal_solr/
jeopardy_index","172.17.0.2:8093":"_yz_pn:64 OR (_yz_pn:61 AND (_yz_fpn:61)) OR _yz_pn:60 OR _yz_pn:57 OR _yz_pn:54 OR
_yz_pn:51 OR _yz_pn:48 OR _yz_pn:45 OR _yz_pn:42 OR _yz_pn:39 OR _yz_pn:36 OR _yz_pn:33 OR _yz_pn:30 OR _yz_pn:27 OR
_yz_pn:24 OR _yz_pn:21 OR _yz_pn:18 OR _yz_pn:15 OR _yz_pn:12 OR _yz_pn:9 OR _yz_pn:6 OR _yz_pn:3","wt":"json"}},"response":
{"numFound":1,"start":0,"maxScore":12.999648,"docs":[{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4680*64","_yz_rk":"show_4680","_yz_rt":"default","_yz_rb":"jeopardy_bucket"}]}}
Hashtree Riak KV](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-27-320.jpg)
![Coupons maintenant Riak Search :
On redémarre le serveur.
Nous n’avons plus accès à l’index. Regardons le document stocké dans Riak KV :
Mettons à jour ce document en modifant la valeur de la clé category :
Relançons maintenant Riak Search :
On redémarre le serveur.
Pour le moment l’index n’a pas encore été mis à jour. Les deux hashtrees sont donc différents.
Au bout de quelques instants, l’AAE se rend compte de la différence entre la donnée présente dans le
Bucket et celle qui est indexée :
Suite à cette réparation, l’index a bien été mis à jour :
28
#sed -i -- 's/search = on/search = off/g' /etc/riak/riak.conf
#curl -XGET "http://localhost:8098/types/default/buckets/jeopardy_bucket/keys/show_4680"
{"category":"ALL MY SONS","air_date":"2008-03-13T00:00:00Z","question":"Gutzon Borglum died in 1941 so his son, Lincoln, fnished
sculpting the 4 fgures of this memorial","value":"$200","answer":"Mount Rushmore","round":"Jeopardy!","show_number":5419}
#curl -XPOST http://localhost:8098/types/default/buckets/jeopardy_bucket/keys/show_4680 -H "Content-Type: application/json" -d
'{"category":"TEST RIAK SEARCH","air_date":"2008-03-13T00:00:00Z","question":"Gutzon Borglum died in 1941 so his son, Lincoln,
fnished sculpting the 4 fgures of this memorial","value":"$200","answer":"Mount
Rushmore","round":"Jeopardy!","show_number":5419}'
#curl -XGET "http://localhost:8098/types/default/buckets/jeopardy_bucket/keys/show_4680"
{"category":"TEST RIAK SEARCH","air_date":"2008-03-13T00:00:00Z","question":"Gutzon Borglum died in 1941 so his son, Lincoln,
fnished sculpting the 4 fgures of this memorial","value":"$200","answer":"Mount
Rushmore","round":"Jeopardy!","show_number":5419}
#sed -i -- 's/search = off/search = on/g' /etc/riak/riak.conf
#curl -XGET "http://localhost:8098/search/query/jeopardy_index?wt=json&q=_yz_rk:show_4680"
{"responseHeader":{"status":0,"QTime":37,"params":{"q":"_yz_rk:show_4680","shards":"172.17.0.2:8093/internal_solr/
jeopardy_index","172.17.0.2:8093":"_yz_pn:64 OR (_yz_pn:61 AND (_yz_fpn:61)) OR _yz_pn:60 OR _yz_pn:57 OR _yz_pn:54 OR
_yz_pn:51 OR _yz_pn:48 OR _yz_pn:45 OR _yz_pn:42 OR _yz_pn:39 OR _yz_pn:36 OR _yz_pn:33 OR _yz_pn:30 OR _yz_pn:27 OR
_yz_pn:24 OR _yz_pn:21 OR _yz_pn:18 OR _yz_pn:15 OR _yz_pn:12 OR _yz_pn:9 OR _yz_pn:6 OR _yz_pn:3","wt":"json"}},"response":
{"numFound":1,"start":0,"maxScore":12.999648,"docs":[{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"ALL MY
SONS","_yz_id":"1*default*jeopardy_bucket*show_4680*64","_yz_rk":"show_4680","_yz_rt":"default","_yz_rb":"jeopardy_bucket"}]}}
[info] <0.19507.0>@yz_exchange_fsm:key_exchange:209 Will delete 0 keys and repair 1 keys of partition
1415829711164312202009819681693899175291684651008 for prefist
{1415829711164312202009819681693899175291684651008
#curl -XGET "http://localhost:8098/search/query/jeopardy_index?wt=json&q=_yz_rk:show_4680"
{"responseHeader":{"status":0,"QTime":14,"params":{"q":"_yz_rk:show_4680","shards":"172.17.0.2:8093/internal_solr/
jeopardy_index","172.17.0.2:8093":"(_yz_pn:62 AND (_yz_fpn:62)) OR _yz_pn:61 OR _yz_pn:58 OR _yz_pn:55 OR _yz_pn:52 OR
_yz_pn:49 OR _yz_pn:46 OR _yz_pn:43 OR _yz_pn:40 OR _yz_pn:37 OR _yz_pn:34 OR _yz_pn:31 OR _yz_pn:28 OR _yz_pn:25 OR
_yz_pn:22 OR _yz_pn:19 OR _yz_pn:16 OR _yz_pn:13 OR _yz_pn:10 OR _yz_pn:7 OR _yz_pn:4 OR _yz_pn:1","wt":"json"}},"response":
{"numFound":1,"start":0,"maxScore":12.452759,"docs":[{"round":"Jeopardy!","air_date":"2008-03-13T00:00:00Z","category":"TEST RIAK
SEARCH","_yz_id":"1*default*jeopardy_bucket*show_4680*1","_yz_rk":"show_4680","_yz_rt":"default","_yz_rb":"jeopardy_bucket"}]}}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-28-320.jpg)

![que nous souhaitons indexer. Par exemple, voici comment nous pourrions créer des 2I pour un document
de notre collection :
Nous alimentons ici deux index « category_bin » et « show_number_int » avec des valeurs que nous avons
nous même spécifées : elles n’ont pas été extraites du document. Modifons notre script d’insertion en
masse afn que chaque donnée de notre collection soit indexée ainsi.
Seule une partie de la collection suffsante pour les exemples suivants a été insérée.
Que pouvons nous faire ?
Rechercher les documents dont la category est « HISTORY » :
Remarquez que ce type d’index ne fait rien d’autre que de retourner la liste des identifants des documents
correspondants à notre requête.
Il est aussi possible de rechercher entre deux bornes, ici entre 1000 et 3000 :
(le numéro de show du document ne correspond pas au numéro d’id « show_x » entré par le script
30
#curl -v -X PUT http://localhost:8098/types/default/buckets/jeopardy_bucket_2I/keys/show_1
-H "Content-Type: application/json"
-H "x-riak-index-category_bin : CANDY"
-H "x-riak-index-show_number_int : 4335"
-d ‘{
"air_date": "2003-06-06",
"answer": "Jolly Rancher",
"category": "CANDY",
"question": "Bill Harmsen, who raised horses in Colo., happily founded this candy co. in 1949 to make money during the winter",
"round": "Final Jeopardy!",
"show_number": 4335,
"value": null
}’
#!/bin/bash
json_fle=$(cat jeopardy.json.format);
type="leveldb_backend"
bucket="jeopardy_bucket_2I"
i=0;
for data in $(echo "${json_fle}" | jq -r '.[] | @base64'); do
((i++));
_jq() {
echo ${data} | base64 --decode;
}
json_item="'"$(_jq)"'";
category=$(echo $json_item | grep -o -P '(?<="category":).*?(?=,)')
show_number=$(echo $json_item | grep -o -P '(?<="show_number":)[0-9]*')
insert_command=`echo curl -v -X PUT http://localhost:8098/types/$type/buckets/$bucket/keys/show_$i -H "’"Content-Type:
application/json"’" -H "’"x-riak-index-category_bin: $category"’" -H "’"x-riak-index-show_number_int: $show_number"’" -d $json_item`;
eval $insert_command;
done;
#curl -XGET http://localhost:32768/buckets/jeopardy_2I_bucket4/index/category_bin/HISTORY
{"keys":["show_417","show_25","show_405","show_7","show_393","show_19","show_1","show_399","show_13","show_411"]}
#curl -XGET http://localhost:32768/buckets/jeopardy_2I_bucket4/index/show_number_int/1000/3000
{"keys":
["show_2","show_393","show_9","show_417","show_399","show_542","show_6","show_522","show_744","show_125""show_630","sh
ow_25","show_405"...}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-30-320.jpg)



![- Enfn, une méthode intéressante et essentielle au système Dynamo est celle des « Vector Clocks ». Celle-ci
permet de gérer les mises à jours concurrentes d’une même donnée par deux clients simultanément. Un
système classique ne se souciera pas vraiment de cette mise à jour concurrente et stockera soit les deux
versions différentes en laissant le client choisir, soit considérera que le dernier document mis à jour est le
document fnal. Les « Vectors Clocks » permettent d’éviter ce genre de situation dans la mesure du possible.
Le principe est assez simple à comprendre mais plutôt complexe à expliciter, c’est pourquoi j’utiliserai un
exemple.
Voici un scénario simple :
Le schéma précédent montre les modifcation faites simultanément par deux clients sur un seul document.
Connaître le document à stocker en base est simple dans certains cas, plus complexes dans d’autres. A
chaque élément du document est associé un « vector clock », indiquant sa version dans le temps; lors d’une
mise à jour d’une valeur, cette version est mise à jour.
A l’unité de temps 1, chaque client a modifé une valeur de clé différente dans le document. On déduit alors
de façon assez intuitive que le document stocké en base devra être une fusion de ces deux modifcations :
35
0
{
"clé_un: "valeur_1_1",
"clé_deux": "valeur_2_1"
}
{
"clé_un: "valeur_1_2",
"clé_deux": "valeur_2_1"
}
Donnée en base
Modifcation client 1
Modifcation client 2
1
Modifcation client 2
2
Modifcation client 1
{
"clé_un: "valeur_1_1",
"clé_deux": "valeur_2_2"
}
{
"clé_un: "valeur_1_3",
"clé_deux": "valeur_2_3"
}
{
"clé_un: "valeur_1_4",
"clé_deux": "valeur_2_3"
}
{
"clé_un: ["valeur_1_2","valeur_1_2"],
"clé_deux": ["valeur_2_1","valeur_2_2"]
}
Axetemporel](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-35-320.jpg)
![Les deux mises à jour sont satisfaites.
A l’unité de temps 2, les deux clients ont modifé de la même façon la valeur de la deuxième clé du
document ; cette dernière doit donc prendre la nouvelle valeur :
Comme précédemment, ils ont tous deux mis à jour une même clé en même temps mais une valeur
différente. On ne peut pas choisir arbitrairement de privilégier le client 1 ou le client 2, le document stocké
en base sera alors :
On voit ici l’effcacité de cette méthode. Les documents ne sont pas simplement vus comme des objets
physiques fgés avec une version temporelle fxée, ils sont interprétés comme des objets logiques avec
plusieurs attributs pouvant être mis à jour simultanément. Cette méthode permet de résoudre de nombreux
confits mais on constate assez facilement qu’elle n’est pas parfaite. Elle permet cependant la gestion des
mises à jour concurrentes de clé modifée de façon similaire et laisse le choix entre les différentes valeurs
entrées pour une même clé. Attention, comme nous le verrons dans la phase pratique en fn de rapport, les
Vector Clocks ne sont qu’une gestion de timestamp associé aux données insérées et non une méthode de
« merge » de ces données.
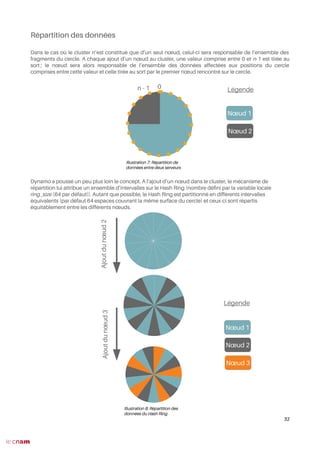
Mise en place d’un cluster Riak KV
Passons maintenant à la pratique et mettons en place notre propre cluster Riak KV. Pour ce rapport, un
cluster composé de cinq nodes sera mis en place.
Construction du cluster et commandes de base
Voici l’architecture de notre cluster :
Nœud 2
36
{
…,
"clé_deux": "valeur_2_3"
}
{
"clé_un: ["valeur_1_3 ", " valeur_1_4 "],
"clé_deux": "valeur_2_3"
}
Riak-kv-5
172.17.0.6
Riak-kv-3
172.17.0.4
Riak-kv-2
172.17.0.3
Riak-kv-4
172.17.0.5
Riak-kv
172.17.0.2
Routeur
172.17.0.1](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-36-320.jpg)

![Détail des commandes :
- riak-admin cluster join [node] permet à une node de joindre le cluster de la node passée en argument. Il est
aussi possible d’indiquer qu’une node doit remplacer une node déjà existante dans le cluster grâce à la
commande riak-admin cluster replace [node_à_remplacer] [nouvelle_node].
- riak-admin cluster plan permet de visualiser les actions prévues sur le cluster et les modifcations qu’elles
engendreront. On voit ici que quatre nouveaux serveurs veulent rejoindre le cluster ; la répartition des
données et aussi détaillée. Ce « plan d’exécution » peut être remis à zéro grâce à la commande riak-admin
cluster clear.
- riak-admin cluster commit ne peut s’exécuter qu’après la commande précédente. Cette commande valide
et applique les actions prévues vues précédemment.
Dans l’interface Web d’administration de chacune des nodes, les membres du cluster sont visibles :
Visualisons le statut de notre cluster (à partir de n’importe lequel des nœuds) :
38
Illustration 11: Visualtion du Cluster depuis l'interface Web
# riak-admin cluster status
---- Cluster Status ----
Ring ready: true
+----------------------------------+----------+--------+-------+-------------+
| node | status | avail | ring |pending |
+----------------------------------+----------+--------+-------+-------------+
| (C) riak@172.17.0.2 | valid | up | 20.3| -- |
| riak@172.17.0.3 | valid | up | 20.3| -- |
| riak@172.17.0.4 | valid | up | 20.3| -- |
| riak@172.17.0.5 | valid | up | 20.3| -- |
| riak@172.17.0.6 | valid | up | 18.8| -- |
+----------------------------------+----------+-------+-------+---------------+
Key: (C) = Claimant; availability marked with '!' is unexpected](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-38-320.jpg)

![Essayons maintenant d’ajouter un nouveau serveur riak-kv-6 au cluster :
Demandons donc à un autre membre du cluster de nous y ajouter :
Nous constatons ici que riak-kv-3 est aussi en mesure d’ajouter une node au cluster. Voici le nouveau statut
de notre cluster :
Cependant l’ajout n’est pas complet. En effet, rappelons que le statut « joining » indique seulement que
cette nouvelle node est prête à rejoindre le cluster. Riak-kv-3 peut-elle prendre en charge l’ajout de cette
node dans le cluster et la répartition des données ?
Et bien non ! C’est ici qu’on constate le rôle de la « node claimant » ; elle est la seule à pouvoir modifer le
cluster. Il s’agit donc d’une node d’administration essentielle lorsque l’on veut mettre en place un cluster
Riak KV. Son accès doit être limité à un administrateur qui sait ce qu’il fait car c’est à partir d’elle et d’elle
seule que les actions impactantes sur le cluster peuvent être entreprises.
40
# riak-admin cluster join riak@172.17.0.2
Node riak@172.17.0.2 is not reachable!
# riak-admin cluster join riak@172.17.0.4
Success: staged join request for 'riak@172.17.0.7' to 'riak@172.17.0.4'
# riak-admin cluster status
---- Cluster Status ----
Ring ready: true
+----------------------------------+----------+---------------+-------+-------------+
| node | status | avail | ring |pending |
+----------------------------------+----------+---------------+-------+-------------+
| riak@172.17.0.7 | joining | up | 0.0 | |
|(C) riak@172.17.0.2 | valid | down ! | 20.3| -- |
| riak@172.17.0.3 | valid | down ! | 20.3| -- |
| riak@172.17.0.4 | valid | up | 20.3| -- |
| riak@172.17.0.5 | valid | up | 20.3| -- |
| riak@172.17.0.6 | valid | up | 18.8| -- |
+----------------------------------+----------+--------------+-------+---------------+
Key: (C) = Claimant; availability marked with '!' is unexpected
# riak-admin cluster plan
RPC to 'riak@172.17.0.4' failed: {'EXIT',
{{nodedown,'riak@172.17.0.2'},
{gen_server,call,
[{riak_core_claimant,'riak@172.17.0.2'},
plan,infnity]}}}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-40-320.jpg)


![Expérimentations sur notre cluster
Nous allons dans cette partie réaliser plusieurs tests en vue de vérifer et de comprendre les
différents paramètres d’un cluster Riak KV et ce qu’ils impliquent. Le cluster sera composé des cinq mêmes
serveurs que ceux vus précédemment et l’anneau sera découpé en 8 fragments :
(commande exécutée sur chaque nœud)
La répartition des fragments est visible au niveau de la ligne « ring_ownership » :
- 2 fragments sont gérés par les nodes riak-kv, riak-kv-2 et riak-kv-3
- 1 fragment est géré par les nodes riak-kv-4 et riak-kv-5
L’intégralité des données de notre collection « jeopardy » a été chargée dans un Bucket
« jeopardy_bucket » de type « jeopardy_bucket_type ». Pour le moment, aucune réplication n’est
demandée pour les données de ce Bucket. Dans la suite de cette partie, l’ensemble des modifcations de
paramètres appliquées au Bucket Type « jeopardy_bucket_type » se fera via l’interface web afn de faciliter
la lecture de ceux-ci (et pour un soucis de facilité de mise en place !).
Voici comment ont été réparties les données entre les différentes vnodes (nombre indiqué au niveau du
key_count):
46
# sed -i -- 's/## ring_size = 64/ring_size = 8/g' /etc/riak/riak.conf
# riak-admin status | grep ring
ring_creation_size : 8
ring_members : ['riak@172.17.0.2','riak@172.17.0.3','riak@172.17.0.4','riak@172.17.0.5','riak@172.17.0.6']
ring_num_partitions : 8
ring_ownership : <<"[{'riak@172.17.0.2',2},n {'riak@172.17.0.3',2},n {'riak@172.17.0.4',2},n {'riak@172.17.0.5',1},n{'riak@172.17.0.6',1}]">>
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,27337},{status,[]}]
VNode: 913438523331814323877303020447...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,27132},{status,[]}]
riak-kv
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,27342},{status,[]}]
Vnode: 109612622799817718865276362453...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,27125},{status,[]}]
riak-kv-2
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,27232},{status,[]}]
VNode: 127881393266454005342822422422...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,27249},{status,[]}]
riak-kv-3
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 548063113999088594326381812268...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,26991},{status,[]}]
riak-kv-4
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 730750818665451459101842416358...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,26903},{status,[]}]
riak-kv-5](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-46-320.jpg)
![Ce qui, sous forme de graphe, pourrait être représenté ainsi :
On constate bien ici la puissance du Hash Ring : les données ont été également réparties entre les
différentes vnodes.
Nous pouvons observer la méthode utilisée par Riak KV pour répartir chaque donnée sus le nœud virtuel
responsable de son stockage ; pour cela, nous avons besoin du client Erlang qui est capable d’exécuter les
bibliothèques internes au produit Riak KV.
Afn d’entrer dans l’interpréteur de commande Erlang, il est nécessaire de passer cette commande shell sur
n’importe quel nœud :
Nous voilà dans l’interpréteur de commandes Erlang.
Dans la première variable « Hash », nous indiquons à Erlang de stocker la valeur de hashage résultant de la
concaténation du nom du Bucket et de la clé du document. Ensuite, en fonction de cette valeur de hashage,
on interroge le Hash Ring afn de connaître la liste de préférence des vnodes chargées de stocker cette
donnée. Aucun problème n’a eu lieu lors de l’insertion, la donnée a donc dû se retrouver stockée dans la
vnode du serveur riak-kv-3 (127.17.0.4). Nous n’avons ici qu’une seule node primaire (pas de réplication),
mais le processus d’insertion est dans tous les cas :
47
Illustration 12: Répartition des données dans
notre Cluster
riak-kv
riak-kv
riak-kv-2
riak-kv-2
riak-kv-3
riak-kv-3
riak-kv-4
riak-kv-5
# riak attach
(riak@172.17.0.2)1> Hash = riak_core_util:chash_key({<<"jeopardy_bucket">>, <<"show_1">>}).
<<211,199,82,186,199,192,224,69,33,134,234,19,67,138,222, 23,191,153,67,72>>
(riak@172.17.0.2)2> Preference_list = riak_core_ring:prefist(Hash, Ring).
[{1278813932664540053428224228626747642198940975104,
'riak@172.17.0.4'},
{0,'riak@172.17.0.2'},
{182687704666362864775460604089535377456991567872,
'riak@172.17.0.3'},
{365375409332725729550921208179070754913983135744,
'riak@172.17.0.4'},
{548063113999088594326381812268606132370974703616,
'riak@172.17.0.5'},
{730750818665451459101842416358141509827966271488,
'riak@172.17.0.6'},
{913438523331814323877303020447676887284957839360,
'riak@172.17.0.2'},
{1096126227998177188652763624537212264741949407232,
'riak@172.17.0.3'}]](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-47-320.jpg)
![Observons maintenant le nombre de données stocké sur chaque nœud :
A vue d’œil, on constate donc bien que chaque vnode stocke environ trois fois plus de données qu’avant,
ses propres données ainsi que les données répliquées. Où est désormais stockée notre donnée ayant pour
id « show_1 » ?
$
A vue d’œil, on constate donc bien que chaque vnode stocke environ trois fois plus de données qu’avant,
ses propres données ainsi que les données répliquées. Où est désormais stockée notre donnée ayant pour
id « show_1 » ?
Elles sont présentes sur les n_val premiers serveurs de la liste de préférence soit riak-kv-3, riak-kv et riak-kv-2.
La commande :
renvoie bien le contenu la donnée tant qu’un des trois serveurs est en accessible. Cependant, dès que les
trois serveurs sont hors lignes, un « not found » est émis. (ici on interroge le serveur riak-kv-5)
49
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,72507},{status,[]}]
VNode: 913438523331814323877303020447...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,80824},{status,[]}]
riak-kv
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,81928},{status,[]}]
Vnode: 109612622799817718865276362453...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,81085},{status,[]}]
riak-kv-2
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 0
Backend: riak_kv_bitcask_backend
Status:
[{key_count,81859},{status,[]}]
VNode: 127881393266454005342822422422...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,81506},{status,[]}]
riak-kv-3
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 548063113999088594326381812268...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,81386},{status,[]}]
riak-kv-4
# riak-admin vnode-status
Vnode status information
-------------------------------------------
VNode: 730750818665451459101842416358...
Backend: riak_kv_bitcask_backend
Status:
[{key_count,80872},{status,[]}]
riak-kv-5
(riak@172.17.0.2)1> Hash = riak_core_util:chash_key({<<"jeopardy_bucket">>, <<"show_1">>}).
<<211,199,82,186,199,192,224,69,33,134,234,19,67,138,222, 23,191,153,67,72>>
(riak@172.17.0.2)2> Preference_list = riak_core_ring:prefist(Hash, Ring).
[[{1278813932664540053428224228626747642198940975104,
'riak@172.17.0.4'},
{0,'riak@172.17.0.2'},
{182687704666362864775460604089535377456991567872,
'riak@172.17.0.3'},
{365375409332725729550921208179070754913983135744,
'riak@172.17.0.4'},
{548063113999088594326381812268606132370974703616,
'riak@172.17.0.5'},
{730750818665451459101842416358141509827966271488,
'riak@172.17.0.6'},
{913438523331814323877303020447676887284957839360,
'riak@172.17.0.2'},
{1096126227998177188652763624537212264741949407232,
'riak@172.17.0.3'}]
# curl -v -XGET http://172.17.0.6:8098/types/jeopardy_bucket_type/buckets/jeopardy_bucket/keys/show_1](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-49-320.jpg)
![Testons maintenant l’effcacité des serveurs secondaires lors de l’écriture d’une donnée pour laquelle les
serveurs cibles primaires sont inaccessibles, puis d’une lecture. Pour ce faire, nous testerons tout d’abord
avec des valeurs de PR et de PW à 3 (l’insertion et la lecture ne pourront se faire que si tous les serveurs
primaires sont accessibles), puis nous remettrons ces valeurs à 0 (l’écriture sera acceptée même si aucun
serveur primaire n’est accessible ; il en va de même pour la lecture de cette donnée). Nous allons essayer
d’insérer une donnée pour un document d’id « show_999999 ». Récupérons tout d’abord la liste des
serveurs primaires afn de les désactiver au moment de l’écriture de la donnée :
Les trois serveurs primaires responsables du stockage de cette donnée sera donc les trois premiers serveurs
de la liste : riak-kv-5, riak-kv et riak-kv-2. Éteignons les.
Actuellement, nous exigeons que les serveurs primaires soient accessibles afn d’écrire une donnée :
Essayons maintenant d’insérer une donnée depuis le serveur riak-kv-3 :
50
(riak@172.17.0.2)1> Hash = riak_core_util:chash_key({<<"jeopardy_bucket">>, <<"show_999999">>}).
<<211,199,82,186,199,192,224,69,33,134,234,19,67,138,222, 23,191,153,67,72>>
(riak@172.17.0.2)2> Preference_list = riak_core_ring:prefist(Hash, Ring).
[{730750818665451459101842416358141509827966271488,
'riak@172.17.0.6'},
{913438523331814323877303020447676887284957839360,
'riak@172.17.0.2'},
{1096126227998177188652763624537212264741949407232,
'riak@172.17.0.3'},
{1278813932664540053428224228626747642198940975104,
'riak@172.17.0.4'},
{0,'riak@172.17.0.2'},
{182687704666362864775460604089535377456991567872,
'riak@172.17.0.3'},
{365375409332725729550921208179070754913983135744,
'riak@172.17.0.4'},
{548063113999088594326381812268606132370974703616,
'riak@172.17.0.5'}]
curl -v -X PUT http://172.17.0.4:8098/types/jeoprady_bucket_type/buckets/jeopardy_bucket/keys/show_999999 -H "Content-Type:
application/json" -d ‘{
"air_date": "2003-06-06",
"answer": "Jolly Rancher",
"category": "CANDY",
"question": "Bill Harmsen, who raised horses in Colo., happily founded this candy co. in 1949 to make money during the winter",
"round": "Final Jeopardy!",
"show_number": 4335,
"value": null
}’](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-50-320.jpg)

![Une deuxième classe permet de redéfnir la fonction resolve de la classe ConfictResolver fournie par l’API.
C’est elle qui se chargera d’effectuer les différents traitements détaillés ci-dessous dès qu’un confit
(plusieurs siblings ) sera détecté :
54
public static class Vclock_exampleConfictResolver implements ConfictResolver<Vclock_example> {
@Override
public Vclock_example resolve(List<Vclock_example> siblings) {
//Objet Vclock_example
Vclock_example resolved_vclock_example = new Vclock_example();
String clé_un, clé_deux;
//Liste sans doublons contenant les différentes valeurs de clé_un
Set<String> clé_un_set = new HashSet<>();
//Liste sans doublons contenant les différentes valeurs de clé_deux
Set<String> clé_deux_set = new HashSet<>();
//S'il n'y a pas de confit
if (siblings.size() == 0) {
return null;
}
//S'il n'y a qu'une seule valeur du document
else if (siblings.size() == 1) {
return siblings.get(0);
}
//Si nous avons plusieurs versions confictuelles
else {
//Pour chaque version du document
for (Vclock_example vclock_example : siblings) {
//On ajoute la valeur de clé_un à la liste
clé_un_set.add(vclock_example.getClé_un());
//On ajoute la valeur de clé_deux à la liste
clé_deux_set.add(vclock_example.getClé_deux());
}
//Si la liste contenant les différentes valeurs de clé_un ne contient qu'un élément
if (clé_un_set.size() <= 1) {
clé_un = """ + clé_un_set.toString().replaceAll("[[]]", "") + """;
//On stocke la valeur de clé_un dans notre objet
resolved_vclock_example.setClé_un(clé_un);
} else {
clé_un = "["" + clé_un_set.toString().replaceAll("[[]]", "").replace(", ", "","") + ""]";
//On stocke un tableau des valeurs de clé_un dans notre objet
resolved_vclock_example.setClé_un(clé_un);
}
//Même traitement que clé_un
if (clé_deux_set.size() <= 1) {
clé_deux = """ + clé_deux_set.toString().replaceAll("[[]]", "") + """;
resolved_vclock_example.setClé_deux(clé_deux);
} else {
clé_deux = "["" + clé_deux_set.toString().replaceAll("[[]]", "").replace(", ", "","")
+ ""]";
resolved_vclock_example.setClé_deux(clé_deux);
}
//On retourne l'objet
return resolved_vclock_example;
}
}
}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-54-320.jpg)
![Enfn, au niveau de notre classe principale Main, nous vérifons à la lecture d’une donnée si celle-ci possède
plusieurs versions confictuelles ; si tel est le cas alors nous appellerons la méthode précédemment défnie
et nous mettrons à jour la valeur de notre document.
Après exécution de ce code, nous constatons que le document interrogé a maintenant été mis à jour et
prend en compte l’ensemble des modifcations de client 1 et client 2 :
Les Vector Clocks n’ont donc rien de « magique ». Ils sont cependant à la fois simple à comprendre et
peuvent être extrêmement complexes à exploiter en fonction des cas de fgure.
Riak KV offre la possibilité de paramétrer la gestion des siblings ; en effet, dans notre cas il était assez simple
de décider de ce que nous devions faire de nos différentes données, mais qu’aurions nous fait si nous
avions reçu des centaines de versions confictuelles du même document ? Insérer un tel tableau dans le
document fnal n’aurait aucun sens (dans cet exemple en tout cas). De plus, de quand est datée la première
version en confit ? Est-elle toujours pertinente ou une des versions postérieure l’est-elle désormais
55
// Initialisation du client
RiakCluster cluster = setUpCluster();
RiakClient client = new RiakClient(cluster);
ConfictResolverFactory crf = ConfictResolverFactory.getInstance();
crf.registerConfictResolver(Vclock_example.class, new Vclock_exampleConfictResolver());
// Lecture de la donnée
Location vclocks_test_values_confict_data = new Location(
new Namespace("jeopardy_bucket_type", "jeopardy_bucket"), "vclocks_values_confict");
FetchValue fetch = new FetchValue.Builder(vclocks_test_values_confict_data).build();
FetchValue.Response res = client.execute(fetch);
//Récupération du Vector Clock
VClock current_vclock = res.getVectorClock();
System.out.println(current_vclock.toString());
RiakObject obj;
try {
obj = res.getValue(RiakObject.class);
}
// Plusieurs versions du document sont en confit
catch (com.basho.riak.client.api.cap.UnresolvedConfictException exception) {
//On applique la résolution de problème défnie dans la fonction resolve
Vclock_example vlock_fnal_value = res.getValue(Vclock_example.class);
// On transmet à Riak KV la nouvelle version du document
String vlock_fnal_value_string = "{"cle_un":" + vlock_fnal_value.getClé_un() + ","cle_deux":"
+ vlock_fnal_value.getClé_deux() + "}";
StoreValue sv = new StoreValue.Builder(vlock_fnal_value_string)
.withLocation(vclocks_test_values_confict_data).withVectorClock(current_vclock).build();
client.execute(sv);
}
client.shutdown();
System.exit(0);
#curl -i GET http://localhost:32904/types/jeopardy_bucket_type/buckets/jeopardy_bucket/keys/vclocks_values_confict
.
.
.
X-Riak-Vclock: a85hYGBgymDKBVI8+xkWvg9ne5HOwHjleAZTInMeK4NPcPUVPqj0CfaJlSm3/sYzMK7dDpRmBEqHgaSzAA==
.
.
.
{"clé_un":["valeur_1_1","valeur_1_2"],"clé_deux":["valeur_2_2","valeur_2_1"]}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-55-320.jpg)




![A ce stade, tous les serveurs du cluster sont éteints. On allume d’abord le serveur riak-kv-4:
Nous avons ajouté deux données à notre Set : « Donnee_1 » et « Donnee_2 » et avons supprimé la donnée
« George III ».
Nous éteignons riak-kv-4 et allumons riak-kv-2, de telle sorte qu’aucun échange de données ne puisse se
faire pour le moment.
Nous avons ici ajouté une donnée « George III » (aucun changement n’a été appliqué puisque cette donnée
existait déjà dans le Set et avons supprimé « 2004-05-10 ».
Laissons riak-kv-4 en ligne et rallumons riak-kv-2. Désormais, si nous interrogeons un des serveurs, voici ce
que nous obtenons :
Ici Riak KV applique la règle « Add Wins Over Remove » (les ajouts l’emportent sur les suppressions), c’est
pourquoi « George III » est toujours présent. Nous constatons de plus bien les autres suppressions et ajouts.
60
#curl -XGET http://172.17.0.5:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example₁
{"type":"set","value":["2004-05-10","George
III"],"context":"g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag=="}
#curl -XPOST http://172.17.0.5:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"add_all":["Donnee_1", "Donnee_2"], "context" :
"g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag==" }'
#curl -XPOST http://172.17.0.5:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"remove":"George III", "context" :
"g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag==" }'
#curl -XGET http://172.17.0.5:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example₁
{"type":"set","value":["2004-05-10","Donnee_1","Donnee_2"],
"context":"g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag=="}
#curl -XGET http://172.17.0.3:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example₁
{"type":"set","value":["2004-05-10","George
III"],"context":"g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag=="}
#curl -XPOST http://172.17.0.3:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"add":"George III", "context" : "g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag==" }'
#curl -XPOST http://172.17.0.3:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example_1
-H "Content-Type: application/json"
-d '{"remove":"2004-05-10", "context" :
"g2wAAAACaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBAACcQmEGag==" }'
#curl -XGET http://172.17.0.3:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example₁
{"type":"set","value":["George
III"],"context":"g2wAAAADaAJtAAAADL8Aoe9dU9CcAADeAGECaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBA
ACcQmEGag=="}
#curl -XGET http://172.17.0.2:8098/types/bucket_type_set/buckets/jeopady_question/datatypes/question_example₁
{"type":"set","value":["Donnee_1","Donnee_2","George
III"],"context":"g2wAAAAEaAJtAAAADL8Aoe9dU9CcAADeAGECaAJtAAAADL8Aoe9eM1MAAAB1MWEDaAJtAAAADL8Aoe9eM1MBA
ACcQmEGaAJtAAAADL8Aoe9eM1MCAAAAAmECag=="}](https://image.slidesharecdn.com/rapportriakkvvalentintraen-190417115634/85/Descriptif-du-SGBD-No-SQL-Riak-KV-60-320.jpg)






























