Télécharger en tant que PDF, PPTX






![Sucre syntaxique
`
on appelle sucre syntaxique une construction de la syntaxe concrete qui
n’existe pas dans la syntaxe abstraite
`
elle est donc traduite a l’aide d’autres constructions de la syntaxe abstraite
´ ´
`
(generalement a l’analyse syntaxique)
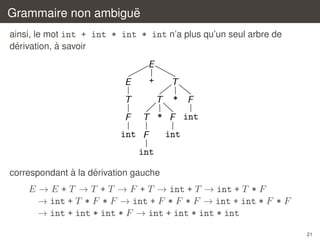
exemple : en Caml l’expression [e1 ; e2 ; ...; en ] est du sucre pour
e1 :: e2 :: ... :: en :: []
8](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-8-320.jpg)
















![Programmation d’un analyseur descendant
´
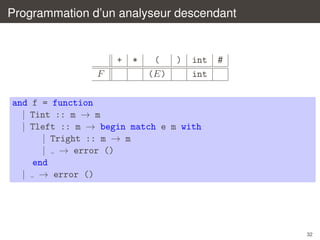
faisons le choix d’une programmation purement applicative, ou l’entree est
`
`
une liste de lexemes du type
type token = Tplus | Tmult | Tleft | Tright | Tint | Teof
on va donc construire cinq fonctions qui
val
val
val
val
val
consomment
´
la liste d’entree
e : token list → token list
e’ : token list → token list
t : token list → token list
t’ : token list → token list
f : token list → token list
´
et la reconnaissance d’une entree pourra alors se faire ainsi
let recognize l = e l = [Teof];;
29](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-29-320.jpg)












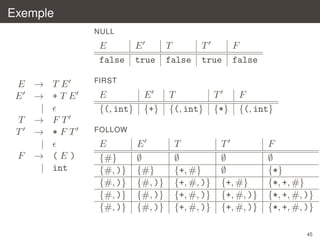












![Automate LR(0)
commencons par k = 0
¸
´
on construit un automate LR(0) non deterministe
´
dont les etats sont des items de la forme
[X → α • β]
ou X → αβ est une production de la grammaire ; l’intuition est :
`
`
´ `
cherche a reconnaˆtre X , j’ai deja lu α et je dois encore lire β
ı
je
´
´
et les transitions sont etiquetees par T ∪ N et sont les suivantes
a
[Y → α • aβ] → [Y → αa • β]
X
[Y → α • Xβ] → [Y → αX • β]
[Y → α • Xβ] → [X → •γ] pour toute production X → γ
58](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-58-320.jpg)
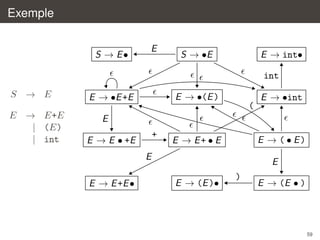

![Construction de la table
on construit ainsi la table action
`
action(s, #) = succes si [S → E • #] ∈ s
a
action(s, a) = shift s si on a une transition s → s
action(s, a) = reduce X → β si [X → β•] ∈ s, pour tout a
´
echec dans tous les autres cas
on construit ainsi la table goto
X
goto(s, X) = s si et seulement si on a une transition s → s
62](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-62-320.jpg)



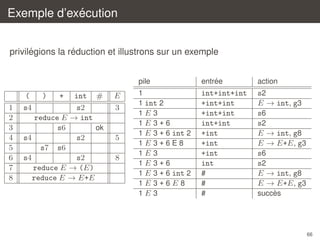
![Analyse SLR(1)
`
la construction LR(0) engendre tres facilement des conflits
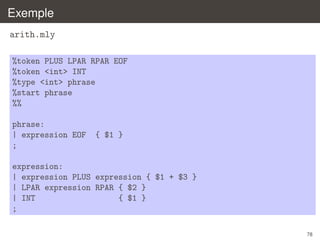
`
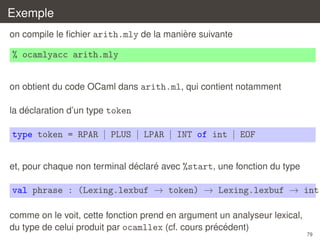
´
on va donc chercher a limiter les reductions
´
`
`
une idee tres simple consiste a poser action(s, a) = reduce X → β si et
seulement si
[X → β•] ∈ s et a ∈ FOLLOW(X)
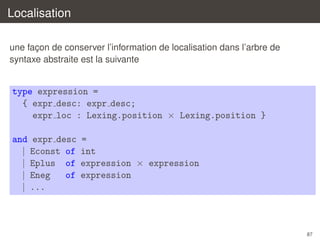
´
Definition (classe SLR(1))
Une grammaire est dite SLR(1) si la table ainsi construite ne contient pas
de conflit.
(SLR signifie Simple LR)
67](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-67-320.jpg)

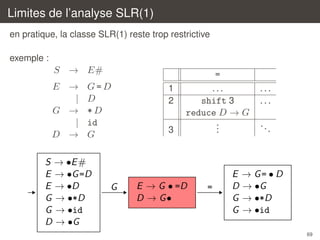
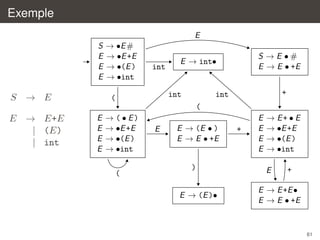
![Analyse LR(1)
on introduit une classe de grammaires encore plus large, LR(1), au prix de
tables encore plus grandes
dans l’analyse LR(1), les items ont maintenant la forme
[X → α • β, a]
`
´ `
dont la signification est : je cherche a reconnaˆtre X , j’ai deja lu α et je
ı
´
`
dois encore lire β puis verifier que le caractere suivant est a
70](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-70-320.jpg)
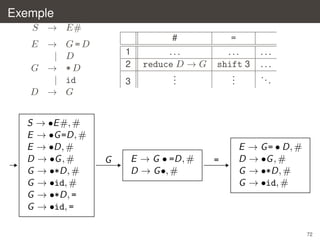
![Analyse LR(1)
´
les transitions de l’automate LR(1) non deterministe sont
a
[Y → α • aβ, b] → [Y → αa • β, b]
X
[Y → α • Xβ, b] → [Y → αX • β, b]
[Y → α • Xβ, b] → [X → •γ, c] pour tout c ∈
FIRST (βb)
´
l’etat initial est celui qui contient [S → •α, #]
´ ´
´
comme precedemment, on peut determiniser l’automate et construire la
´
table correspondante ; on introduit une action de reduction pour (s, a)
seulement lorsque s contient un item de la forme [X → α•, a]
´
Definition (classe LR(1))
Une grammaire est dite LR(1) si la table ainsi construite ne contient pas
de conflit.
71](https://image.slidesharecdn.com/c3-131230052541-phpapp02/85/Introduction-a-la-compilation-Analyse-Syntaxique-C3-71-320.jpg)













Ce document traite de l'introduction à la compilation, en se concentrant sur la syntaxe abstraite et l'analyse syntaxique. Il décrit le processus d'analyse lexicale, les structures de grammaire, et présente des concepts comme les arbres de dérivation et les grammaires ambigües. Enfin, des méthodes pour construire des analyseurs descendants sont abordées, ainsi que les notions de null, first et follow pour l'analyse syntaxique.














































