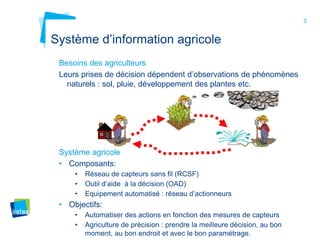
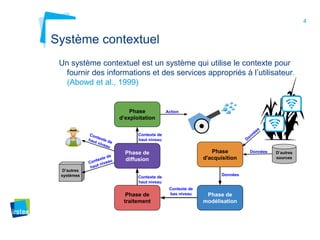
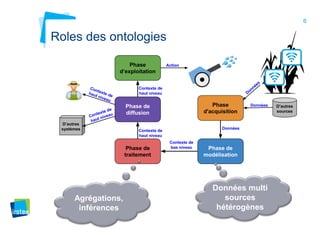
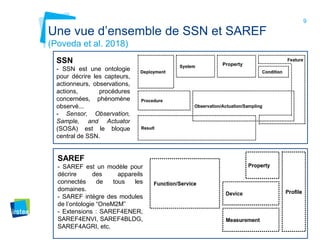
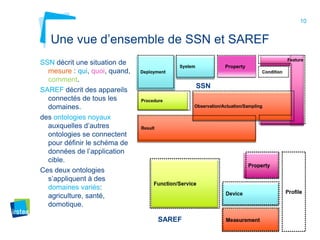
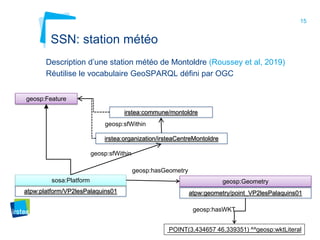
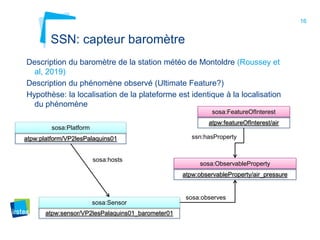
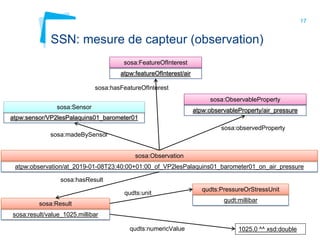
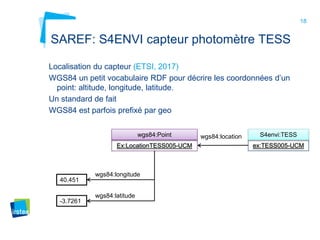
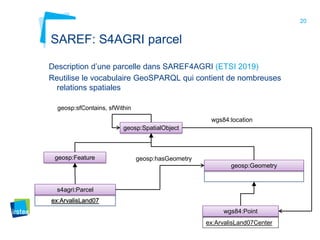
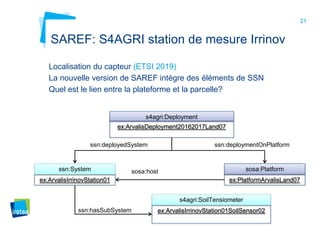
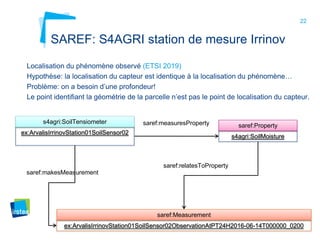
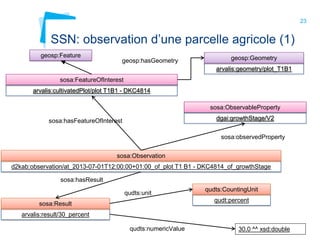
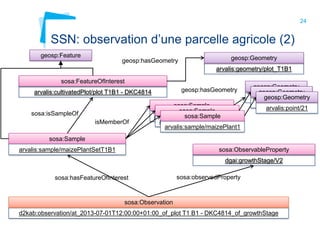
Ce document aborde la modélisation de la spatialité dans les ontologies des capteurs, avec un accent sur les applications agricoles et les systèmes d'information contextuels. Il décrit les différentes ontologies, y compris SSN et SAREF, ainsi que leur rôle dans l'intégration des données hétérogènes et la contextualisation des informations récoltées par les capteurs. Enfin, il souligne la nécessité de développer des pratiques cohérentes pour modéliser la spatialité en relation avec les observations agricoles.