Le document présente des métriques pour l'évaluation de l'annotation dans le traitement automatique des langues (TAL), mettant en avant l'importance des annotations pour garantir la qualité des données. Il examine différents aspects de l'annotation tels que la validité, la fiabilité, et les méthodes statistiques pour mesurer l'accord entre annotateurs. Enfin, il propose des formules et des coefficients pour quantifier cet accord, en tenant compte des variations et des probabilités des annotations.








![Coefficients pour l’accord
Nécessité d’une mesure du hasard
Les coefficients d’accord (Artstein & Peosio, 2008)
- forment une famille de métriques
- mesurent l’accord entre codeurs
- sont contraints dans un intervalle [-1,1]
accord = 1 accord parfait
accord = 0 aucun accord
accord = -1 désaccord parfait
Pourquoi les coefficients d’accord ?
Il existe d’autres métriques/tests.
- Accord observé
- Test d’hypothèse du χ2
- Coefficients de corrélation
Jean-Philippe Fauconnier
Métriques pour l’Annotation
9 / 71](https://image.slidesharecdn.com/annotation-131127043620-phpapp01/85/Metriques-pour-l-evaluation-de-l-Annotation-9-320.jpg)


![Coefficients pour l’accord
Nécessité d’une mesure du hasard : Accord observé
(Scott, 1955)
"[percentage agreement] is biased in favor of dimensions with a
small number of categories."
k1
k2
Total
k1
1/4
1/2
k2
1/4
1/2
k1
k2
k3
Total
k1
1/9
1/3
k2
1/9
1/3
k3
1/9
1/3
K =2
Total
1/2
1/2
1
Jean-Philippe Fauconnier
Par "chance" : 1/4 des i
dans chaque cellule
Ao = 1/2
Total
1/3
1/3
1/3
1
K =3
Par "chance" : 1/9 des i
dans chaque cellule
Ao = 1/3
Métriques pour l’Annotation
12 / 71](https://image.slidesharecdn.com/annotation-131127043620-phpapp01/85/Metriques-pour-l-evaluation-de-l-Annotation-12-320.jpg)



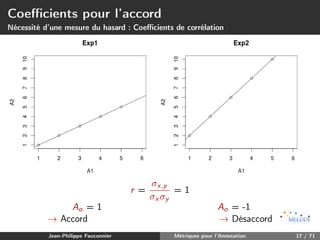
![Coefficients pour l’accord
Nécessité d’une mesure du hasard : Coefficients de corrélation
Coefficients de corrélation r et rs
- mesurent la corrélation entre une V.A X et Y
- prennent une valeur entre [-1,1]
- Cependant, mesurent l’existence d’une relation et non l’accord
Supposons l’exemple suivant :
- Deux expériences avec chacune 2 codeurs et 5 items
- À chaque item est attribué une valeur entre [1,5] (rating)
Item
a
b
c
d
e
Jean-Philippe Fauconnier
Exp1
A1 A2
1
1
2
2
3
3
4
4
5
5
Exp2
A1 A2
1
2
2
4
3
6
4
8
5
10
Métriques pour l’Annotation
16 / 71](https://image.slidesharecdn.com/annotation-131127043620-phpapp01/85/Metriques-pour-l-evaluation-de-l-Annotation-16-320.jpg)
































![Une approche holiste et unifiée
Alignement
Distinction entre alignement unitaire et alignement
.
- a = un alignement unitaire entre deux unités
- ¯ = un ensemble d’alignements unitaires pour un jeu d’annotation
a
Alignement unitaire
.
- a, un n-uplet, avec n compris dans l’intervalle [1, C ]
.
- a contient, au plus, une unité de chaque annotateur
Alignement
c1
c2
1
( i1 , i∅ )
1
2
( i1 , i1 )
( ... , ... )
1
2
( i3 , i12 )
→ alignement vide avec unité fictive i∅
→ vrai alignement
→ "faux" alignement
Nombre d’alignements unitaires générables : (
Jean-Philippe Fauconnier
c∈C
Nc ) − 1
Métriques pour l’Annotation
50 / 71](https://image.slidesharecdn.com/annotation-131127043620-phpapp01/85/Metriques-pour-l-evaluation-de-l-Annotation-50-320.jpg)






























































