Télécharger en tant que PDF, PPTX









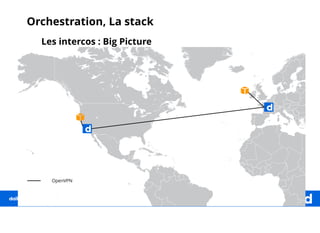
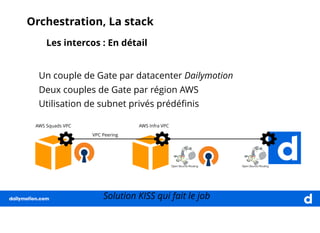

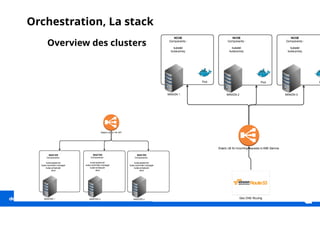

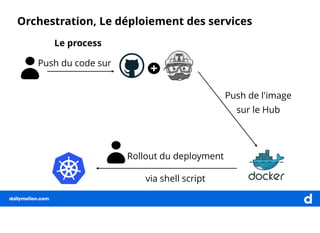








Le document décrit une expérience de transformation vers une architecture micro-services, en soulignant la nécessité de l'orchestration pour faciliter le déploiement et la gestion des clusters. Il détaille les outils et technologies utilisés, comme Ansible et Calico, ainsi que les approches pour centraliser les logs et monitorer les systèmes. La finalité est d'orchestrer efficacement les services pour soutenir la charge de travail élevée de dailymotion.























































