Téléchargé 51 fois






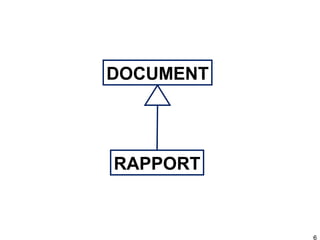

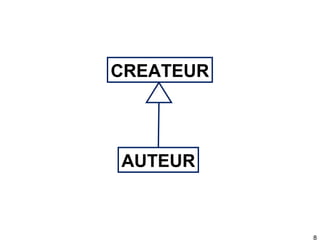
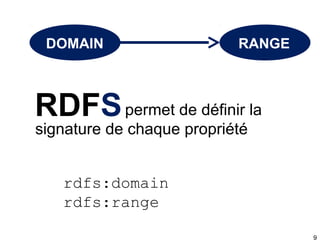









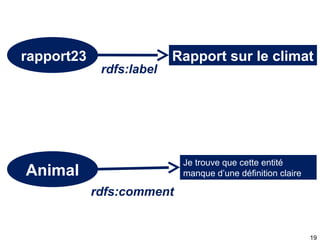




Ce document présente RDFS (RDF Schema), qui permet de créer des modèles simples pour des données RDF en définissant des classes, des propriétés et leur hiérarchie. Il décrit également les inférences possibles basées sur les relations entre classes et propriétés, telles que la transitivité et les déductions sur les domaines et les portées. En résumé, RDFS offre des outils pour organiser et enrichir les données RDF tout en facilitant leur réutilisation.



























































