









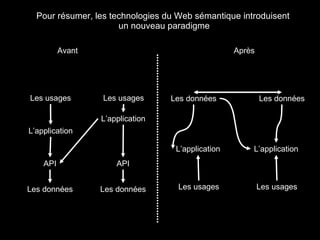





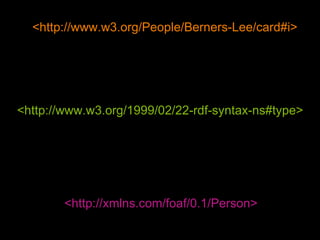












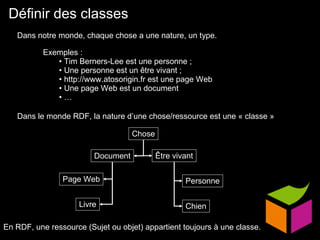
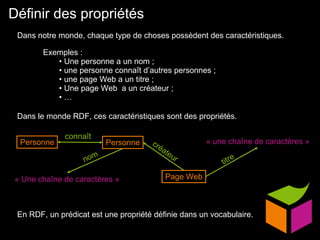
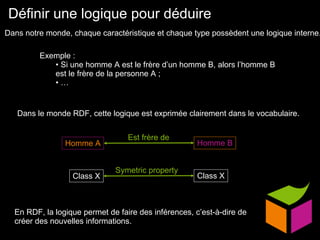
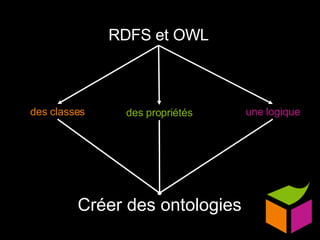





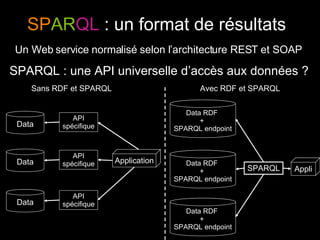
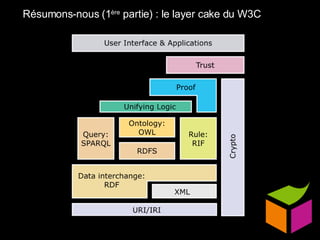



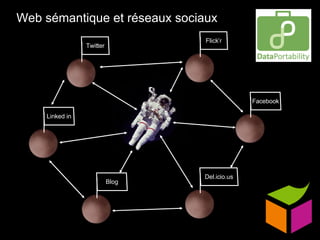
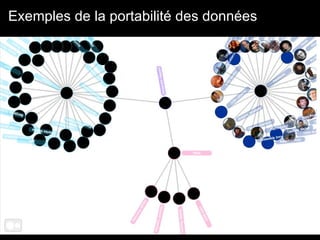
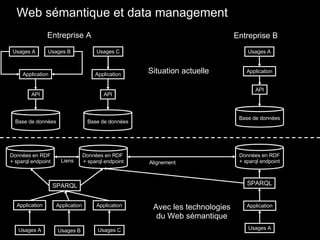
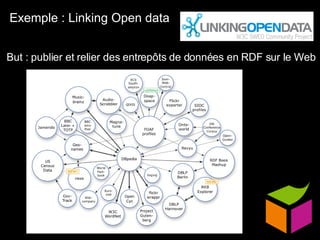

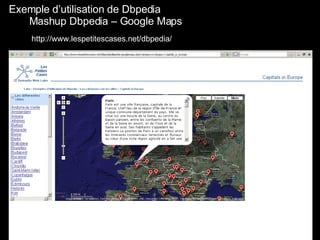


Le document traite du web sémantique, sa définition et ses implications pour l'avenir du web en tant qu'extension de la base de données mondiale. Il introduit les technologies et standards associés comme RDF et SPARQL, illustrant leur capacité à rendre les données interopérables et intelligibles. L'article évoque également des exemples d'applications et d'outils pour intégrer ces technologies, tout en soulignant l'importance de la mise en relation des données.

































































