Téléchargé 26 fois


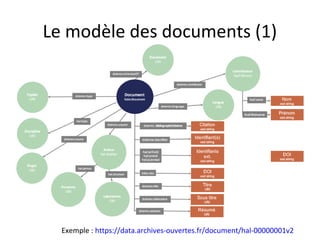
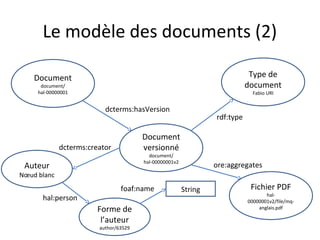





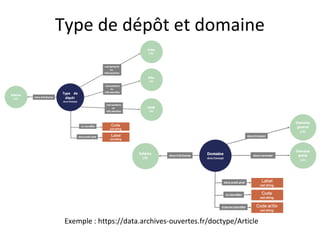









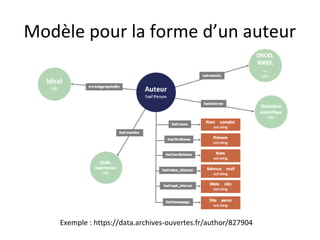














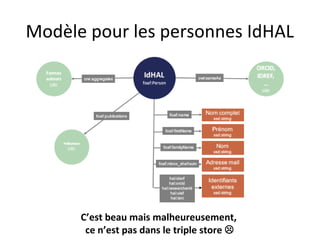
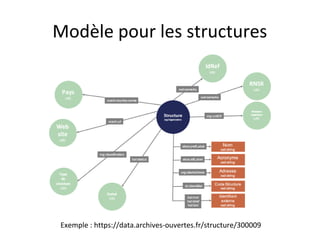

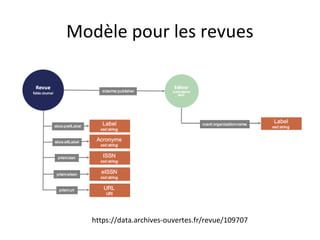
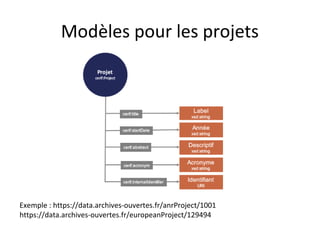



Le document présente un endpoint SPARQL pour accéder aux données de HAL, permettant de rechercher et de manipuler les métadonnées des documents académiques. Il fournit également des exemples de requêtes et des astuces pour extraire des informations telles que les versions de documents, les auteurs, et les types de publications. En outre, il aborde des techniques d'agrégation et de filtrage pour analyser les données liées aux recherches académiques.












![[Pgday.Seoul 2018] 이기종 DB에서 PostgreSQL로의 Migration을 위한 DB2PG](https://cdn.slidesharecdn.com/ss_thumbnails/04-pgdaydb2pgv1-181112042107-thumbnail.jpg?width=640&height=640&fit=bounds)


































