Télécharger pour lire hors ligne

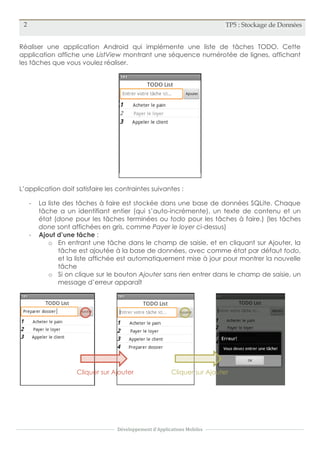
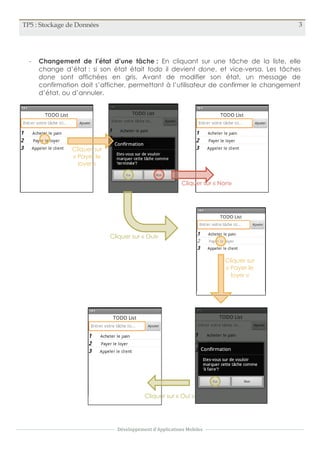

Le document décrit un projet de développement d'application mobile pour le stockage de données dans une base SQLite, centrée sur une liste de tâches à faire. L'application permet d'ajouter des tâches et de modifier leur état entre 'todo' et 'done', avec des fonctionnalités d'interface utilisateur pour la confirmation des changements. Les tâches terminées sont affichées en gris, et des messages d'erreur sont prévus pour des entrées invalides.















































