Télécharger en tant que PDF, PPTX





![Jalons historiques : au début était l’expert
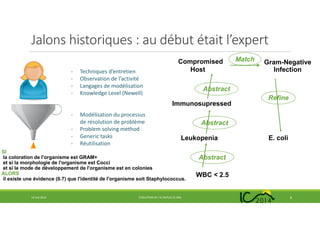
Les années 70 et le début des années 80 furent
marqués par la réalisation de nombreux systèmes
experts [Smith, 1984], où une connaissance experte
dans un domaine spécialisé est exprimée sous
forme de règles « si ... alors ... » et est applicable à
tout ensemble de faits décrivant une situation sur
laquelle le système doit produire des conclusions.
Les premiers furent : DENDRAL en chimie organique
[Lindsay et al., 1980], MYCIN en médecine
[Buchanan et Shortliffe (eds.), 1984], HEARSAY-II en
compréhension de la parole [Erman et al., 1980],
PROSPECTOR en géologie [Duda et al., 1976, 1981].
Marquis, Papini, Prades, 2014
14 mai 2014 EVOLUTION DE L’IC DEPUIS 25 ANS 7
SI
la coloration de l'organisme est GRAM+
et si la morphologie de l'organisme est Cocci
et si le mode de développement de l'organisme est en colonies
ALORS
il existe une évidence (0.7) que l'identité de l'organisme soit Staphylococcus.
Knowledge
acquisition
bottleneck](https://image.slidesharecdn.com/aussenacconfinviteic2014-histoireic25ans-140514103243-phpapp01/85/Aussenac-confinviteeic2014-histoire-ic25ans-7-320.jpg)

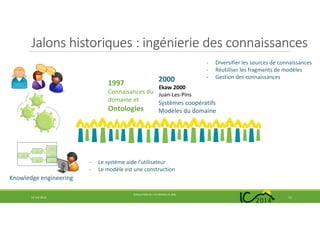


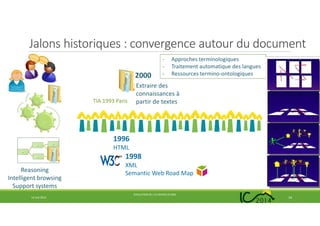


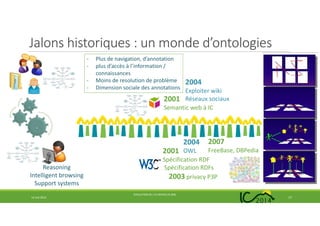
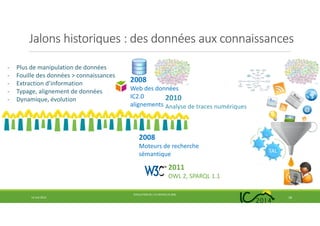









Le document traite de l'évolution de l'ingénierie des connaissances en France au cours des 25 dernières années, soulignant les transitions de la pénurie à la surabondance de connaissances. Il examine les jalons historiques, les changements paradigme, ainsi que l'impact du web et des ontologies sur le domaine. Enfin, il met en avant les défis futurs et la nécessité de préserver l'identité de l'ingénierie des connaissances au sein des tendances technologiques émergentes.















































