



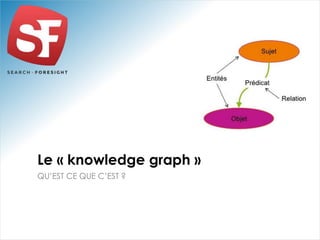
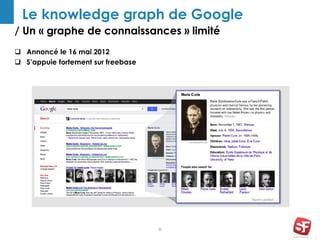
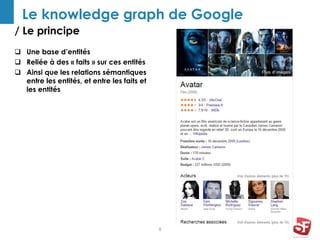




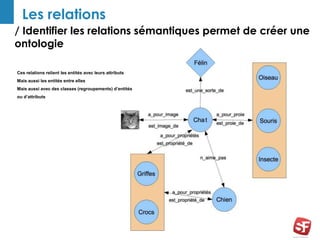



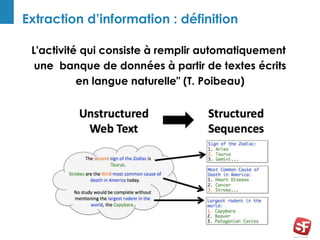




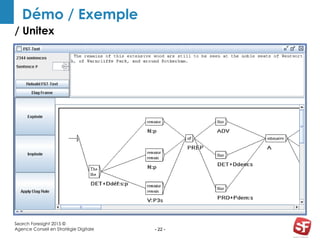



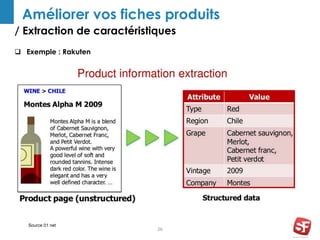


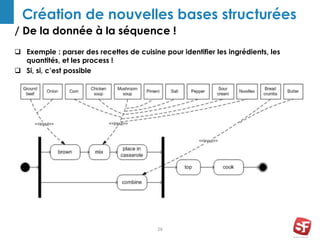
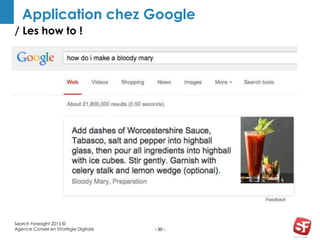
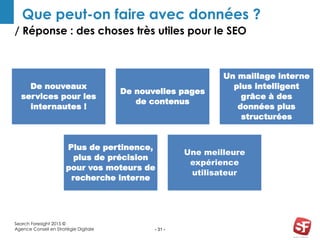



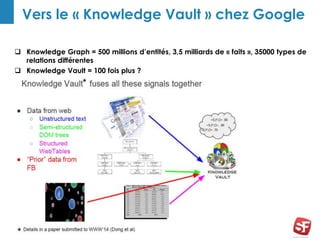








Philippe Yonnet, expert en référencement naturel avec plus de douze ans d'expérience, a dirigé et conseillé de nombreux sites à forte audience et a fondé l'association SEO Camp en France. Le document traite de l'extraction d'information et du concept de 'knowledge graph', en expliquant comment les entités nommées et les relations sémantiques sont essentielles pour construire des graphes de connaissances utiles pour le SEO. Enfin, il aborde les techniques et outils d'extraction d'information, soulignant leur importance croissante dans le développement de services et contenus en ligne.























































































