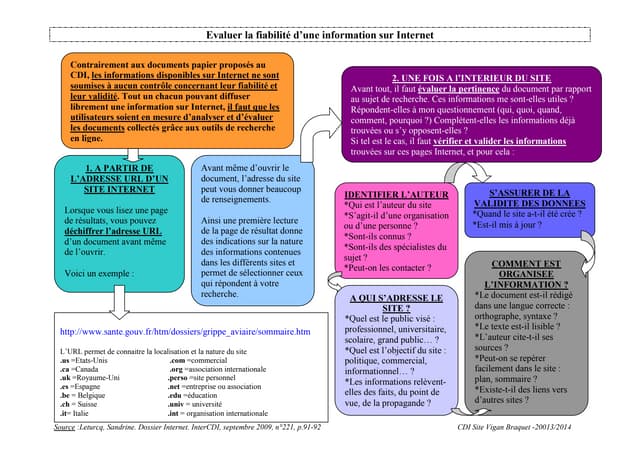
Ce document aborde la recherche et l'évaluation de l'information sur Internet dans le cadre d'une méthodologie documentaire en licence, soulignant la complexité du web et son utilisation croissante pour la recherche d'informations. Il propose une méthodologie en 10 règles pour naviguer efficacement sur Internet, ainsi que des sections sur le fonctionnement des moteurs de recherche, la protection de l'identité numérique, et l'évaluation de l'information. Enfin, il traite des enjeux de la lutte contre le plagiat et la protection de la propriété intellectuelle.

















































![Merci de votre attention [email_address] [email_address] [email_address]](https://image.slidesharecdn.com/internet20112012illustrurfist-110408093248-phpapp02/85/Internet-2011-2012-illustre-v3-72-320.jpg)