Télécharger en tant que PDF, PPTX













![Indexation
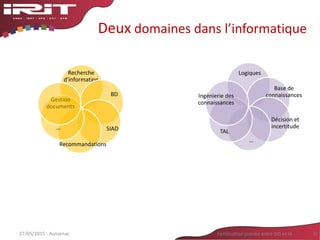
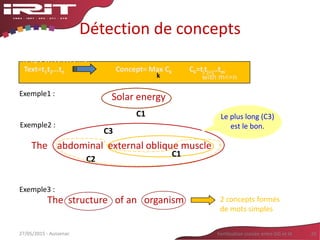
• Qu’est ce qu’indexer ?
– Associer des descripteurs à un document pour le
retrouver [Calabretto et Prié,04]
– Extraire d’un document une représentation
caractéristique de son contenu [Baziz,05]
• Nature variable des descripteurs :
– RI non sémantique : descripteur = groupe de mots
– RI sémantique : descripteur = élément d’ontologie
17
Le moteur manque de puissance en accélération
et en vitesse de pointe.
Phase moteur : accélération
Phase véhicule : grande vitesse
Motorisation Manque de puissance
27/05/2015 - Aussenac Fertilisation croisée entre SIG et IA](https://image.slidesharecdn.com/aussenacri-ia-2015-150603235316-lva1-app6892/85/Aussenac-ri-ia-2015-17-320.jpg)
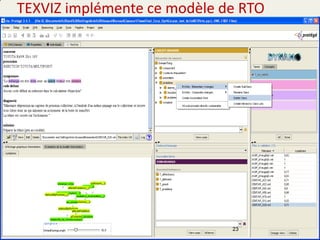
![27/05/2015 - Aussenac Fertilisation croisée entre SIG et IA 18
t1, t4
t7 t9
tk,
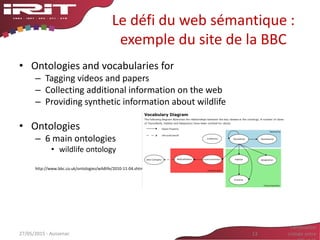
Schéma général de l’approche
des réseaux sémantiques pour représenter les documents [Baziz, 05]
ontologie
n1
n4
n3
n2
n6
n5
P13
P23
P12
P14
P42
P4i
P2i
Pmi
P3m
P2m
Un réseau
sémantique
Projeter un document sur une ontologie
Questions:
• Comment identifier les noeuds ?
• Comment les pondérer ?
• Comment pondérer les liens entre eux ?
un document
• noeuds + arcs
• noeuds = concepts
• arcs = liens étiqueté entre concepts
Réseau sémantique [Quillian, 68][Lee, 93]](https://image.slidesharecdn.com/aussenacri-ia-2015-150603235316-lva1-app6892/85/Aussenac-ri-ia-2015-18-320.jpg)


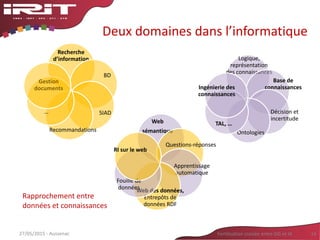
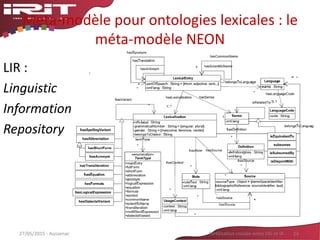
![Meta-modèle de Ressource
Termino-Ontologique
27/05/2015 - Aussenac
Fertilisation croisée entre SIG et IA 22
Termes manipulés
comme classes
Associer des informations
(POS, langue, ..)
Meta-modèle
OBIR (Reymonet 2007 et 2009)
Autres modèles
LingInfo (Buitelaar et al. 2006)
LexOnto [Cimiano et al. 2007]
LexInfo [Buitelaar et al. 2009]
LIR in NEON (Monteil Ponsoda
et al., 2008, 2011)](https://image.slidesharecdn.com/aussenacri-ia-2015-150603235316-lva1-app6892/85/Aussenac-ri-ia-2015-22-320.jpg)
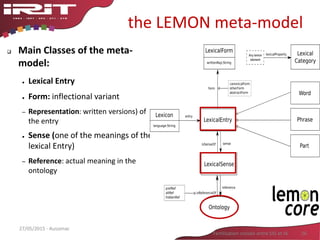


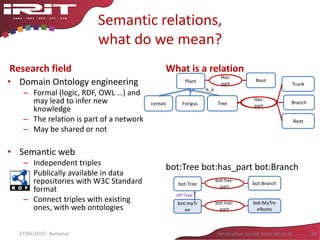


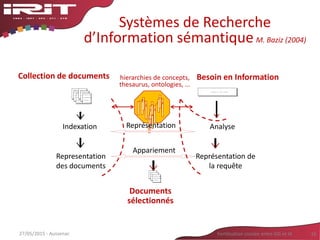
![Pattern based relation extraction,
an issue: variation
• A tree comprises at least a trunk,
roots and branches.
• With branches reaching the ground,
the willow is an ornamental tree.
• The tree of the neighbor has been
delimed.
• He climbs on the branches of the tree.
• This tree is wonderful. Its branches
reach the ground.
• Contains: very systematic pattern; the
parts may be difficult to spot;
enumeration > various parts
• With: meronymy pattern only in some
genres (such as catalogs, biology
documents)
• Delimed : Term and pattern are in the
same word; requires background
knowledge: delimed -> has_part
branches (and branches are cut)
• Of : Very ambiguous pattern; polysemy
reduced in [verb N1 of N2]
• Its : very ambiguous pattern; necessity
to take into account two sentences
32Fertilisation croisée entre SIG et IA27/05/2015 - Aussenac](https://image.slidesharecdn.com/aussenacri-ia-2015-150603235316-lva1-app6892/85/Aussenac-ri-ia-2015-31-320.jpg)



Ce document aborde les intersections croissantes entre les systèmes d'information (SIG) et l'intelligence artificielle (IA), mettant en lumière les différences et convergences entre ces domaines. Il explore comment la recherche d'information sémantique et le traitement automatique des langues se chevauchent, nécessitant une collaboration entre diverses disciplines pour des réponses opérationnelles. Finalement, le texte souligne l'importance d'une approche intégrée pour améliorer la gestion des connaissances et optimiser les technologies de recherche.



























