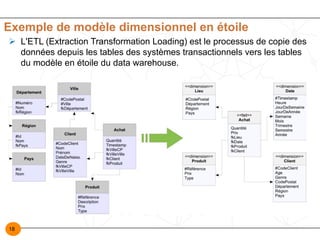
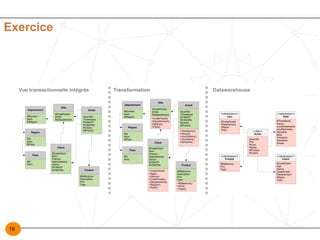
Le document présente une étude approfondie sur la modélisation des entrepôts de données, en se concentrant sur différentes technologies OLAP (ROLAP, MOLAP, HOLAP, et DOLAP) ainsi que sur les étapes de conception d'un data warehouse. Il détaille les caractéristiques, avantages et inconvénients de chaque système OLAP et les règles de Codd pour évaluer les produits OLAP, tout en soulignant l'importance de l'alimentation et de la modélisation multidimensionnelle dans la construction d'un entrepôt de données. En conclusion, il évoque les points clés pour réussir un projet de système d'information décisionnel, y compris l'adéquation aux besoins des utilisateurs et la planification des coûts.