Téléchargé 34 fois

























![Migration vers Hekaton
•
Storage
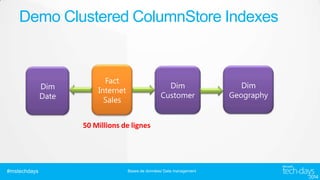
ALTER DATABASE ContosoOLTP ADD FILEGROUP [ContosoOLTP_hk_fs_fg] CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE ContosoOLTP
ADD FILE (NAME = [ContosoOLTP_fs_dir],
FILENAME = 'H:MOUNTHEADDATACONTOSOOLTP_FS_DIR') to FILEGROUP [ContosoOLTP_hk_fs_fg];
•
Table
CREATE TABLE Customers (
CustomerID nchar (5) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=100000),
CompanyName nvarchar (40) NOT NULL INDEX IX_CompanyName HASH(CompanyName) WITH (BUCKET_COUNT=65536),
ContactName nvarchar (30) NOT NULL ,
ContactTitle nvarchar (30) NOT NULL ,
Address nvarchar (60) NOT NULL ,
Ville nvarchar (15) NOT NULL INDEX IX_Ville HASH(Ville) WITH (BUCKET_COUNT=1024),
Region nvarchar (15) NOT NULL INDEX IX_Region HASH(Region) WITH (BUCKET_COUNT=1024),
PostalCode nvarchar (10) NOT NULL INDEX IX_PostalCode HASH(PostalCode) WITH (BUCKET_COUNT=100000),
Country nvarchar (15) NOT NULL ,
Phone nvarchar (24) NOT NULL ,
Fax nvarchar (24) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON)
•
Native procedure
CREATE PROC InsertCustomers (@CustomerID nchar(5),@CompanyName nvarchar(40),
@ContactName nvarchar(30),@ContactTitle nvarchar(30), @Address nvarchar(60),
@Ville nvarchar(15),@Region nvarchar(15),@PostalCode nvarchar(10),
@Country nvarchar(15),@Phone nvarchar(24),@Fax nvarchar(24))
WITH NATIVE_COMPILATION, SCHEMABINDING, execute as owner as
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, language = 'english')
INSERT INTO [dbo].[Customers] VALUES(@CustomerID,@CompanyName,@ContactName,@ContactTitle,@Address,
@Ville,@Region,@PostalCode,@Country,@Phone,@Fax);
END
#mstechdays
Bases de données/ Data management](https://image.slidesharecdn.com/datit304koppelpichautaurlienfrdricdeepdiveperformancelein-memoryda-140219102021-phpapp02/85/Deep-Dive-Performance-le-In-Memory-dans-SQL-Server-28-320.jpg)















Le document traite des nouveautés du SQL Server 2014, mettant en avant le traitement in-memory et les index de colonne pour améliorer la performance des bases de données. Il introduit des concepts tels que les index de colonne optimisés pour la mémoire et le projet Hekaton pour le traitement transactionnel en mémoire. Enfin, il aborde des mythes courants sur ces innovations et leurs avantages dans la gestion des données.






![[JSS2015] Nouveautés SSIS SSRS 2016](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015nouveautsssisssrs2016-151211082823-thumbnail.jpg?width=640&height=640&fit=bounds)

![[JSS2015] 3 DMV's pour evaluer les indexs](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-indexdmv-final-151211084704-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Café techno] Optimiser le coût de vos données avec DB2 distribué](https://cdn.slidesharecdn.com/ss_thumbnails/cafetechnopresentationdb2-25avril2013-130527030104-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[JSS2015] Query Store](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-querystore-151211084816-thumbnail.jpg?width=640&height=640&fit=bounds)










![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)






















