
























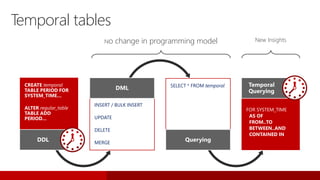
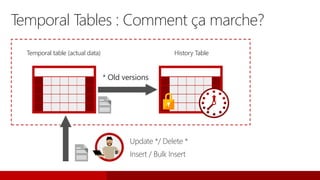

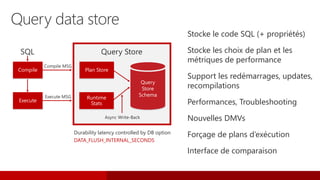



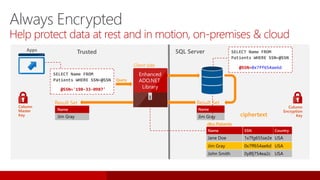













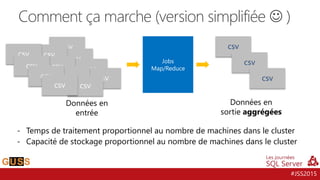
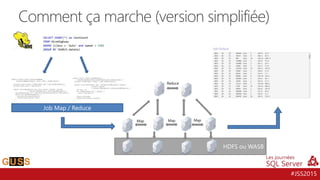
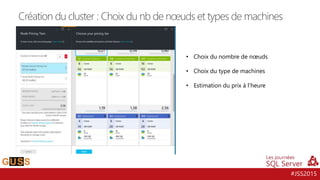

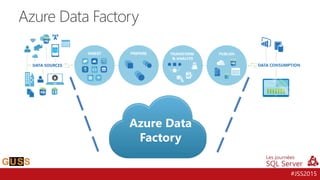





L'événement #jss2015 a célébré 5 ans de Journées SQL Server et 10 ans de la communauté Microsoft Data & BI, rassemblant 2000 contacts et 1000 participants. Il a abordé des sujets variés tels que les bases de données, la sécurité, l'analytique opérationnelle et les nouvelles fonctionnalités de SQL Server 2016, tout en offrant des sessions et des concours aux participants. Les discussions ont aussi porté sur des innovations dans le cloud, l'analyse de données et les outils d'optimisation.

![[JSS2015] Power BI Dev](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-powerbiapirest-151211085002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] - Document db et nosql](https://cdn.slidesharecdn.com/ss_thumbnails/documentdbetnosql-151211083215-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] 3 DMV's pour evaluer les indexs](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-indexdmv-final-151211084704-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Power BI: Nouveautés archi et hybrides](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-powerbi-151211084523-thumbnail.jpg?width=640&height=640&fit=bounds)






![[JSS2015] - Azure automation](https://cdn.slidesharecdn.com/ss_thumbnails/azureautomation-151211083408-thumbnail.jpg?width=640&height=640&fit=bounds)



![[JSS2015] Nouveautés SSIS SSRS 2016](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015nouveautsssisssrs2016-151211082823-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[4] dt mark deakin](https://cdn.slidesharecdn.com/ss_thumbnails/4dtmarkdeakin-160414132815-thumbnail.jpg?width=640&height=640&fit=bounds)









![[JSS2015] Query Store](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-querystore-151211084816-thumbnail.jpg?width=640&height=640&fit=bounds)






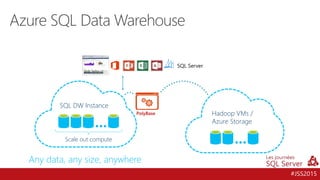
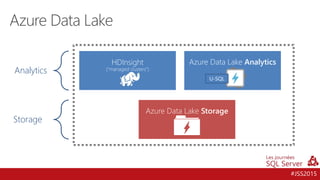
![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)











![[JSS2015] x events](https://cdn.slidesharecdn.com/ss_thumbnails/20151201-jss2015-xevents-151211083007-thumbnail.jpg?width=640&height=640&fit=bounds)

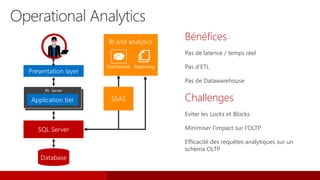
![[JSS2015] In memory and operational analytics](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-inmemoryandoperationalanalytics-151211084342-thumbnail.jpg?width=640&height=640&fit=bounds)
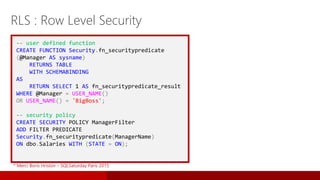
![[JSS2015] Nouveautés SQL Server 2016:Sécurité,Temporal & Stretch Tables](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sql2016-151211084830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] AlwaysOn 2016](https://cdn.slidesharecdn.com/ss_thumbnails/alwayson2016-151211083219-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Architectures Lambda avec Azure Stream Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-streamanalytics-151211084144-thumbnail.jpg?width=640&height=640&fit=bounds)


![[JSS2015] Eradiction des deadlocks](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-eradictiondesdeadlocks-151211084151-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Infra bi#4 - le scale out](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-infrabi4-lescaleout-151211084516-thumbnail.jpg?width=640&height=640&fit=bounds)




