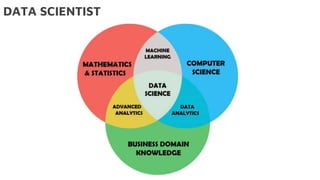
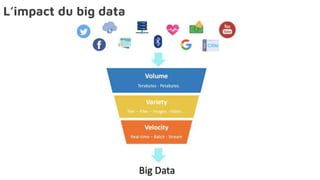
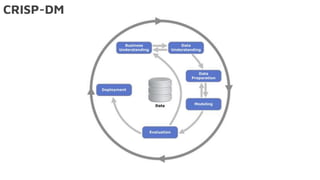
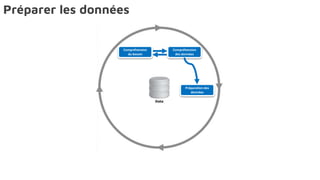
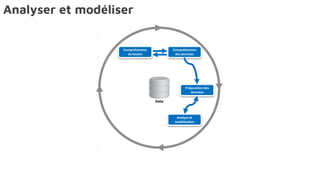
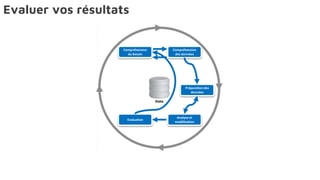
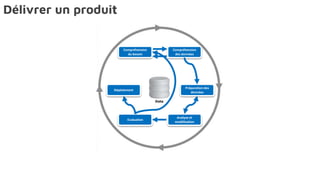
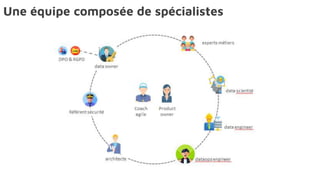
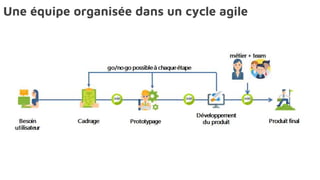
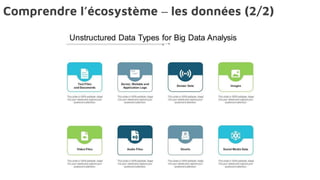
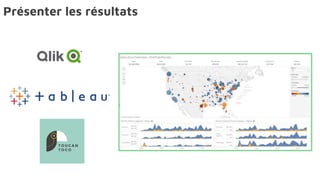
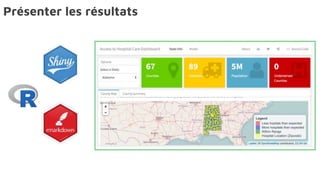
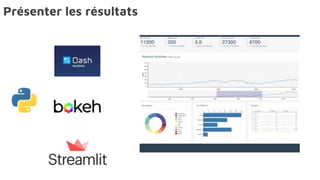
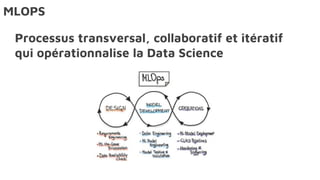
Le document présente la data science comme un outil clé pour valoriser les données au sein des entreprises, en mettant l'accent sur l'importance des méthodes et des équipes spécialisées. Il décrit un cadre standard pour comprendre et analyser les données, tout en soulignant le rôle crucial de l'agilité et de l'implication de l'IT dans le processus. L'impact de l'IA et des services cloud dans ce domaine est également abordé, ainsi que les enjeux éthiques et réglementaires associés.