Ce document traite des systèmes d'information, de la méthodologie Merise pour l'analyse et la conception de bases de données, ainsi que des différents modèles de données (conceptuels, logiques, physiques) et des notions essentielles telles que les dépendances fonctionnelles et la normalisation. Il fournit également une vue d'ensemble des traitements des informations, des spécifications de projet via le cahier des charges, et des éléments fondamentaux concernant les systèmes de gestion de bases de données. En résumé, il sert de guide pour comprendre les étapes et les composants nécessaires à la création et la gestion efficace d'un système d'information.














![16
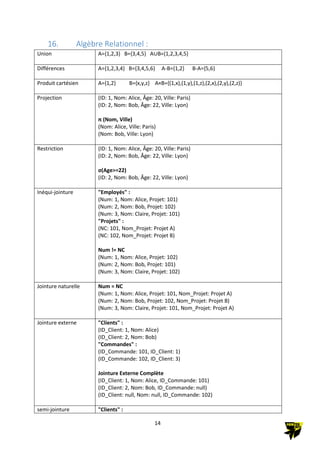
CREATE DATABASE [if not exists ]
MaBase
[CHARACTER SET utf8mb4]
[COLLATE utf8mb4_general_ci];
Utilisation d’une base de donné :
use test;
Supprimer une DataBase:
DROP DATABASE test
show create DATABASE test;
Afficher les moteurs de stockage :
show ENGINES;
Création d’une table :
CREATE TABLE [IF NOT
EXISTS] nom_table (
nomCol1 typeCol
[contraintes], nomCol2
typeCol [contraintes], ...
nomColN typeCol
[contraintes]
)[ENGINE=type_moteur]
[DEFAULT
CHARSET=jeu_de_caractères]
[COLLATE=nom_collation];
CREATE TABLE IF NOT EXISTS
Utilisateurs (
id INT AUTO_INCREMENT PRIMARY KEY,
nom VARCHAR(50) NOT NULL,
prenom VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLAT
E=utf8mb4_general_ci;
Afficher la structure de la table DESCRIBE nom_table;
Verrouiller les tables LOCK TABLES nom_table [READ| WRITE]
déverrouiller les tables UNLOCK TABLES;
Création des Vues :
Une vue est une table virtuelle basée
sur le résultat d'une requête SQL.
Supprimer d’une vue
CREATE VIEW nom_de_vue AS
SELECT colonne1, colonne2, ...
FROM table
WHERE condition;
DROP VIEW nom_de_vue;
Création de table temporaire :
Une table temporaire est une table
qui n'existe que pendant la durée de
la session ou de la transaction.
Pour la Supprission
CREATE TEMPORARY TABLE nom_table_temporaire (
colonne1 type_donnée,
colonne2 type_donnée,
...
);
DROP TABLE nom_table_temporaire;](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-16-320.jpg)
![17
Type de données (colonne)
Numériques : TINYINT, SMALLINT, MEDIUMINT, INT ou INTEGER, BIGINT, FLOAT, DOUBLE,
DECIMAL
Caractères : CHAR, VARCHAR, TINYBLOB, TINYTEXT, BLOB, TEXTE, MEDIUMBLOB,
MEDIUMTEXT, LONGBLOB, LONGTEXT
date/heure : DATE, TIME, ANNÉE, DATETIME, TIMESTAMP
Les Contraintes
NOT NULL : Obligation de donner
une valeur
nom_colonne type_donnee NOT NULL;
UNIQUE : Interdit deux même
valeurs pour une même colonne
nom_colonne type_donnee UNIQUE;
)
Ou bien:
nomCol1 type_donnee,
nomCol2 type_donnee,
UNIQUE(nomCol1 , nomCol2 );
Ou bien :
[CONSTRAINT nomContra] UNIQUE(nomCol1 , nomCol2 );
PRIMARY KEY : Clé primaire nomCol Type_donnee PRIMARY KEY,
Ou bien dans le cas de plusieur pk :
nomCol1 Type_donnee PRIMARY KEY,
nomCol2 Type_donnee PRIMARY KEY,
Ou bien:
nomCol1 Type_donnee PRIMARY KEY,
nomCol2 Type_donnee PRIMARY KEY,
PRIMARY KEY(nomCol1, nomCol2)
REFERENCES <table>(col) :
Clé étrangère, établit une relation avec
une autre table via sa clé primaire
CONSTRAINT nom_contrainte FOREIGN KEY
(nom_colonne) REFERENCES
table_parent(nom_colonne_p)
[ON DELETEreference_option]
[ON UPDATEreference_option]
Example:
CONSTRAINT fk1_cin FOREIGN KEY (numCIN)
REFERENCES users(numCIN)
CHECK(condition) : Emet une
condition sur une colonne
[CONSTRAINT [nom_contrainte]]
CHECK(expression) [[NOT] ENFORCED]
Example :
Cout DECIMAL(10,2 ) NOT NULL CHECK (cout>= 0),
DEFAULT : Définit une valeur par
défaut
nom_colonne type_donnee DEFAULT valeur_par_defaut;
Supprimer et modifier la table](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-17-320.jpg)
![18
Ajouter une ou plusieurs colonnes à
une table:
ALTER TABLE nom_table
ADD nouvelleCol1 [definition1],
ADD nouvelleCol2 [definition2],
Exemple1 une seule colonne :
ALTER TABLE users
ADD telephone VARCHAR(10);
Exemple1 plusieurs colonnes :
ALTER TABLE users (
ADD telephone VARCHAR(10,
Age integer NOT NULL CHECK (age>= 18)
);
Modifier une ou plusieurs colonnes à
une table:
ALTER TABLE nom_table
MODIFY nouvelleCol1 [definition1],
MODIFY nouvelleCol2 [definition2],
...;
Exemple1 une seule colonne :
ALTER TABLE users
MODIFY prenom VARCHAR(40) ;
Exemple1 plusieurs colonnes :
ALTER TABLE users (
MODIFY prenom VARCHAR(40),
Age integer CHECK (age>= 28)
);
changer le nom d’une colonnes d’une
table:
ALTER TABLE nom_table CHANGE COLUMN
nom_original nouveau_nom[definition];
Exemple:
ALTER TABLE users
CHANGE COLUMN prenom last_name
VARCHAR(40);
Supprimer une colonne d’une table : ALTER TABLE nom_table DROP COLUMN
nom_colonne;
Exemple:
ALTER TABLE users DROP COLUMN age;
Renommer le nom d’une table : ALTER TABLE nom_table RENAME TO
nouveau_nom_table;
Exemple:
ALTER TABLE users RENAME TO personnes;
Ajouter ou supprimer une clé primaire ALTER TABLE nom_table
ADD PRIMARY KEY(column_list);
ALTER TABLE nom_table
DROP PRIMARY KEY;
Ajouter et supprimer une clé étrangère ALTER TABLE nom_table](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-18-320.jpg)
![19
ADD CONSTRAINT constraint_name
FOREIGN KEY (column_name, ...)
REFERENCES parent_table(colname,..);
ALTER TABLE nom_table
DROP FOREIGN KEY nom_contrainte;
Ajouter et supprimer une contrainte ALTER TABLE nom_table
ADD CONSTRAINT nom_contrainte
UNIQUE (liste_colonnes);
ALTER TABLE nom_table
DROP INDEX nom_contrainte;
Supprimer une table ou plusieurs DROP [TEMPORARY] TABLE [IF EXISTS] nom_table1,
nom_table2,…
b. LMD (MySQL)
Insertion d’une ou plusieurs lignes : INSERT INTO
nom_table(col1,col2,...)
VALUES(val1,val2,...);
Ou bien plusieurs lignes:
INSERT INTO nom_table (c1,c2,...)
VALUES(v01,v02,...),
(v11,v22,...),
..
(vn1,vn2,...);
Le cas d’insertion de tous les
cols :
INSERT INTO nom_table
VALUES(v1,v2,...);
Example:
INSERT INTO users(num,nom,prenom)
VALUES(120,’maryem’,’saidi’);
Modification les valeurs d’une ligne UPDATE nom_table SET nom_col1 =
expr1,
nom_col2 = expr2,...[WHERE
condition];
Example:
UPDATE users SET age=31,
nom=’laila’ WHERE Num=12;
Supprimer une ligne DELETE FROM nom_table WHERE
Conditions
Example:
DELETE FROM users WHERE Num=12;
La sélection des données : SELECT [DISTINCT] Liste_Select | * FROM
Liste_Tables](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-19-320.jpg)
![20
INNER JOIN Table AS T1 ON T1.ID = T2.ID
WHERE Liste_Conditions_Recherche
GROUP BY Liste_regroupement
HAVING Liste_Conditions_regroupement
ORDER BY liste_Tri
AS : alias donner un nouveau nom à
la table (n’est pas obligatoire)
SELECT * FROM Users as U;
Select * from Users U
[DISTINCT] : afficher le résultat sans
doublant
SELECT DISTINCT ville FROM Users
WHERE : définir la liste des
conditions
SELECT * FROM Users where age=12
GROUP BY : regrouper un ensemble
de ligne par valeurs de colonnes.
SELECT * FROM Users groupe by ville, age;
Having : la condition de
regroupement.
Select * FROM Users groupe by ville having age
>=20
ORDER BY : trie dans l’ordre croissant
ou décroissant, par défaut croissant
Select * FROM Users groupe by ville having age
>=20
Order by age ASC, ville DESC;
INNER JOIN … ON : Joint deux tables
en fonction d'une condition connue
sous le nom de prédicat de jointure
(Pas des valeurs null)
Exemple : sélectionne les noms des employés ainsi
que les noms des départements
Select e.nom, d.nom FROM employés e INNER JOIN
départements d ON e.id = d.id;
LEFT JOIN (OU LEFT OUTER JOIN):
Cette jointure renvoie toutes les
lignes de la table de gauche, même
s'il n'y a pas de correspondance dans
la table de droite. Si aucune
correspondance n'est trouvée, les
valeurs de la table de droite seront
NULL.
Select e.nom, d.nom FROM employés e LEFT JOIN
départements d ON e.id = d.id;
Remarque : LEFT OUTER et RIGHT OUTER n’est pas
supporté par MYSQL
RIGHT JOIN (OU RIGHT OUTER JOIN):
Cette jointure renvoie toutes les
lignes de la table de droite, même s'il
n'y a pas de correspondance dans la
table de gauche. Si aucune
correspondance n'est trouvée, les
valeurs de la table de gauche seront
NULL.
Select e.nom, d.nom FROM employés e RIGHT JOIN
départements d ON e.id = d.id;
CROSS JOIN : Cette jointure renvoie
le produit cartésien des deux tables,
c'est-à-dire toutes les combinaisons
possibles de lignes entre les deux
tables. Sans ON
Exemple : Cette requête renverra toutes les
combinaisons possibles de noms d'employés et de
noms de projets, créant un tableau avec toutes les
associations possibles
SELECT e.nom, p.nom FROM employés e CROSS JOIN
projets p;](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-20-320.jpg)
![21
SELF JOIN ( table réflexive) : Cette
jointure renvoie le produit cartésien
des deux tables, c'est-à-dire toutes
les combinaisons possibles de lignes
entre les deux tables.
Exemple : Cette requête sélectionne le nom d'un
employé et le nom de son manager. (inner join , left
join , right join)
SELECT e1.nom AS employé, e2.nom AS manager
FROM employés e1 INNER JOIN employés e2 ON
e1.manager_id = e2.id;
Les requêtes préparées : (pour tous les
requête : select, insert, delete, update)
-- Préparation de la requête
PREPARE reqt FROM
'SELECT id, nom FROM client WHERE id = ?';
-- utilisation de la requête prépare plusieurs foi :
SET @id = 1;
EXECUTE reqt USING @id;
-- Libération de la requête préparée
DEALLOCATE PREPARE reqt;
Création des index :
Pendant la création de la table :
CREATE TABLE nom_table (
col1 TYPE,
….
INDEX (liste_colonne)
);
Après la création de la table :
CREATE [UNIQUE | FULLTEXT | SPATIAL]
INDEX nomIndex
[USING BTREE | HASH]
ON [nomBase.]nomTable (colonne1 [(taille1)]
[ASC | DESC], colonne2 [(taille2)] [ASC |
DESC], ...);
En modifiant la table :
ALTER TABLE nom_table ADD INDEX
nom_index (liste_colonne);
Exemple cas 1 :
CREATE TABLE clients (
id INT PRIMARY KEY,
nom VARCHAR(100),
ville VARCHAR(100),
INDEX (nom, ville)
);
Exemple cas 2 :
CREATE UNIQUE INDEX code_client_unique
ON ecole.clients (code_produit);
Exemple cas 3 :
ALTER TABLE clients ADD UNIQUE INDEX
unique_nom_index (nom);
Suppression d’un index :
DROP INDEX nom_index ON nom_table;
Exemple:
DROP INDEX code_client_unique ON clients;
Importation d’une Database : mysql -u utilisateur -p nom_base_de_données <
fichier_dump.sql
Exportation de Database : mysqldump -u utilisateur -p nom_base_de_données
> fichier_dump.sql
Requetés de l’union :
requete Explication
UNION : combiner les résultats de deux ou
plusieurs requêtes SELECT en une seule, en
supprimant les doublons.
SELECT id, name FROM employees
UNION
SELECT id, name FROM managers;](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-21-320.jpg)

![23
SELECT * FROM clients WHERE EXISTS (SELECT *
FROM commandes WHERE clients.id =
commandes.client_id);
IN (sous_requete) : TRUE si l'opérande
est égal à un élément d'une liste
d'expressions. NOT IN dans le cas
contraire
Exemple : sélectionne les employés qui travaillent dans
les départements 'Informatique' ou 'Marketing'.
SELECT * FROM employés WHERE département IN
('Informatique', 'Marketing');
LIKE : TRUE si l'opérande correspond à un
modèle. Not Like dans le cas contraire.
Les Jocker : % plusieurs caractères.
_ un seul caractère.
Les regex : [ ], [^]
Exemple : sélectionne les clients dont le nom
commence par 'Jean'.
SELECT * FROM clients WHERE nom LIKE 'Jean%';
NOT : Inverse la valeur de tout autre
opérateur booléen.
Exemple : sélectionne les produits dont le prix n'est pas
inférieur à 50.
SELECT * FROM produits WHERE NOT prix < 50;
OR : TRUE si l'une ou l'autre expression
booléenne est TRUE.
Exemple : sélectionne les employés qui travaillent soit
dans le département 'Informatique', soit dans le
département 'Ventes'.
SELECT * FROM employés WHERE département =
'Informatique' OR département = 'Ventes';
SOME (sous_requete) : TRUE si certains
éléments d'un jeu de comparaisons sont
TRUE
Exemple : sélectionne les produits dont le prix est
supérieur à certains des prix des produits de la
catégorie 'Jouets'.
SELECT * FROM produits WHERE prix > SOME (SELECT
prix FROM produits WHERE catégorie = 'Jouets');
Les fonctions Mathématiques :
Fonction Explication Resultat
ABS() : Retourne la valeur absolue d'un nombre SELECT ABS(-15) AS valeur_absolue; 15
CEIL() : Renvoie la plus petite valeur entière
supérieure ou égale au nombre d'entrée
SELECT CEIL(4.3) AS valeur_ceil; 5
FLOOR() : Renvoie la plus grande valeur entière
non supérieure au nombre d'entrée.
SELECT FLOOR(4.9) AS valeur_floor; 4
MOD() : Renvoie le reste d'un nombre divisé par
un autre (modulo)
SELECT MOD(10, 3) AS reste; 1
ROUND() : Arrondit un nombre à un nombre
spécifié de places décimales
SELECT ROUND(3.456, 2) AS arrondi; 3.46
TRUNCATE() : Tronque un nombre à un nombre
spécifié de places décimales sans arrondir.
SELECT TRUNCATE(3.456, 2) AS tron;
SELECT TRUNCATE(3.456, 0) AS tron;
3.45
3](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-23-320.jpg)



![27
RENAME USER 'alice'@'localhost' TO 'bob'@'localhost';
Supprimer un utilisateur :
DROP USER 'bob'@'localhost';
Syntaxe des privilèges :
GRANT privilege1 [(liste_colonnes)], [privilege2 [(liste_colonnes)], ...] ON [type_objet]
niveau_privilege TO utilisateur [IDENTIFIED BY mot_de_passe];
Exemple :
GRANT SELECT, UPDATE (nom, prenom, adresse), DELETE, INSERT ON eshop_app_db.clients
TO 'saadi'@'localhost';
Accorder des privilèges
GRANT SELECT, INSERT ON ma_base.ma_table TO 'alice'@'localhost';
Accorder tous les privilèges
GRANT ALL PRIVILEGES ON ma_base.* TO 'alice'@'localhost';
Syntaxe pour Révoquer les privilèges (retirer le privilège)
REVOKE privilege [, privilege2, ...] ON niveau_privilege FROM utilisateur;
Exemple
REVOKE INSERT ON ma_base.ma_table FROM 'alice'@'localhost';
Créer un rôle :
CREATE ROLE 'manager';
Accorder des privilèges à un rôle :
GRANT SELECT, INSERT, UPDATE ON eshop_app_db.clients TO 'manager';
Attribuer un rôle à un utilisateur :
GRANT 'manager' TO 'alice'@'localhost';
Afficher les rôles d'un utilisateur :
SHOW GRANTS FOR 'alice'@'localhost';
Attirer un rôle a un utilisateur :
REVOKE '<role>' FROM '<user>'@'<host>';
Supprimer un rôle :
DROP ROLE 'manager';
18. SQL procédurale MySQL:
Les sous programmes :
C’est un bloc d’instructions qui peut être imbriqué dans un autre bloc qui contient les éléments
suivants :
- BIGIN : indiquer le début du bloc.
- DECLARE : optionnelle déclaration des variables, fonction, trigger….
- END : indique la fin du bloc
Exemple :
BEGIN
SELECT 'Bloc instructions1;
BEGIN
SELECT 'Bloc d''instructions2;
END;
BEGIN
SELECT 'Bloc d''instructions3';](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-27-320.jpg)
![28
END;
END;
Les variables :
DECLARE nomVar [,nomVar2...] typeMySQL [DEFAULT expression];
Exemple:
DECLARE DateNai DATE;
DECLARE statut BOOLEAN DEFAULT TRUE;
DECLARE x,y,z INT;
Variable de session avec le symbole @:
SET @nomVariable := valeur ou bien SELECT @nomVariable := valeur
Les fonctions
Peut renvoyer caractère, entier…et non pas une table. Pour renvoyer une table il faut utiliser les
procédures stockées.
La syntaxe :
DROP FUNCTION IF EXISTS nom_fonction;
CREATE FUNCTION nom_fonction (parameter)
RETURNS type_retour
BEGIN
-- Déclaration informative
DECLARE variable_example TYPE;
-- Instructions
SELECT 'Exécution des instructions ici';
RETURN type_retour;
END;
READS SQL DATA : lire les données
MODIFIES SQL DATA : modifie les données
CONTAINS SQL : elles ne lisent ni ne modifie
DELIMITER $$ : c’est comme point-virgule à la
fin d’une instruction il permet l’exécution des
instructions comme un seul bloc
Example:
DROP FUNCTION IF EXISTS nbrclient;
DELIMITER $$
CREATE FUNCTION nbrclient (v VARCHAR(255))
RETURNS INT
READS SQL DATA
BEGIN
DECLARE nombre INT;
-- Calcul du nombre de clients par ville
SET nombre = (SELECT COUNT(*)
FROM clients
WHERE adresse = v);
RETURN nombre;
END $$
DELIMITER ;
Appel de la fonction:
SELECT nbrclient ('Rabat');
Les procédures stockées
- Les procédures stockées permettent de stocker un ensemble de requêtes SQL, à exécuter
en cas de besoin.
- La procédure stockée peut également exécuter une autre procédure stockée ou une
fonction.
- La procédure stockée a trois directions :
o IN : (par défaut) Paramètre d'entrée accessible en lecture seule dans la PS
o OUT : Paramètre de sortie pour retourner une valeur de la procédure à l'appelant.
o INOUT : Paramètre d'entrée et de sortie passer une valeur à la procédure ou
fonction et retourner une valeur modifiée à l'appelant
Syntaxe
DELIMITER $$
Exemple avec IN:
DELIMITER $$](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-28-320.jpg)
![29
CREATE PROCEDURE nom_procedure (param1
INT, param2 VARCHAR(50))
BEGIN
-- Code SQL à exécuter
SELECT * FROM table WHERE colonne1 =
param1 AND colonne2 = param2;
END $$
DELIMITER ;
CREATE PROCEDURE ps_client(IN ville
VARCHAR(255))
BEGIN
SELECT * FROM clients
WHERE UPPER(adresse) = UPPER(ville);
END $$
DELIMITER ;
Appel de la PS:
CALL ps_client ('Rabat');
Exemple avec OUT :
DELIMITER //
CREATE PROCEDURE psClient(IN v
VARCHAR(255), OUT nbrCl INT)
BEGIN
SELECT COUNT(*) INTO nbrCl FROM clients
WHERE adresse = v;
END //
DELIMITER ;
Appel de la PS:
CALL psClient ('rabat', @total);
SELECT @total;
Exemple avec INOUT :
DELIMITER //
CREATE PROCEDURE SetCounter(INOUT counter
INT, IN inc INT)
BEGIN
SET counter = counter + inc;
END //
DELIMITER ;
Appel de la PS:
SET @counter = 0;
CALL SetCounter(@counter, 7);
SELECT @counter;
Suppression d’une procédure stockée : DROP PROCEDURE [IFEXISTS] nom_procedure_stockée;
Lister les procedures stockée: SHOW PROCEDURE STATUS [LIKE 'pattern' | WHERE condition]
Structure de contrôle conditionnelle
IF
IF condition THEN
instructions
END IF
IF-ELSE
IF condition THEN
instructions
ELSE
instructions
END IF
IF-ELSEIF-ELSE
IF condition 1 THEN
instructions
ELSEIF condition 2 THEN
instructions 2
ELSE
instructions 3
END IF
Case sans sélecteur
CASE
WHEN condition 1 THEN
instructions 1
WHEN condition 2 THEN
instructions 2
...
WHEN condition N THEN
instructions N
[ELSE instructions N+1]
END CASE
Case avec sélecteur
CASE variable_selector
WHEN expr1 THEN instructions1
WHEN expr2 THEN instructions2
...
WHEN exprN THEN instructionsN
[ELSE instructionsN+1]
END CASE](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-29-320.jpg)
![30
Structure de contrôle itératives
LEAVE : Qui sort d’une boucle (ou d’un bloc étiqueté)
ITERATE : Qui force le programme à refaire un tour de boucle depuis le début
LOOP
[label_debut:] LOOP
statement_list
END LOOP [label_fin]
WHILE
[label_debut:] WHILE condition DO
list_of_instructions
END WHILE [label_fin]
REPEAT
REPEAT
list_of_instructions
UNTIL condition
Les exceptions
En MySQL, les exceptions sont gérées à travers des conditions et des gestionnaires d'exceptions
(handlers) dans les procédures stockées.
Syntaxe 1:
DECLARE handler_action HANDLER
FOR condition_value [, condition_value ...]
statement;
Handler_action: {
CONTINUE
| EXIT
| UNDO
}
Condition_value: {
mysql_error_code
| SQLSTATE [VALUE] sqlstate_value
| condition_name
| SQLWARNING
| NOT FOUND
| SQL EXCEPTION
}
Explication :
handler_action : C'est l'action à entreprendre si la condition est rencontrée.
CONTINUE : Continue l'exécution après le gestionnaire.
EXIT : Termine l'exécution du bloc ou de la procédure après avoir exécuté le gestionnaire.
UNDO : Non supporté dans MySQL (présent dans la documentation SQL standard, mais
non implémenté dans MySQL).
condition_value : Vous pouvez intercepter différentes erreurs ou conditions en utilisant un ou
plusieurs de ces éléments :
mysql_error_code : Un code d'erreur MySQL spécifique (par exemple 1062 pour une
violation de clé unique).
SQLSTATE VALUE : Un code standard SQLSTATE (par exemple '23000' pour une violation
de contrainte).
condition_name : Un nom de condition personnalisé que vous avez déclaré avec DECLARE
CONDITION.
SQLWARNING : Capture tous les avertissements SQL.
NOT FOUND : Capture les situations où aucune ligne n'est trouvée.
SQLEXCEPTION : Capture toutes les erreurs SQL non spécifiquement traitées.
Syntaxe 2:](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-30-320.jpg)
![31
DECLARE nomException CONDITION FOR
SQLSTATE 'valeur_sqlstate' | code_erreur_mysql;
Syntaxe 3 :
L'instruction SIGNAL peut être utilisée pour lever des exceptions personnalisées en MySQL avec
des informations supplémentaires.
SIGNAL SQLSTATE 'sqlstate_value' SET info_1 = valeur_1, info_2 = valeur_2, ...;
L'instruction RESIGNAL en MySQL est utilisée pour relancer une exception qui a été capturée dans
un gestionnaire d'exceptions
RESIGNAL [SQLSTATE 'sqlstate_value'] [SET MESSAGE_TEXT = 'message_text', info_1 = val_1, ..]
Example 1 :
CREATE PROCEDURE insert_with_continue()
BEGIN
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
SELECT 'Une erreur est survenue, mais l'exécution continue.';
END;
SELECT 'Suite de l'exécution après l'erreur.';
END;
Example 2 :
CREATE PROCEDURE insert_with_exit()
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
SELECT 'Une erreur est survenue. L'exécution est interrompue.';
END;
SELECT 'Cette ligne ne sera pas exécutée si une erreur se produit.';
END;
Example 3 :
CREATE PROCEDURE insert_with_named_exception()
BEGIN
DECLARE duplicate_key CONDITION FOR SQLSTATE '23000';
DECLARE EXIT HANDLER FOR duplicate_key
BEGIN
SELECT 'Erreur : Violation de clé unique, insertion échouée.';
END;
INSERT INTO employees (id, name) VALUES (1, 'John');
SELECT 'Cette ligne ne sera pas exécutée si une erreur se produit.';
END;
Example 4 :
CREATE PROCEDURE ErreurA()
BEGIN
SELECT 'Une autre erreur est survenue';
END; //
DELIMITER ;
CREATE PROCEDURE ErreurB()
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
CALL ErreurA ();](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-31-320.jpg)
![32
END;
DELIMITER ;
Example 5 :
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Erreur personnalisée levée', error_code = 1001,
error_details = 'Détails supplémentaires sur l'erreur.';
Example 6 :
RESIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Une erreur SQL a été capturée et relancée.',
custom_info = 'Informations supplémentaires sur l'erreur.';
Les Triggers (Déclencheurs)
Un déclencheur est une procédure stockée, dans la base de données, qui s'appelle
automatiquement à chaque fois qu'un événement spécial se produit sur la table à laquelle le
déclencheur est attaché.
Syntaxe:
CREATE TRIGGER nom_declencheur
[ BEFORE | AFTER ] { INSERT | UPDATE |
DELETE }
ON nom_table
[ FOR EACH ROW ]
BEGIN
-- corps_declencheur
END;
CREATE TRIGGER nom_declencheur : Déclare un
nouveau déclencheur avec le nom spécifié.
[ BEFORE | AFTER ] : Indique si le déclencheur
s'exécute avant ou après l'opération spécifiée
(INSERT, UPDATE, DELETE).
{ INSERT | UPDATE | DELETE } : Spécifie
l'opération qui déclenche le déclencheur.
ON nom_table : Indique la table sur laquelle le
déclencheur est défini.
[ FOR EACH ROW ] : Indique que le déclencheur
doit s'exécuter pour chaque ligne affectée par
l'opération.
BEGIN ... END : Définit le corps du déclencheur,
où vous pouvez écrire le code qui sera exécuté
lorsque le déclencheur est déclenché.
Les cas existents :
o Before insert
o After insert
o Before update
o After update
o Before delete
o After delete
Les notions OLD/NEW :
- Le mot-clé OLD fait référence aux valeurs d'une ligne avant qu'elle ne soit modifiée. (Pour
UPDATE et DELETE).
- Le mot-clé NEW permet d’accéder aux valeurs après l'opération. (pour INSERT et UPDATE).
Exemple :
CREATE TRIGGER insertion_clients
AFTER INSERT ON clients
FOR EACH ROW
BEGIN
INSERT INTO historique_modifications (client_id, ancienne_valeur, nouvelle_valeur,
date_modification, operation) VALUES (NEW.id, NULL, CONCAT(NEW.nom, ' ',](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-32-320.jpg)
![33
NEW.prenom), NOW(), 'INSERT');
END;
Lister les Triggers : SHOW TRIGGERS;
Suppression d’un déclencheur : DROP TRIGGER [IF EXISTS] [nom_bd.nom_declencheur];
Les Curseurs
Un curseur est un objet utilisé dans les systèmes de gestion de bases de données (SGBD) pour traiter
et manipuler des ensembles de résultats de requêtes de manière plus contrôlée.
Syntaxe :
DECLARE nom_curseur CURSOR FOR instruction_SELECT;
OPEN nom_curseur;
FETCH nom_curseur INTO liste_variables;
CLOSE nom_curseur;
- DECLARE : Cette ligne déclare un curseur nommé nom_curseur pour une instruction SELECT
spécifiée (remplacez instruction_SELECT par votre requête SQL).
- OPEN : Cette commande ouvre le curseur, exécutant ainsi l'instruction SELECT et préparant
l'ensemble des résultats à être parcouru.
- FETCH : Cette instruction récupère la prochaine ligne de l'ensemble des résultats du curseur et
l'affecte aux variables spécifiées dans liste_variables.
- CLOSE : Cette commande ferme le curseur, libérant ainsi les ressources associées.
- DEALLOCATE : Les ressources sont libérées
Example:
DECLARE @nom VARCHAR(50);
DECLARE @prenom VARCHAR(50);
DECLARE mon_curseur CURSOR FOR
SELECT nom, prenom FROM clients WHERE ville = 'Paris';
OPEN mon_curseur;
FETCH NEXT FROM mon_curseur INTO @nom, @prenom;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'Nom: ' + @nom + ', Prénom: ' + @prenom;
FETCH NEXT FROM mon_curseur INTO @nom, @prenom;
END;
CLOSE mon_curseur;
DEALLOCATE mon_curseur;
Les transactions
Voici comment gérer les transactions dans SQL :
- Démarrer une Transaction : Utilisez START TRANSACTION ou BEGIN pour initier une
transaction.
- Effectuer des Opérations : Exécutez vos commandes SQL (INSERT, UPDATE, DELETE, etc.).](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-33-320.jpg)

![35
Declare @nom varchar(20), @prenom varchar(20)
Select @nom=nom, @prenom=prenom from client where idClt = 1
Syntaxe de la structure IF …. ELSE ….:
IF [NOT]
Condition instruction
[ELSE Instruction]
Ou bien
IF [NOT] EXISTS(requête select)
Instruction
[ELSE Instruction]
Example:
DECLARE @nbr int
SET @nbr = (SELECT COUNT(CltID) FROM Clients)
IF(@nbr <10)
PRINT ‘Plus de 10 Clients’
ELSE
PRINT ‘Moins de 10 Clients’
Syntaxe de la structure While
While [NOT] Condition instruction
Les instruction BREAK, CONTINUE
permettent respectivement
d’interrompre ou de continuer une
boucle.
DECLARE @i int
SET @i = 0
WHILE @i <10
BEGIN
PRINT ‘i=’+ CONVERT(varchar(2), @i)
SET @i=@i+1
END
L’étiquette GOTO : Syntaxe de CASE
'instruction GOTO permet de rediriger
l'exécution du flux de contrôle vers une
autre partie du script SQL à l'aide d'une
étiquette
DECLARE @i int
SET @i = 0
Debut:
PRINT 'Index=‘ +
CONVERT(varchar(2),@i)
SET @i = @i + 1
If (@i!=10)
goto debut
Existe deux utilisation de CASE en T-SQL :
- Le CASE simple. Equivalente de Switch dans C
- Le CASE de recherche.
DECLARE @NmbE int, @NmbS varchar(20)
SET @NmbE = 42
SELECT @NmbS = CASE @NmbE
WHEN 10 THEN ‘Dix’
WHEN 24 THEN ‘Vingt Quatre’
Else ‘aucun’
End
Print ‘le nombre est ’+@NmbS
Les fonctions de base :
PRINT: est une instruction permettant d’afficher une ligne en sortie de procédure.
EXEC : est une instruction permettant de lancer une requête ou une procédure stockée.
USE : est une instruction permettant de préciser le nom de la base de données cible.
Définition de procédure Stockée:
CREATE PROCEDURE nomP
@parametre1 type,
@parametre2 type
AS Code Procédure
Créer une Procédure:
Create procedure GetProductId As Select
@prodid from product
Modifier une procédure:](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-35-320.jpg)

![37
OPEN MyCursor
• Lecture du premier enregistrement
Pour lire les données de la ligne courante et les associer aux variables du curseur il faut
utiliser l'instruction FETCH.
FETCH MyCursor INTO @Col1, @Col2, @Col3...
Atteindre le premier enregistrement du curseur
- Fetch First from nom_curseur into variable1, variable2,..
Atteindre l'enregistrement du curseur suivant celui en cours
- Fetch Next from nom_curseur into variable1, variable2,...
Ou Fetch nom_curseur into variable1, variable2…
Atteindre l'enregistrement du curseur précédent celui en cours
- Fetch Prior from nom_curseur into variable1, variable2,...
Atteindre le dernier enregistrement du curseur
- Fetch Last from nom_curseur into variable1, variable2,...
Atteindre l'enregistrement se trouvant à la position n dans le curseur
- Fetch absolute n from nom_curseur into variable1, variable2,...
Atteindre l'enregistrement se trouvant après n positions de la ligne en cours
- Fetch Relative Num_Ligne from nom_curseur into variable1, variable2,...
• Boucle de traitement:
WHILE @@fetch_Status = 0
BEGIN
traitement
-- lecture de l'enregistrement suivant
FETCH MyCursor INTO @Col1, @Col2, @Col3...
END
• Fermeture du curseur
CLOSE myCursor
• Libération de la mémoire
DEALLOCATE myCursor
Triggers (Déclencheurs)
Créer trigger
CREATE TRIGGER <nom_trigger> ON <table_ou_vue>
FOR | AFTER | INSTEAD OF [ INSERT ] [ , ] [ UPDATE ] [ , ] [DELETE]
AS
<code>
Supprimer trigger
DROP TRIGGER nom-trigger
Activer et désactiver trigger
Alter table nom_table
Disable /Enable trigger nom_trigger](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-37-320.jpg)


![40
Curseurs :
DECLARE
CURSOR my_cursor IS SELECT name FROM employees;
employee_name employees.name%TYPE;
BEGIN
OPEN my_cursor;
LOOP
FETCH my_cursor INTO employee_name;
EXIT WHEN my_cursor%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('Employee: ' || employee_name);
END LOOP;
CLOSE my_cursor;
END;
Triggers
CREATE OR REPLACE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT | UPDATE | DELETE} ON table_name
[FOR EACH ROW]
DECLARE
-- Déclaration de variables (optionnelle)
BEGIN
-- Corps du trigger
-- Code PL/SQL à exécuter
END;
Transactions
DECLARE
v_employee_id employees.employee_id%TYPE := 100;
v_salary employees.salary%TYPE := 60000;
BEGIN
-- Démarrer une transaction
INSERT INTO employees (employee_id, salary) VALUES (v_employee_id, v_salary);
-- Imaginons qu'une condition doit être vérifiée avant de valider
IF v_salary > 50000 THEN
-- Valider la transaction
COMMIT;
DBMS_OUTPUT.PUT_LINE('Transaction committed successfully.');
ELSE
-- Annuler la transaction
ROLLBACK;
DBMS_OUTPUT.PUT_LINE('Transaction rolled back.');
END IF;
EXCEPTION
WHEN OTHERS THEN
-- En cas d'erreur, annuler la transaction
ROLLBACK;
DBMS_OUTPUT.PUT_LINE('An error occurred, transaction rolled back.');
END;](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-40-320.jpg)

![42
d. Les notions NoSQL :
Une base de donnée contient une collection des documents.
Une collection est comme une table dans une BD relationnel sauf la collection n’a pas de
schéma et contient un ensemble des documents.
Un document est équivalent à un enregistrement dans une table, il est ce format Json et
caractérise par un champ _id c’est un champ obligatoire.
Une collection peut avoir des documents de même schéma ou bien des schémas différents
e. Les types des données :
Dans MongoDB, les documents sont stockés dans BSON, le format codé binaire de JSON, elle prend
en charge divers types de données à savoir :
String {"_id":"122", "prenom":"Amina"}
Integer: {"_id":"135", "age":22}
Double {"_id":"123","prixUni":14.25}
Boolean: {"_id":"123","statut":14.25}
Date {"Date_1": Date(),
"Date_2": new Date(),
"Date_3": "2023-12-12"}
Null {"_id":"123",
"prenom": null}
Données binaires {"_id":"123",
"BinaryValues": "10010001",}
Array: {"_id":"123",
"arrayValues": [ "1", "2", "3" ]}
ObjectId (Id d’objet): {"_id" :ObjectId("62dd128a1a19f3d7ecc6624f"),
"prenom" : "souad"}
MongoDB crée automatiquement un identifiant d’objet unique _id s’il n’est pas créé explicitement.
f. Les requête NoSQL :
Création de data base use myDB
Afficher la liste des DB show dbs
Afficher les collections d’une DB show collections
supprimer la DB courante db.nomcollection.drop()
supprimer une collection d’une DB db.dropDatabase()
Ajouter un document a une
collection
db.nomCollection.insert( {
"id" : "Sanaa",
"filiere" : "Dev Digital",
"niveau" : "2A",
"option":"Mobile" })
Espace de nom nomDB.nomCollections
Notion d’Embedding (Encapsulation) {
"_id": ObjectId("6347a9f7f0834a0011fa9f33"),
"name": "John Doe",
"email": "john@example.com",
"orders": [
{
"order_id": 1234,
"date": "2023-09-25",](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-42-320.jpg)
![43
"amount": 99.99
},
{
"order_id": 5678,
"date": "2023-10-01",
"amount": 149.99
}
]
}
Notion de Linking (Référencement) {
"_id": ObjectId("6347a9f7f0834a0011fa9f33"),
"name": "John Doe",
"email": "john@example.com"
}
{
"_id": ObjectId("8767a9f7f0834a0011fa9f57"),
"order_id": 1234,
"user_id": ObjectId("6347a9f7f0834a0011fa9f33"),
"date": "2023-09-25",
"amount": 99.99
},
{
"_id": ObjectId("8777a9f7f0834a0011fa9f59"),
"order_id": 5678,
"user_id": ObjectId("6347a9f7f0834a0011fa9f33"),
"date": "2023-10-01",
"amount": 149.99
}
g. Les requetés de manipulation NoSQL et fonctions :
Insertion db. NomCollection.insert({"cle1" :"valeur1","cle2" :"valeur2"})
Exemple :
db.Etudiants.insert({"prenom":"Amina","age":25},{"prenom":"aya","age":25})
db. NomCollection.insertOne({"cle1" :"valeur1"})
Exemple :
db.Etudiants.insert({"prenom":"Amina","age":25})
db. NomCollection.insertMany({"cle1" :"valeur1","cle2" :"valeur2"})
Exemple :
db.Etudiants.insert({"prenom":"Amina","age":25},{"prenom":"aya","age":25})
suppression db. NomCollection.drop()
db. NomCollection.deleteOne({"cle1" :"valeur1"})
db. NomCollection.deleteMany({"cle1" :"valeur1","cle2" :"valeur2"})
remplacement db. NomCollection.update(old, new)
Exemple :
db.Filieres.update({"_id":"ID","nom":"old"},{"_id":"ID","nom":"new","nbr":3}
)
db.Filieres.update(
{"_id":"ID", "intitule":"Infrastructure digitale"},](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-43-320.jpg)
![44
{"_id":"ID", "intitule":"Infrastructure digitale", "nbOptions":3} ,
{multi: true}
) //pour une modification multiple
modification db.Filieres.update(
{"intitule" : "Developpement digital"},
{$set: {"organisme": "OFPPT"}},
{multi: true}
)
sélection Sélectionner le 1ere élément :
db. NomCollection.findOne({"champ1":"val1","champ2":"val2"})
Sélectionner tous les éléments :
db. NomCollection.find({"champ1":"val1","champ2":"val2"})
Restriction Sélectionner tous les éléments et affiche que champ1 et champ2 :
db. NomCollection.find( {},{"champ1":1,"champ2":1})
Sélectionner un seul élément et affiche que le champ1 et masquer le _id:
db. NomCollection.findOne( {},{"champ1":1, "_id":0})
Projection selection = {"champ1": "val1","champ2":"val2"}
projection= {"champ1": 1,"_id":0}
db. NomCollection.find( selection, projection)
Fonction distinct db. NomCollection.distinct("champ1")
Fonction count db. NomCollection.find().count()
db. NomCollection.find({"champ1":"value"}).count()
Fonction limit db. NomCollection.find ({},{"champ1":val1,"_id":0}).limit(2)
Fonction sort db. NomCollection.find ({},{"champs1":value1,"_id":0}).sort()
db.NomCollection.find({},{"champs1":value1,"_id":0}).sort({"champ1":-1,})
h. Les opérateurs NoSQL :
égal à : = $eq Exemple:
selection = {"note":{"$gte":10.00}}
db.Etudiants.find(selection,{"nom":1,"prenom":1,"_id":0})
supérieur à : > $gt
supérieur ou égal à : >= $gte
inférieur à : < $lt
inférieur ou égal à : <= $lte
différent de : ≠ $ne
Appartient à la liste $in Exemple:
selection = {"option":{"$in":["A","B"]}}
db.Etudiants.find(selection,{"nom":1,"prenom":1,"_id":0})
N’appartient pas à la liste $nin](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-44-320.jpg)
![45
ET Logique $and Exemple:
s = { "$or": [ { "note" : { "$gte" : 10 } }, {"option":"A"} ] }
db.Etudiants.find(s,{"nom":1,"prenom":1,"_id":0})
OU Logique $or
Not (OU Logique) $nor
Teste la présence ou non
d’un champ
$exists Exemple:
selection = { "option": {$exists : false }}
db.Etudiants.find(selection,{"nom":1,"prenom":1,"_id":0})
Les Opérateurs
d’agrégation :
Ce calcul s’effectue avec la fonction aggregate() qui prend en paramètre
un tableau d’opérations (pipeline).
L'output de chaque opération du pipeline sera l'input de l'opération
suivante, pour produire une nouvelle collection.
Chaque étape du pipeline est définie par un opérateur passé à la
commande d’agrégation suivante.
db. NomCollection.aggregate([operateur1,operateur2,..])
Opérateur d’agrégation :
$match
Filtrer les documents de la collection suivant la sélection fournie à
l’opérateur $match
db. NomCollection.aggregate([{$match: {selection}}])
example:
db.Etudiants.aggregate([{$match: {"filiere.intitule" : "arabe" }}])
Opérateur d’agrégation :
$group
Permet d’effectuer des regroupements et faire des opérations
d'accumulation sur les documents (GROUP BY en SQL).
Le champ de regroupement est indiqué par id.
On peut faire tous les calculs d’agrégats classique en utilisant les fonctions
d’agrégation suivantes: $sum (somme), $avg (moyenne), $min
(minimum), $max (maximum)
db. NomCollection.aggregate ([ {$group: {_id: $champ_regroupement,
variable: { fonctionAggregation : $champ }, ...} } ])
example:
db.Etudiants.aggregate ([
{$group: {_id: "$filiere.intitule", total : {$sum:"$note"}}} ])
db.Etudiants.aggregate ([
{$group: {_id: "$filiere.intitule", maximum : {$max:"$note"}}} ])
db.Etudiants.aggregate([
{$group: {_id: "$filiere.intitule", maximum :{$max:"$note"}}},
{$sort: { maximum:1}} ])](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-45-320.jpg)
![46
i. Les requetés via python:
Pour travailler les requetés NoSQL dans MongoDB avec python il faut installer la bibliothèque
PyMongo. C’est une librairie Python native.
Etape1 : vérification de l’installation de Python avec la commande : python –version
Etape2 : vérification de l’installation de pip avec la commande pip –version
Etape3 : saisir la commande suivante dans un terminal (invité de commande par exemple)
pip install pymongo
Etape4 : Créer la connexion avec le serveur MongoDB Pour effectuer cette connexion on utilise
MongoClient, qui se connecte, par défaut, à l'instance MongoDB s'exécutant sur
localhost:27017. Pour lancer la commande : mongod
Etape5 : en lance URL suivant : mongodb://localhost:27017/
Etape6 : lancer la commande : python
Etape7 : lancer le code suivant pour vérifier la connexion:
from pymongo import MongoClient
# Connexion au serveur MongoDB local
client = MongoClient("mongodb://localhost:27017/")
# Sélectionner ou créer une base de données
db = client["nom_de_votre_base_de_donnees"]
# Affichage des collections disponibles
print(db.list_collection_names())
Etape8 : Commencer à pratiquer les requetés, les requetés en le syntaxe suivante :
Client.baseDonnees.nomDeLaCollection.requete()
db.Stagiaires.find()
Retourne un curseur (type Cursor) sur les données
resultat = db.Etudiants.find()
for r in resultat[:2]:
print(r)
Pour afficher les données et faut parcourir le curseur](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-46-320.jpg)
![47
selection={}
selection["option"]="Mobile"
resultat =db.Etudiants.find(selection)
for i in resultat[:]:
print(i)
projection={"nom":1,"prenom":1,"_id":0}
selection={}
selection["filiere.intitule"]="DD"
r =db.Etudiants.find(selection,projection)
for i in resultat[:]:
print(i)
r = db.Etudiants.find().sort("nom",-1)
for i in r[:]:
print(i)
for k,v in
db.Etudiants.index_information().items():
print("index:" ,k, "valeur :",v,"n")
Retourne la liste des index de la collection
db.Etudiants.create_index("i1") Création d’un index
db.Etudiants.drop_index("i1") Suppression d’un index
insert_one() - Insertion d’un seul
document
insert_many() - Insertion d’une liste de
documents](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-47-320.jpg)
![48
delete_one() - Suppression d’un
document
delete_many() - Suppression d’une
liste de documents
update_one() - Modification d’un
document
update_many() - Modification d’une
liste de documents
resultat = db.Etudiants.aggregate([
{"$group":{"_id":"$filiere.intitule",
"moyenne":{"$avg":"$moy1A"}}
}])
for i in resultat:
print(i["moyenne"],"moyenne de ",
i["_id"])
j. La sécurité des accès :
Pour créer un utilisateur sur une base de données, il faut spécifier :
• Le login
• Le mot de passe
• Et le (les) rôles à lui attribuer
Pour les rôles existent :
dbAdmin : Administrateur de la base de données.
dbOwner : Combine les éléments suivants : readWrite, dbAdmin userAdmin
read : Lire les données sur toutes les collections.
readWrite : les privilèges du rôle lecture , on a le droit d'écriture.
userAdmin : créer et modifier les utilisateurs et les rôles sur la DB actuelle
Exemple :
o db.getUser(user) : Pour afficher les détails d’un user.
o db.dropUser(user) : Pour supprimer un user.
o db.auth(<login>,<motDePasse>) - db.auth("UserAdmin","password") : Pour
s’authentifier à la base avec le compte d’un utilisateur
use Examples
db.createUser( {
user: "UserAdmin",
pwd: "password" ,
"roles" : [{ "role" : "userAdmin",
"db" : "Examples" }]
})](https://image.slidesharecdn.com/merisesqlplusdoc-241019155010-4af8b49a/85/Merise-SQL-SQL-Procedural-MySQL-TSQL-SQL-Server-PLSQL-Oracle-NOSQL-MongoDB-48-320.jpg)


















































