Télécharger en tant que PDF, PPTX




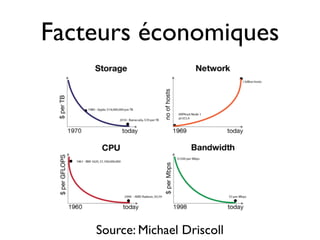
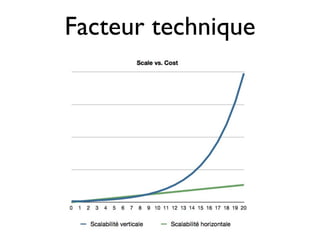












Le document traite du défi croissant du big data, caractérisé par une explosion de données désorganisées et incohérentes. Il aborde également les raisons pour lesquelles l'open source est essentiel pour gérer ce big data, soulignant son rôle dans l'innovation et la scalabilité. Enfin, il présente les initiatives du gt pour développer l'écosystème open source en Île-de-France et les grands défis à relever dans ce domaine.

























![[Big] [Open] Data [As a Service]](https://cdn.slidesharecdn.com/ss_thumbnails/awtsmartournai11122014-141211031507-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



































