Télécharger pour lire hors ligne


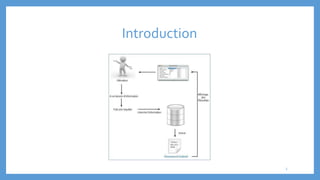
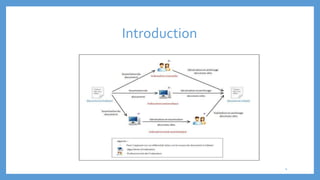





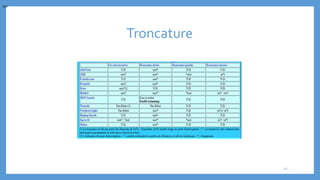
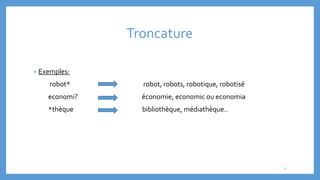

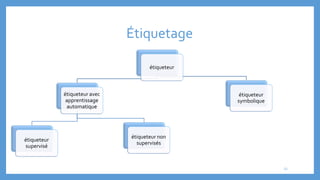
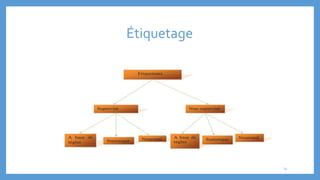





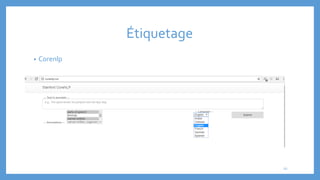
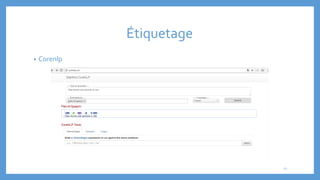

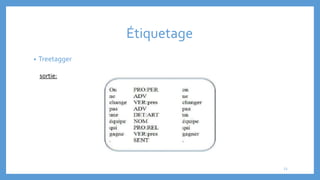
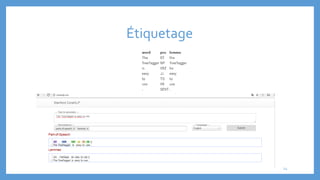




Le document traite des processus fondamentaux du traitement du langage naturel, notamment la tokenisation, la racinisation, la troncature, l'étiquetage morphosyntaxique et la lemmatisation. Chaque processus est défini et illustré par des exemples, mettant en lumière leur importance dans l'analyse des textes. Enfin, il résume différents outils et méthodes appliqués à ces techniques pour faciliter la compréhension et l'application du traitement automatique de la langue.















































