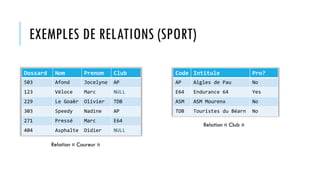
Téléchargé 70 fois




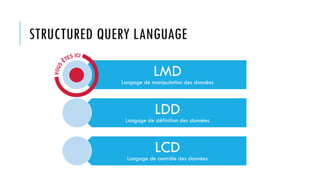
![LANGAGE DE MANIPULATION DE DONNÉES
Sous-ensemble du SQL utilisé pour ajouter, consulter, modifier, et supprimer des
données des tables existantes
Correspond aux commandes SQL : INSERT, SELECT, UPDATE, DELETE
Syntaxe générale d’une requête pour consulter des données :
SELECT attributs -- ce que l'on cherche
FROM relations -- où on cherche
[WHERE condition] -- avec quelles conditions
[GROUP BY attributs] -- en utilisant
[HAVING condition] -- des sous-ensembles
[ORDER BY attributs] -- résultat dans quel ordre](https://image.slidesharecdn.com/sql-170504153653/85/Introduction-au-langage-SQL-6-320.jpg)







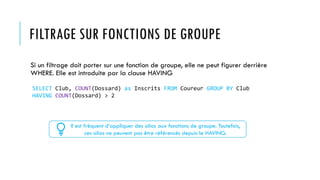



Le document présente une introduction au langage SQL, expliquant son rôle dans l'exploitation des bases de données relationnelles. Il détaille la syntaxe des requêtes SQL, y compris la manipulation de données, le filtrage, les jointures, et les fonctions de groupe. En fin de compte, le SQL est décrit comme un langage déclaratif, où la gestion des requêtes est optimisée par le système de gestion de base de données relationnelles.


















































![PowDroid: Energy Profiling of Android Applications (ASE 2021 [Workshop] SUSTA...](https://cdn.slidesharecdn.com/ss_thumbnails/sustainse2021-211119135814-thumbnail.jpg?width=640&height=640&fit=bounds)










![Syntaxe concrète des DSL en IDM [avec Xtext]](https://cdn.slidesharecdn.com/ss_thumbnails/dsl-140513103904-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
