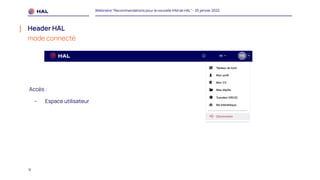
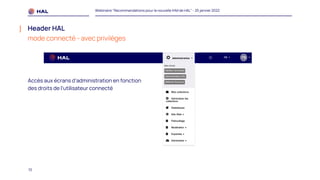
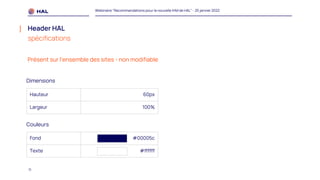
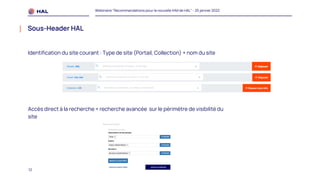
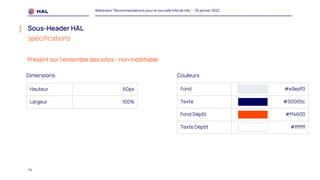
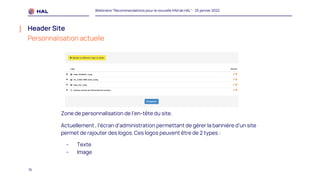
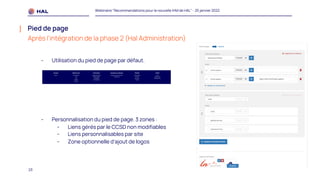
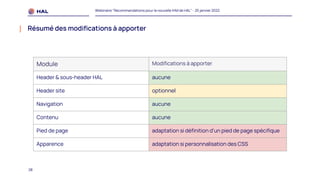
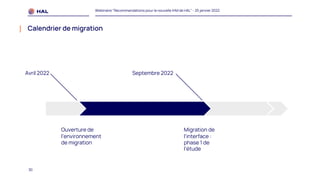
Le webinaire du 25 janvier 2022 a présenté des recommandations pour la nouvelle interface homme-machine (IHM) de HAL, visant à améliorer l'expérience utilisateur et à simplifier l'accès aux services. Il a abordé les méthodologies de co-conception, l'intégration des portails, et les spécifications des éléments de navigation et de contenu. Un plan de migration a été établi, avec un calendrier et un soutien prévu pour accompagner les administrateurs lors de la transition.