Télécharger en tant que PDF, PPTX








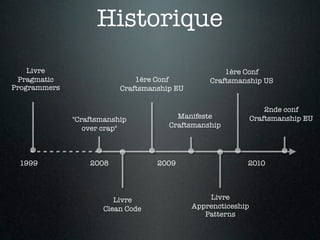
















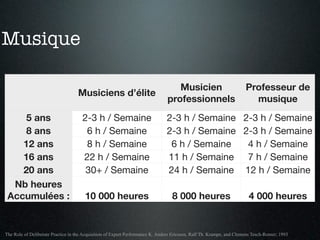



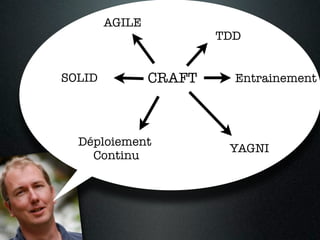










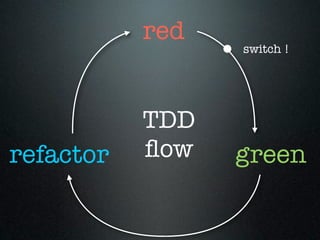










Le document traite du concept de software craftsmanship, mettant l'accent sur l'importance des compétences en programmation et des pratiques techniques au sein des équipes de développement agile. Il évoque l'évolution historique du mouvement, ainsi que des principes et méthodes pour améliorer les compétences des développeurs à travers la pratique délibérée. L'auteur souligne que la maîtrise en développement logiciel nécessite un apprentissage continu et un regard critique sur les processus en place.






![LRA_presentation2011[1]](https://cdn.slidesharecdn.com/ss_thumbnails/7ce27e31-49dc-419e-999b-34f789c8bb05-141209135439-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































