Téléchargé 338 fois













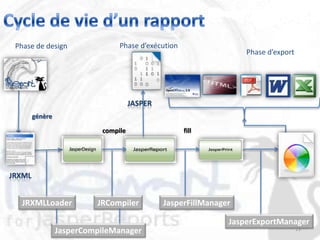
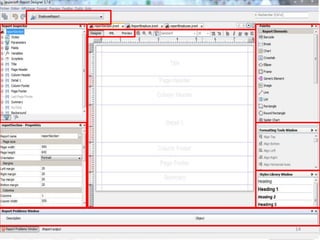
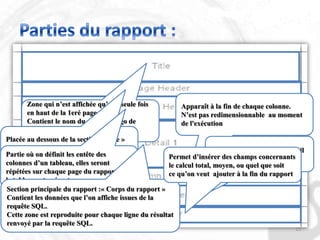
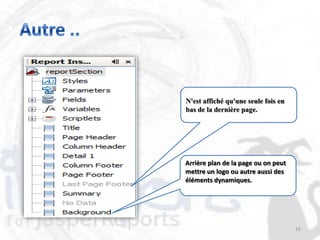
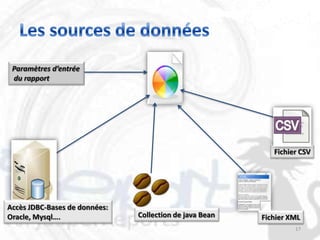













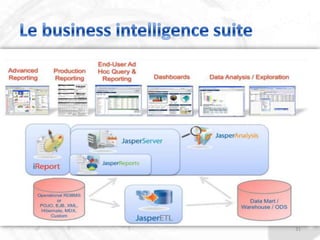



Le document décrit les besoins et objectifs associés à un outil de reporting, notamment JasperReports et son designer, iReport. Il présente les fonctionnalités de ces outils, telles que la représentation graphique des données, l'extraction d'informations et la gestion de rapports complexes, tout en soulignant les avantages et inconvénients de leur utilisation. En outre, il retrace l'historique de développement de JasperReports et les technologies sur lesquelles il est basé.



























































