Téléchargé 50 fois
![1
#yTechParis
Machine Learning sur hybris
ecommerce
[Y]recommender
Présenté par Yawo KPOTUFE
Hybris expert / Solution architect](https://image.slidesharecdn.com/yrecommenderytech-151028213229-lva1-app6891/85/Yrecommender-machine-learning-sur-Hybris-1-320.jpg)



















![22
#yTechParis
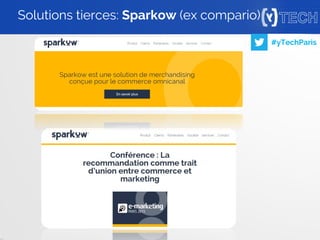
Row key construite à partir des infos de chaque event
3 columns families (cf) définies: u,p, et c (user, product et cart)
Chaque row peut définir les champs de ses cfs
Données vérifiables via le shell hbase (requête de scan)
Script shell Yrecommender:
> transforme les derniers business events, les charge dans Hbase et les archive:
https://github.com/yawo/yreco/blob/master/scripts/tsv.extract.sh
[Y]recommender: notre table ‘view’
Rows Column families
u (user) p (product) c (cart/order)
Row key • id
• name
• …
• id
• name
• …
• id
• total
• …](https://image.slidesharecdn.com/yrecommenderytech-151028213229-lva1-app6891/85/Yrecommender-machine-learning-sur-Hybris-22-320.jpg)


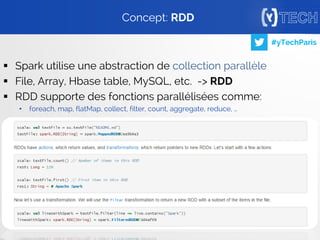


Quelques Algorithmes: FP-Growth](https://image.slidesharecdn.com/yrecommenderytech-151028213229-lva1-app6891/85/Yrecommender-machine-learning-sur-Hybris-27-320.jpg)










Le document présente une synthèse d'une présentation sur l'application du machine learning dans l'e-commerce avec Hybris. Il couvre les concepts de merchandising, le traitement et le stockage des données via des événements commerciaux, ainsi que l'utilisation de l'algorithme de filtrage collaboratif pour fournir des recommandations. Enfin, il aborde les infrastructures de traitement de données, telles qu'Apache Spark et HBase, utilisées pour développer le système de recommandation 'yrecommender'.

















![[Sildes] plateforme centralisée d’analyse des logs des frontaux http en temps...](https://cdn.slidesharecdn.com/ss_thumbnails/sildesplateformecentralisedanalysedeslogsdesfrontauxhttpentempsreldansunmilieuvirtualis-160429150553-thumbnail.jpg?width=640&height=640&fit=bounds)



























