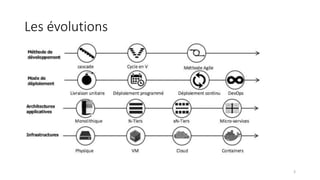
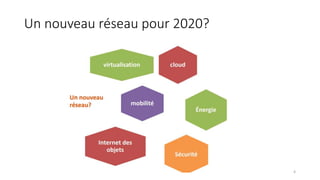
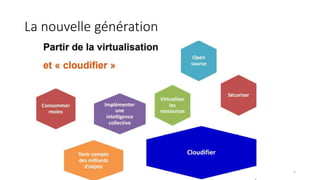
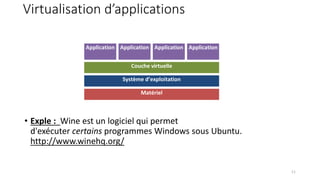
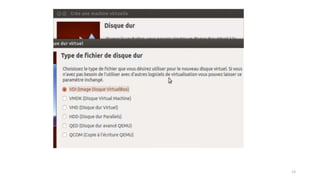
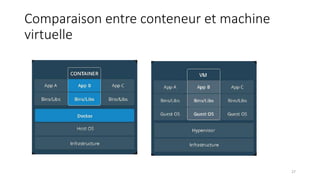
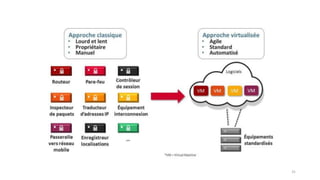
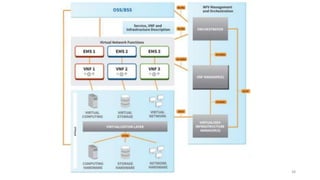
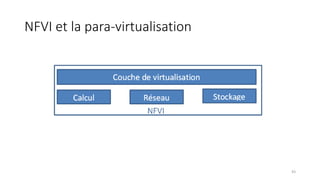
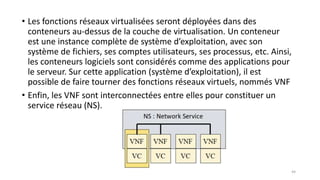
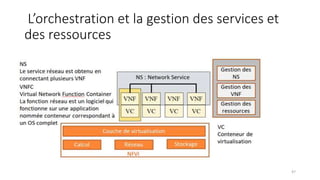
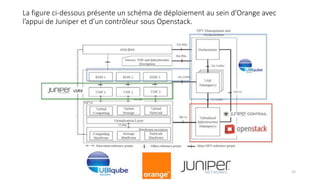
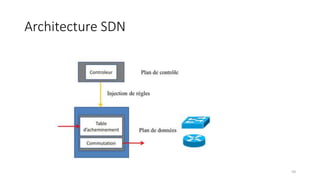
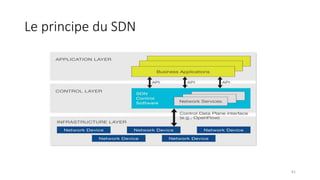
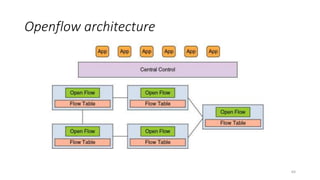
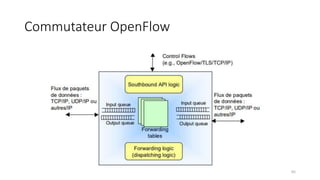
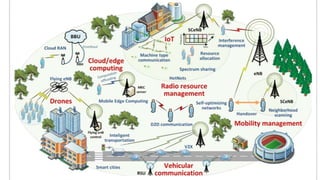
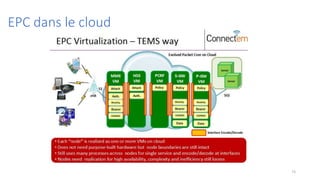
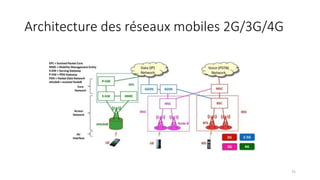
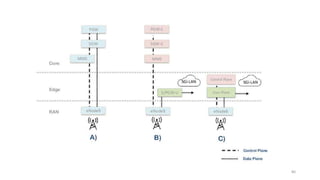
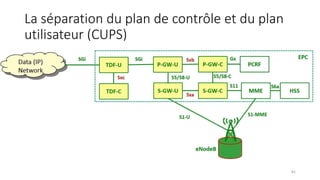
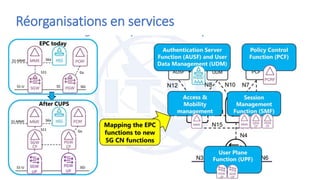
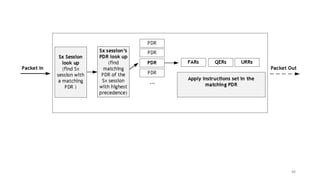
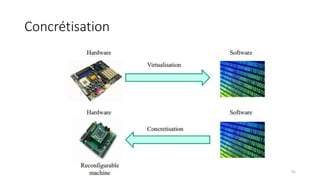
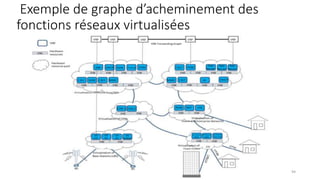
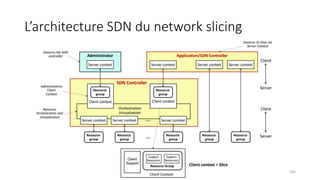
La virtualisation permet de faire fonctionner plusieurs systèmes d'exploitation sur une même machine physique, optimisant ainsi l'utilisation des ressources. Elle se divise en plusieurs types, y compris la virtualisation de serveurs, d'applications et de stockage, chacun ayant ses spécificités et avantages. La virtualisation des fonctions réseau (NFV) offre également de nouvelles solutions pour la gestion des services télécom, en se basant sur des infrastructures matérielles standards et des logiciels programmables.