Télécharger en tant que PDF, PPTX


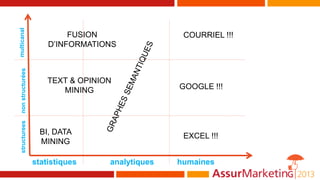

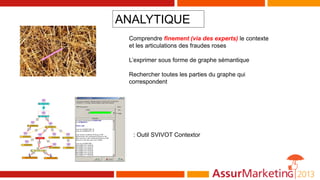
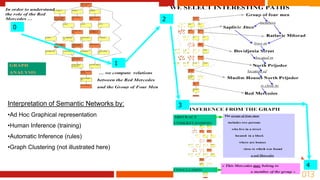
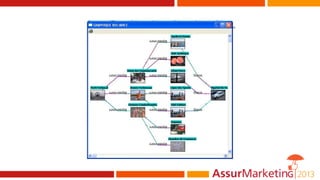


Le document aborde l'utilisation des big data pour la détection des fraudes, en examinant les types d'informations et de traitements impliqués, notamment à travers des techniques statistiques et analytiques. Il souligne l'importance de l'apprentissage automatique et du clustering pour identifier et analyser différentes catégories de fraudes. Enfin, il mentionne des outils et références pour approfondir le sujet et développer des approches sémantiques pour la représentation des données de fraude.

























































