Ce mémoire présente une étude sur le développement, l'automatisation et l'optimisation d'un data mart en l'absence de logiciels spécialisés, afin de fournir des indicateurs de performance. Il aborde les problématiques liées à la gestion des données et à l'information, ainsi que les méthodes d'implémentation d'un data mart. Le document est divisé en deux parties, l'une axée sur l'état de l'art et l'autre sur la méthodologie employée.

































![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
39
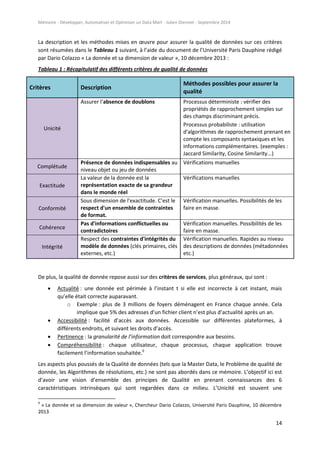
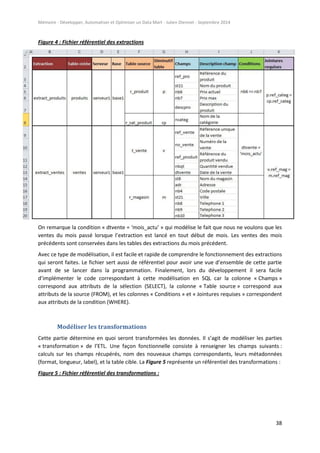
Comme pour la phase précédente, ce type de modélisation offre une vision d’ensemble du
fonctionnement de la partie transformation. Dans notre exemple, on remarque plusieurs choses :
« nb6/100 » car on fait l’hypothèse que le prix est de base en centimes dans les tables
sources, on le retraite ainsi pour obtenir un réel sur 9 chiffres, dont 2 pour les centimes (réel
9.2). Exemple 142325 se transforme en 1 423,25. La devise n’est pas précisée par contre.
« dtvente » est divisé en deux variables cibles « date_vente » et « time_vente ». La première
récupère la date au format « jour/mois/année » et la deuxième récupère l’heure au format
« 23:59:59 » « pour 23h, 59min et 59sec.). On verra dans la partie « Développement »
comment cela peut être fait techniquement.
Certaines longueurs de caractères ont des « [ ] ». Ceci signifie que la longueur est variable : le
champ peut récupérer n’importe quelle chaine de caractères d’une longueur inférieure ou
égale à la valeur affichée entre crochets. Si la longueur dépasse, la chaîne est tronquée.
Les nouveaux champs ont des noms plus parlants et leurs labels sont compréhensibles pour
le métier.](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-39-320.jpg)

![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
43
De plus, lorsque les reportings demandent un retraitement (manuel ou automatique), il est
important de référencer ces manipulations dans un mode opératoire, par exemple : « Pour le
reporting 1, copier les données vers tel template, puis lancer telle macro, et l’envoyer à Alice
Lécheveux et Sandra Housse ».
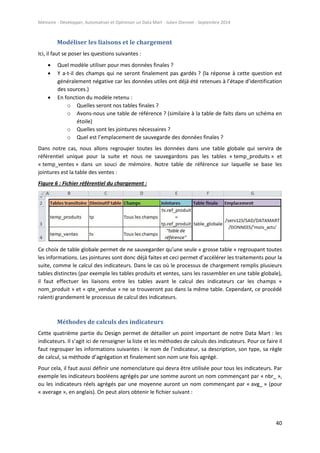
Design physique
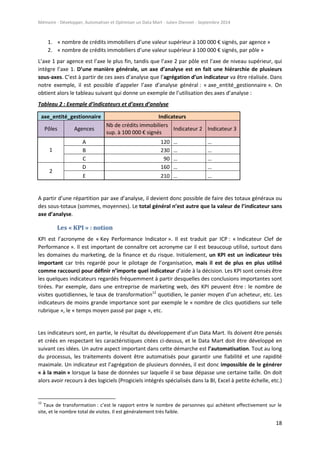
Finalement, la dernière partie du Design consiste à modéliser la structure physique qui contiendra
nos programmes, nos données et nos résultats. Pour cela, il est possible de créer un diagramme style
organigramme qui référence les dossiers et sous-dossiers de notre arborescence :
Figure 9 : Diagramme sur la structure physique de l’environnement :
Nous rappelons que nous nous basons dans un environnement type répertoires (sous UNIX) qui
permet de sauvegarder dans chaque dossier (AXES_ANALYSE, FONCTIONS, etc.) des éléments
spécifiques du Data Mart, que ce soit une table de données, un programme SAS ou un résultat Excel.
Un fichier descriptif doit accompagner ce diagramme pour expliquer ce que contiendra chaque
répertoire. Par exemple dans notre cas, le répertoire
« /serv123/SAD/DATAMART/PROGRAMMES/EXTRACTIONS » se chargera de regrouper tous les
programmes d’extraction sous la forme [nom_extraction].sas, le répertoire
« /serv123/SAD/DATAMART/DONNEES/[MOIS] » contiendra la table_globale selon le mois de sa
création, etc.](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-43-320.jpg)
![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
44
Troisième phase : Construction, spécifications détaillées et cahier de
recette
Cette phase permet de construire le « squelette » du processus, c’est à dire : les fichiers qu’il va
utiliser (programmes et reportings) et l’environnement dans lequel il va opérer. Une documentation
des spécifications détaillées doit aussi être faite en parallèle ainsi qu’un cahier de recettes qui
permettra de tester chaque fonction (cf. partie « Cinquième phase : Recette »).
Construction de l’environnement
La première partie est la construction de l’environnement. Comme vu dans le « Design physique », il
s’agit ici de créer tous les dossiers et sous-dossiers qui contiendront les éléments du Data Mart (cf.
Figure 9).
En UNIX il est simple de générer l’arborescence à l’aide de la commande « mkdir [nom_répertoire] »
qui doit être utilisée séquentiellement pour tous les répertoires et sous-répertoires qui seront créés.
Les dossiers (…)/[MOIS] sont créés dynamiquement (cf. partie suivante « Script »).
Création des fichiers programmes et reportings
Programmes
Une fois l’environnement créé, il faut créer tous les fichiers programmes et leurs fonctions (sans pour
autant les développer pour le moment). Pour cela, il faut se poser les questions suivantes :
Quels sont les programmes principaux dont je vais avoir besoin ?
Comment les découper en sous-programme pour faciliter la lecture et le développement, et
favoriser l’évolutivité.
Quelles seront les fonctions associées à mes programmes ? (Insérer un commentaire pour
chaque fonction pour décrire son utilité.)
Quelles sont leurs typologies (variables en entrée, variables en sortie) ?
Quels seront finalement mes enchaînements de programmes et de fonctions ?
Par exemple, nous savons que nous aurons besoin d’un programme qui gère les extractions
(première partie de notre Data Mart). Pour ce faire il est possible de créer plusieurs programmes
pour chaque extractions « [nom_extraction].sas » qui se chargeront de lancer la requête sql associée
à l’extraction, et un macro-programme « lancer_extractions.sas » qui va lancer toutes les extractions
séquentiellement selon la liste qu’on lui aura renseigné dans une fonction. Enfin, ce programme
« lancer_extractions.sas » se trouvera appelé par le programme mère « prog_general.sas » qui va
exécuter à la suite tous les macro-programmes liés à chaque fonction principale du Data Mart
(Transformation, Chargement, Indicateurs, etc.).
Lorsque des modifications surviendront par exemple pour implémenter un nouveau périmètre, de
nouveaux indicateurs, etc., il sera ainsi clair et intuitif d’aller rajouter des petits programmes
connectés aux macro-programmes.
Tout ceci doit être documenté dans la partie suivante « Documentation détaillée des futurs
programmes ».](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-44-320.jpg)
![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
45
Reportings
Un élément qui peut être fait en parallèle à la construction des programmes et fonctions est la
création des Reportings. Généralement, ce n’est pas le même acteur de l’équipe projet qui réalise ce
travail, mais il n’en reste pas moins en relation active avec les développeurs pour connaître
exactement la forme des données en sorties. Une fois connue, il est possible de développer les
templates de reportings qui serviront à accueillir les sorties Excel données par les procédures SAS.
Dans notre cas, un template de reporting est un fichier Excel qui prend en entrée des données sur
une page et qui s’en sert pour remplir un tableau esthétique, associé à des graphiques et statistiques,
sur une autre page. Le tableau a généralement été créé par les acteurs métiers, c’est eux qui nous
fournissent la mise en forme qu’ils souhaitent recevoir et les analyses qui iront avec. Il s’agit donc ici
de faire l’intermédiaire entre ce que les développeurs créés dans le fond et ce que les acteurs
attendent dans la forme.
Documentation détaillée des futurs programmes
Cette partie concerne la documentation écrite pour détailler le fonctionnement des programmes et
fonctions.
Comme dans tout projet d’une manière générale, il faut rédiger les spécifications. En informatique,
et donc ici en Business Intelligence, il faut différencier les spécifications fonctionnelles des
spécifications détaillées. Les spécifications fonctionnelles ont déjà été rédigées d’une certaine
manière lors de la phase de Design : tous les processus ont été expliqués fonctionnellement. Tandis
que les spécifications détaillées doivent être rédigées lors de la création des programmes et des
fonctions, et revues si besoin lors du développement.
Les spécifications détaillées servent de référentiel technique sur le fonctionnement du processus. Ce
document répertorie la liste des programmes, des fonctions, de leurs typologies et des liaisons
processus à un autre. Dans notre cas, il a été rédigé sous format texte, avec une partie pour chaque
programme et des sous parties pour les sous programmes (exemple « 2.1 lancer_extraction » et
« 2.1.[1] [nom_extraction] »). Une description du fonctionnement du programme est faite et ensuite
la liste des fonctions qu’il incorpore est énoncée sous forme d’un tableau, avec des informations sur
les variables en entrées, son fonctionnement, et les variables en sorties.
Cahier de recette
Finalement, le cahier de recette doit aussi être rédigé en parallèle : il permet d’avoir une procédure
complète à suivre pour la phase de recette lorsqu’il s’agira de tester toutes les fonctions du
programme mais aussi de valider les résultats obtenus avec le métier.
Le cahier de recette met en place une stratégie pour la recette fonctionnelle. Dans notre cas, deux
résultats devaient être validés avec le métier : les listes de données et les reportings d’indicateurs. Il
s’agit donc ici de se baser sur la liste des besoins fonctionnelles énoncés par les acteurs métiers, et
d’en faire une liste de recette à complèter.](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-45-320.jpg)
![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
46
Quatrième phase : Développement
Script
Un « script » est un diminutif pour parler des programmes qui sont écrits en « langage de script ».
Des langages de script connus sont par exemple : JavaScript, PHP, Python, etc. Mais aussi, et surtout
dans notre cas, les langages de script sont utilisés sous UNIX (exemple : bash, sh, ksh, etc.). C’est avec
ces derniers que la solution a été développée. Ils permettent de regrouper une série de commandes
reconnues par l’environnement UNIX et de les exécuter rapidement. Ils peuvent ainsi lancer des
programmes SAS. Dans notre cas, un script peut exécuter les actions suivantes (cf. ANNEXE 1) :
1. Récupérer la date du jour via une fonction prédéfinie
2. Créer une variable qui contient le mois actuel au format AAAAMM. Exemple 201408 pour
août 2014
3. Récupérer dans des variables les adresses des répertoires utiles. Exemple
« /serv123/SAD/DATAMART/DONNEES »
4. Créer les répertoires du mois dans DONNEES et SORTIES avec la commande « mkdir
(…)/[MOIS] »
5. Exécuter le programme SAS principal et sauvegarder sa log, datée du jour.
6. Informer que le programme est terminé
Lorsque le script est créé, un simple appel de celui-ci dans un terminal de commande UNIX permet
de lancer toutes les actions qui y sont contenues.
Un aspect très important des scripts vient de leur automatisation (lancement automatique depuis un
« ordonnanceur »). Il est détaillé dans la partie « Automatisation ».
SAS
SAS est un langage de programmation qui permet le traitement de données rapide et automatique. Il
permet ainsi de gérer des bases de données, de faire des statistiques et de générer des reportings, de
manière dynamique et intuitive pour un informaticien grâce à son langage « macro » (cf. partie
« Macros variables et macros fonctions »).
Inclusions de sous-programmes
Les inclusions de sous-programmes permettent d’imbriquer plusieurs programmes les uns à la suite
des autres de manière hiérarchique. On parle ainsi de « modularité des programmes ». De ce fait, au
lieu de tout développer dans un seul programme, on peut fragmenter le code en plusieurs morceaux
pour instaurer une cohérence dans nos programmes et ainsi obtenir une facilité de lecture et
d’écriture (cf. partie « Optimisation pour la lecture et l’écriture »). Cette facilité se retrouve aussi
dans la capacité d’évolution du programme (cf. partie « Sixième phase : Maintenance et
évolutions »).
Pour ce faire, il faut utiliser la ligne de code suivante : « %include ‘’[nom_programme].sas’’; ». Par
exemple, au début du programme « prog_général.sas », il est possible d’inclure le programme
« lancer_extractions.sas » et ce dernier va à son tour inclure plusieurs sous-programmes
« [nom_extraction].sas ». L’exécution va alors commencer depuis le premier programme, puis passer
au sous-programme suivant et commencer par le niveau le plus fin puis remonter, et ainsi de suite](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-46-320.jpg)
![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
47
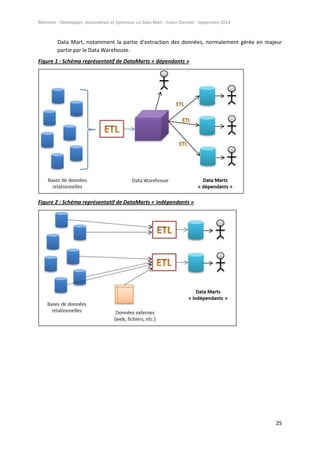
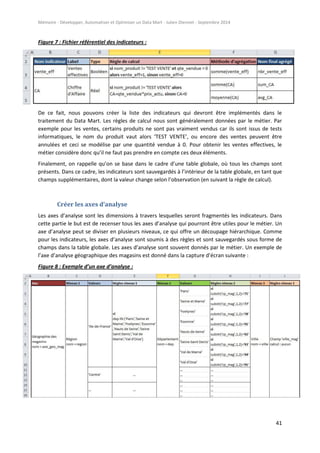
dans l’ordre d’appel des « include ». La figure suivante montre par exemple l’exécution de notre
programme avec l’ordre numéroté :
Figure 10 : Exemple de diagramme d’exécutions encapsulées des programmes :
On remarque donc les aller-retours entre les programmes et leurs sous-programmes : quand un
sous-programme a fini son exécution, il revient au programme parent et poursuit l’exécution, et ainsi
de suite jusqu’à finir l’exécution totale du programme global (exécution « N »).
Macros variables et macros fonctions
Les macros variables sont des variables qui peuvent être utilisées à n’importe quel endroit dans
n’importe quel programme une fois qu’elles ont été créées lors d’une exécution. D’après l’ANNEXE
2, si une macro variable « liste_indics » est créée dans le programme « chargement.sas », alors elle
sera réutilisable par le programme « axes_analyse.sas ». Cet élément permet de n’effectuer qu’une
seule fois certains traitements pour pouvoir les réutiliser par la suite en tant que référentiels (la liste
des tables issues de l’extraction doit rester la même pendant la transformation et le chargement par
exemple). De plus, elles sont dynamiques car elles ne requièrent pas de gestion de la mémoire, et
n’ont pas de type défini ce qui permet de leur attribuer n’importe quelle valeur selon la situation
(chaîne de caractères, entier, booléen, etc.). Elles peuvent être utilisées dans le nom d’une table, le
nom d’un champ, le nom d’une fonction, et beaucoup d’autres cas, ce qui les rend simples et
« légères » à utiliser. Les macros variables s’initialisent avec le code « %LET [variable]=[valeur] » et
s’utilisent avec le signe « & » et un « . » à la fin (exemple : « &liste_indics. »).
Les « macros fonctions » sont les fonctions que nous créons nous même pour automatiser les
traitements (cf. partie « Automatisation »). De même que pour les macros variables, les macros
fonctions peuvent être utilisées à n’importe quel endroit d’un programme à partir du moment où
elles sont définies. Les macros fonctions se définissent par le code « %MACRO [nom_macro]; (…);
%MEND [nom_macro]; » et elles s’utilisent avec le signe « % » (exemple : « %indicateurs »).
Dans notre cas, nous avons utilisé un programme « initialiser_macro_variables.sas » au tout début du
processus qui permet d’initialiser toutes les macros variables importantes pour la suite. D’autres sont](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-47-320.jpg)

![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
49
Exemple :
PROC SQL;
connect to oracle as accora (user=&user. password=&pass. path=&path.);
CREATE TABLE lib.vente_&dtjour.
AS select * from connection to accora
(
SELECT *
FROM &source..ventes
);
disconnect from accora;
QUIT;
PROC SORT : Permet de trier une table SAS selon un ou plusieurs champs, et de supprimer
les doublons selon un ou plusieurs champs discriminants.
Exemple :
PROC SORT DATA=lib.vente_&dtjour. NODUPKEY;
BY ref_vente no_vente;
RUN;
PROC MEANS : Permet de sortir les statistiques basiques de certains champs d’une table
(moyenne, médiane, écart-type, etc.).
PROC PRINT : Permet d’afficher une table sous forme de tableau. Des options comme
« LABEL » permettent d’utiliser les labels des variables pour l’affichage.
Exemple :
PROC PRINT DATA=lib.vente_&dtjour. LABEL;
RUN;
Dans nos programmes, la PROC SQL est utilisée pour les extractions des bases de données sources et
pour les agrégations des indicateurs suivant les axes d’analyse (avec l’instruction « group by » d’SQL).
La PROC SORT est utilisée à plusieurs endroits pour, par exemple, trier une table avant une jointure
(cf. partie « Optimisation »), ou supprimer les doublons des tables afin d’améliorer la qualité de
donnée et supprimer les biais des indicateurs. Enfin, les PROC MEANS et PROC PRINT sont utilisées
pour les reportings.
Reportings
Finalement, la dernière fonctionnalité essentielle qu’offre SAS pour notre Data Mart est la génération
des reportings. Cette opération est effectuée tout à la fin du processus global par l’utilisation d’une
fonction spécifique : « ODS TAGSETS.EXCELXP ». C’est une alternative à la fonction d’exportation
classique de SAS (PROC EXPORT) qui permet de sortir les résultats directement sous format Excel.
La méthode qui est utilisée dans notre étude est la « PROC PRINT » à l’intérieur de la fonction « ODS
TAGSETS.EXCELXP » pour « imprimer » les résultats dans le fichier Excel. Il est aussi possible de
renseigner l’emplacement d’exportation de ce fichier résultat. Ici, tous nos fichiers résultats du mois
se trouvent dans le répertoire « /serv123/SAD/DATAMART/SORTIES/[MOIS] ».](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-49-320.jpg)






![Mémoire - Développer, Automatiser et Optimiser un Data Mart - Julien Diennet - Septembre 2014
56
DISCUSSION
Cette partie permet de discuter des hypothèses, de la méthode employée et des résultats obtenus.
Elle sert à prendre du recul pour faire le bilan de ce qui a été fait et penser ce qui pourrait être
changé ou amélioré.
Comme vu dans la partie « Résumé », nous avons fait des hypothèses sur l’entreprise, le type de Data
Mart, la taille et la complexité des données, l’environnement de développement, les outils utilisés,
les résultats souhaités et les accès aux données. Il est cependant possible d’élargir ces hypothèses
selon notre cas de figure :
Entreprise : n’importe quelle taille tant que les secteurs d’activité et leurs bases de données
sont clairement définis.
Gestion du Data Mart : peut être fait par n’importe quelle équipe qui a les compétences
nécessaires dans le traitement de données.
Type de Data Mart : dépendant ou indépendant.
Taille des données : n’importe quelle taille moyenne ou importante tant que les bénéfices
dégagés sont supérieurs aux coûts d’implémentation et de maintenance du Data Mart.
Modèle de données et qualité : les données peuvent être relationnelles, provenir de fichiers
plats ou de fichiers web, et elles doivent vérifier au moins l’exactitude et la complétude. Une
table globale regroupant toutes les données peut être créée ou alors les tables peuvent
rester indépendantes, avec des clés de jointures disponibles.
L’environnement physique : n’importe quel type de serveur qui puisse supporter le poids du
Data Mart.
L’environnement logique : peut être un SGBD fournit par un logiciel ou un système de
dossiers, ou les deux. Dans un système de dossiers, les types des bases de données doivent
être unifiés et ces dernières doivent être mobiles.
Outils utilisés : pas de logiciel avec solutions intégrées. Les langages de programmation et
logiciels utilisés peuvent être de toute sorte. Ils doivent simplement remplir les 4 fonctions
identifiées dans la partie « Outils utilisés ».
Automatisation : généralement indispensable. Un Data Mart non automatique est un DM qui
sera lent et source d’erreurs.
Résultats souhaités : indicateurs, listes de données, données brutes ou analyses.
Accès aux données : l’équipe de développement doit avoir des accès de lecture et d’écriture
sur l’ensemble du Data Mart. Les équipes métiers peuvent avoir des accès en lecture
seulement.
Dans un environnement type SGBD classique (« SQL Server », « MySQL »), il serait par exemple
possible de créer les tables grâce à la commande « CREATE TABLE [nom_table] AS … ». C’est
d’ailleurs cette même commande qui gère les métadonnées dans le cadre d’un SGBD. Avec cet
environnement, la création des indicateurs et axes d’analyses serait par contre plus difficiles à gérer
(utilisation des commandes « ALTER TABLE », « UPDATE », « INSERT », etc.) à la différence d’une
étape DATA SAS intuitive et facile à automatiser.
Au niveau des méthodes de dédoublonnage pour assurer l’Unicité des données, les seules méthodes
employées dans notre étude sont des méthodes déterministes utilisant des champs discriminant.
Comme vu dans la partie théorique « Les indicateurs : une vision traitée et concise de l’information »,](https://image.slidesharecdn.com/3e573bdb-401e-49bb-9e96-a057ae3c614f-160109073809/85/Memoire_Julien_Diennet_20140905-56-320.jpg)
































