Téléchargé 36 fois






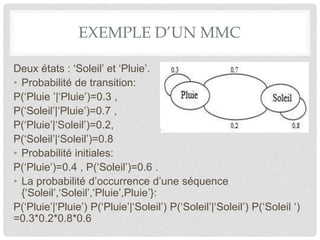












Le document présente les modèles de Markov cachés (MMC), qui sont des outils pour modéliser des phénomènes stochastiques utilisés dans divers domaines comme la reconnaissance vocale et la biologie. Il aborde leur historique, des exemples d'application, ainsi que des algorithmes tels que l'algorithme de Viterbi et l'apprentissage étiqueté. Enfin, il conclut en soulignant l'efficacité des MMC dans la modélisation et leurs nombreuses applications.








































