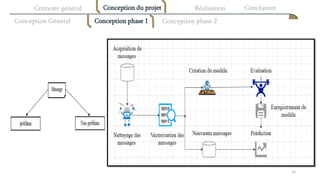
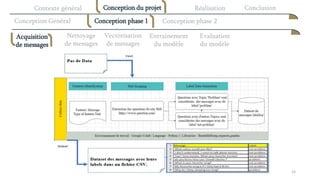
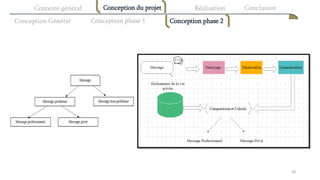
Le document présente une proposition de modèle de text mining pour un système de résolution automatique de problèmes détectés à partir d'échanges de messagerie entre collaborateurs. L'objectif principal est d'aider les utilisateurs à résoudre leurs problèmes professionnels en proposant des ressources pertinentes et en optimisant leur recherche d'informations. Le projet se concentre sur la classification des messages selon qu'ils contiennent des problèmes ou non, et recommande des solutions appropriées.