Téléchargé 38 fois






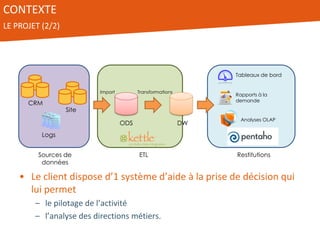




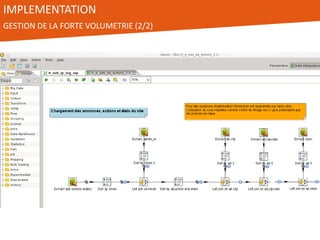
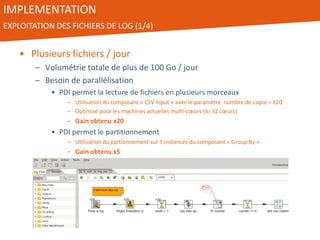
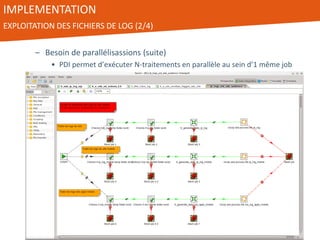

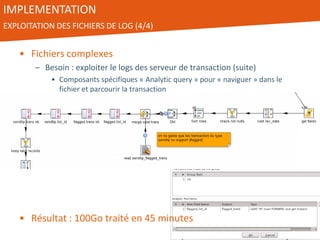
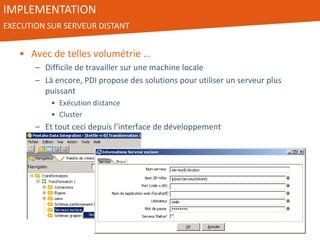
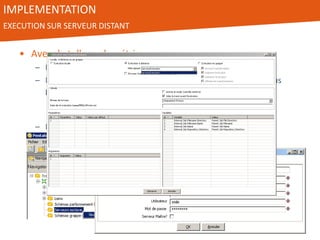



Le document présente l'utilisation de Pentaho Data Integration (PDI) pour développer un entrepôt de données pour un client du secteur des petites annonces, confronté à des défis de volumétrie et de complexité des données. PDI a permis d'optimiser les processus ETL et d'améliorer significativement les performances de traitement des données tout en gérant efficacement des fichiers de log volumineux. Le projet a été mené avec une équipe collaborative et a démontré la flexibilité et la puissance de PDI, ouvrant la voie à d'éventuelles évolutions vers des technologies de big data.







![[Tech bi]présentation commerciale-pentaho_tech-it__anpme_moussanada_it_2014](https://cdn.slidesharecdn.com/ss_thumbnails/tech-biprsentationcommercialepentahotech-itanpmemoussanadait2014-140713104308-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































