Téléchargé 20 fois





















![Mais si vous devez vraiment le faire…
Pensez toujours à ces quelques paramètres dans props.conf
[SL17]
TIME_PREFIX = ^
TIME_FORMAT = %Y-%m-%d %H:%M:%S
MAX_TIMESTAMP_LOOKAHEAD = 19
SHOULD_LINEMERGE = False
LINE_BREAKER = ([nr]+)
TRUNCATE = 10000](https://image.slidesharecdn.com/slparis2018gettingdatain-180403105623/85/SplunkLive-Paris-2018-Getting-Data-In-25-320.jpg)









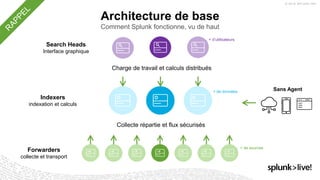
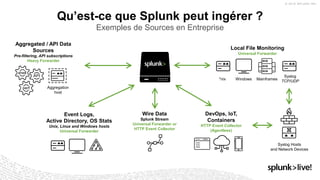
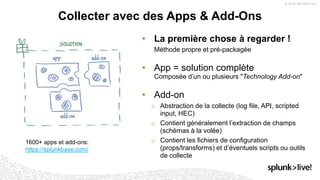
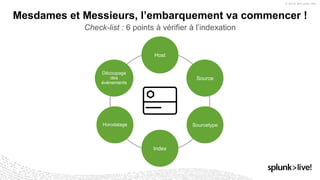
La présentation de Stéphane Lapie aborde la collecte de données et les architectures associées avec Splunk, mettant en avant les fonctionnalités des forwarders et des add-ons. Elle prévoit des déclarations prospectives et souligne l'importance de se référer aux documents d'enregistrement pour des informations précises. Les bonnes pratiques pour l'ajout de nouvelles sources et le respect du modèle d'information commun (CIM) sont également discutées, afin d'optimiser les processus d'indexation et de collecte de données.















































