


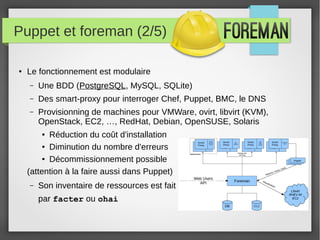



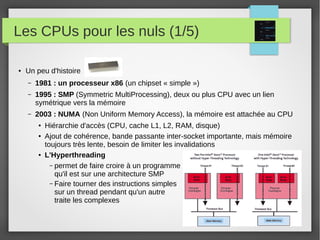

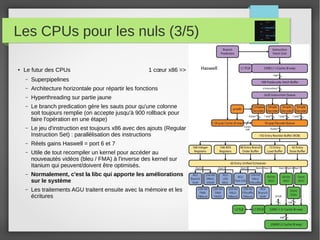



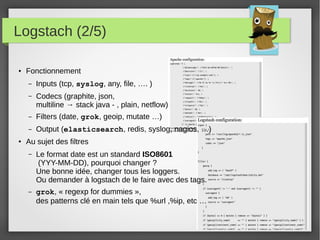





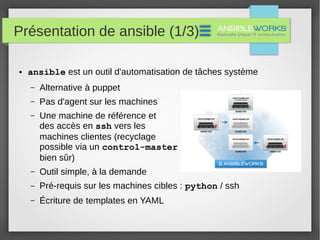



Le document présente divers outils et concepts liés à la gestion des systèmes, tels que Foreman et Puppet pour l'automatisation, Ansible comme alternative, ainsi que des notions de performance des processeurs et de gestion des logs avec Logstash. Il aborde également la métrologie disque et les bonnes pratiques qui y sont associées, en soulignant l'importance de l'outil dans le métier de sysadmin. Enfin, il met en évidence les défis pour convaincre les clients d'adopter ces solutions open source.



































































