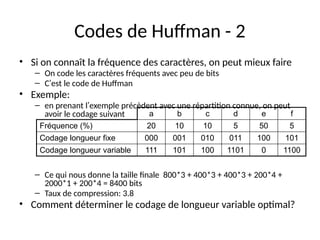
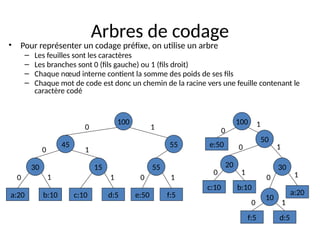
Le document présente les fondements de la représentation numérique de l'information, abordant les concepts de bits, d'octets et d'encodage binaire, ainsi que des techniques pour converter et manipuler des nombres dans différentes bases. Il explore également des méthodes de compression d'information, y compris les algorithmes de compression sans perte et avec perte, comme ceux de Huffman, tout en discutant de la nécessité de la normalisation des valeurs numériques. Enfin, le texte traite des représentations des caractères via des codages comme ASCII et Unicode.

















![Complément à 2n
• Pour représenter un entier négatif en binaire
– On inverse tous les bits
– On ajoute 1
• Il faut donc savoir de combien de bits nous
disposons!
• Exemple sur 8 bits
– 1010 = 000010102 , -1010 = 111101102
• Avec n bits on peut encoder les entiers de [-2n-1
;
2n-1
-1]](https://image.slidesharecdn.com/cours-huet-codage-compression-241231082203-4d31ffb6/85/Cours-huet-codage-information-compression-pptx-17-320.jpg)

![Nombres réels (fixed point)
• Comment représenter des nombres réels?
• Encodons séparément le partie entière et la partie
fractionnaire
– Ex : 0,510 = 0,12
• Très facile à faire
• Mais valeurs limitées. Avec b bits dont f bits pour
la partie fractionnaire
[−2b-1
/2f
; (2b-1
-1)/2f
]
• On appelle cet encodage fixed point](https://image.slidesharecdn.com/cours-huet-codage-compression-241231082203-4d31ffb6/85/Cours-huet-codage-information-compression-pptx-19-320.jpg)
























![Décompression
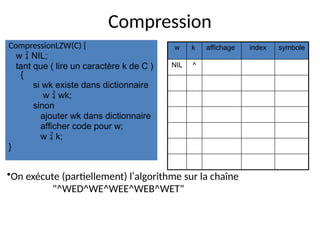
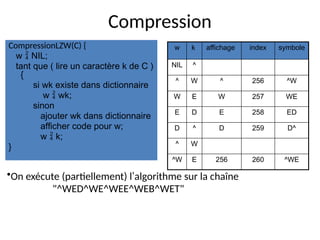
DecompressionLZW(C) {
lire un caractère k;
afficher k;
w = k;
tant que ( lire un caractère k de C ) {
resultat chercher k dans dictionnaire;
afficher resultat;
ajouter w + resultat[0] au dictionnaire;
w = resultat;
}
}
•On exécute (partiellement) l’algorithme sur la chaîne
"^WED<256>E<260><261><257>B<260>T"
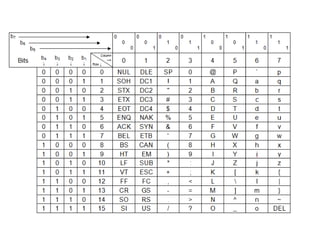
w k affichage index symbole
^ ^](https://image.slidesharecdn.com/cours-huet-codage-compression-241231082203-4d31ffb6/85/Cours-huet-codage-information-compression-pptx-49-320.jpg)
![Décompression
DecompressionLZW(C) {
lire un caractère k;
afficher k;
w = k;
tant que ( lire un caractère k de C ) {
resultat chercher k dans dictionnaire;
afficher resultat;
ajouter w + resultat[0] au dictionnaire;
w = resultat;
}
}
•On exécute (partiellement) l’algorithme sur la chaîne
"^WED<256>E<260><261><257>B<260>T"
w k affichage index symbole
^ ^
^ W W 256 ^W
W E E 257 WE
E D D 258 ED
D <256> ^W 259 D^
<256> E E 260 ^WE
W <260> ^WE 261 E^](https://image.slidesharecdn.com/cours-huet-codage-compression-241231082203-4d31ffb6/85/Cours-huet-codage-information-compression-pptx-50-320.jpg)































