Le projet porte sur la manipulation de nuages de points lidar, visant à intégrer diverses capacités de traitement, telles que l'agrégation, la déformation rigide et non rigide, et la détection d'irrégularités. L'opération d'agrégation s'appuie sur l'algorithme ICP (Iterative Closest Point) et ses variantes, en mettant l'accent sur les déformations non rigides adaptées aux mesures. Ce travail est réalisé dans le cadre d'un projet de fin d'études à l'École Nationale d'Ingénieurs de Tunis, en collaboration avec l'Université de Perpignan Via Domitia.



![Résumé
Le présent projet [1], lié à la manipulation de nuages de points LIDAR, a pour objectif
d’aboutir à l’intégration de plusieurs capacités de traitement soit sous forme d’une amélio-
ration éventuelle de l’existant, soit par la réalisation de nouveaux greffons (plug-in) de trai-
tement, destinés, a priori, à être intégrés dans l’outil CloudCompare [4] ou déposés sur des
serveurs comme service en ligne :
• agrégation de nuage de points dénommé par l’anglicisme «registration»,
• déformation de nuage de points de manière rigide ou non rigide,
• irrégularités, détection d’anomalie dans des structures régulières.
L’opération d’agrégation ou de recalage de nuages de points, s’appuie communément sur l’al-
gorithme de recalage des nuages de point ICP(Iterative Closest Point) et ses variantes que nous
allons particulièrement étudier. La déformation rigide, assez simple à mettre en oeuvre n’est
pas nécessairement adaptée à notre problématique, nous nous intéresserons davantage à des
déformations non rigides qui sont des transformations non linéaires entre points de référence
(amer) parfaitement identifiés sur le parcours de mesures.
Mots-clés : Iterative Closet Point, SVD, Transformation, Recalage 3D, Alignement, LI-
DAR, Nuage de points.
i](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-3-320.jpg)
![Abstract
The present project [1], about LIDAR point cloud manipulation, aims to achieve the inte-
gration of several processing capacities either in the form of an improvement of the existing
one, either by making new plugins, to be integrated into CloudCompare or to set up on online
services[4] :
• 3D Pointcloud registration,
• Rigid and non-rigid 3D Pointcloud deformation,
• irregularities, anomaly detection in regular structures.
The operation of aggregation or registration of point clouds is commonly based on the Itera-
tive Closest Point and its variants, which we will study in particular. The rigid deformation,
quite simple to implement is not necessarly adapted to our problematic, we will be interes-
ted more in non-rigid deformations which are nonlinear transformations between reference
points perfectly identified on the course of measurements.
Keywords : Iterative Closest Point, SVD, Transformation, 3D Registration, Alignment;
LIDAR, Point Cloud.
ii](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-4-320.jpg)






![CHAPITRE I. INTRODUCTION GÉNÉRALE
aux tests de ceux-ci afin de s’approprier de la connaissance et de la méthodologie d’agré-
gation en examinant son adéquation possible aux problématiques rencontrées, par les
mesures effectuées par EXAMETRICS, ces points seront analysés,
2. ayant connaissance, a priori, des limites de l’algorithme, tout en l’ayant testé, une se-
conde recherche bibliographique poursuit la première en examinant particulièrement les
nouveaux axes de recherches qui, sans exclure nécessairement l’I.C.P., le complète dans
certains cas par l’addition de nouvelles approches, s’attachant à rechercher des zones
géométriques homologues entre deux nuages (points, lignes, plans, surfaces convexes).
Cependant en préambule à la présente étude il a été procédé à un premier travail de dé-
couverte [3] de la structure d’un nuage de points, organisé dans un format largement utilisé
dans la profession (*.las), et d’un outil également très connu dans le métier CloudCompare
permettant la manipulation, la visualisation et certains traitements sur des nuages de points
LIDAR. A cette fin, afin de se familiariser avec les approches géométriques et statistiques de
la manipulation de nuages de points et découvrir la bibliothèque de traitement associée (fon-
dation C++ de CloudCompare) mettant en œuvre une grande variété d’algorithmes, il a été
procédé à la construction d’un greffon (plugin) permettant d’assurer l’intersection d’un nuage
de points avec un plan. Compte tenu des tolérances de calcul nécessaires, ce plan s’avère être
un parallélépipède borné dont la hauteur est assimilée à la tolérance de mesure.
3](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-11-320.jpg)







![CHAPITRE II. CONTEXTE DE TRAVAIL
le registre de la mesure et de la géométrie algorithmique.
Cela a conduit EXAMETRICS à faire ses premiers travaux dans les domaines :
• du B.I.M (Builder Informations Models), à savoir la cotation dimensionnelle du patri-
moine construit dans le domaine architectural, après des relevés LIDAR,
• de la foresterie, où le relevé par LIDAR permet d’offrir une solution de substitution aux
mesures dendrométriques, telles que pratiquées dans l’exploitation forestière.
Le présent rapport de stage traite une problématique transversale à tous les marchés d’ac-
quisition de données par LIDAR, le recalage de deux nuages de points, avec une zone géogra-
phique commune.
II.2 La conduite du projet d’agrégation de nuage de points
L’introduction générale faisait apparaître deux étapes dans la méthodologie de travail, concer-
nant le traitement de l’agrégation, le calage des nuages de points. Cependant compte tenu de
la spécificité du traitement de nuages de points LIDAR, ces deux étapes ont été précédées
d’un phase d’apprentissage et de découverte d’un outil de manipulation de nuages de points
CLOUD_COMPARE et de familiarisation avec les structures de nuages de points LIDAR. En
effet cet outil, un logiciel libre (créé au sein du C.E.A. et de l’E.D.F.), toujours en développement
très actif, est en fait un cadriciel de développement en langage C++ [30]. Outre ces fonction-
nalités opérationnelles, il était nécessaire de connaître l’architecture de son logiciel, car l’outil
est une cible pour certains greffons spécifiques que le projet serait amené à développer, mais il
peut être également envisageable d’utiliser sa bibliothèque C++, pour l’intégrer dans d’autres
applications.
II.2.1 La première partie
Cette première partie de stage s’est déroulée en collaboration avec trois étudiants de l’IME-
RIR lors d’un projet industriel d’une durée de deux mois.
Il s’agissait d’une phase d’initiation et de découverte pour bien s’adapter avec la manipula-
tion des nuages de point. Plus précisément, elle avait comme objectif :
• La découverte de l’outil CloudCompare, outil privilégié de manipulation de nuage de
points LIDAR.
• L’analyse des codes sources(QT/C++) de l’outil.
11](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-19-320.jpg)

![CHAPITRE II. CONTEXTE DE TRAVAIL
identifiée dans un nuage (le nuage de référence) son élément homologue dans le second nuage,
en conséquence il a été procédé :
• à une seconde phase de recherche bibliographique afin d’effectuer un état de l’art dans
le domaine de la caractérisation géométrique des nuages de points en s’appuyant sur ces
caractéristiques identifiées afin d’évaluer les paramètres de transformation (translation,
rotation, mise à l’échelle) dénommée transformation de Helmert [13], pour assurer le
calage du second nuage de point sur le nuage de référence.
• en nous appuyant sur les références bibliographiques identifiées, à un cahier des charges
de prototypage mettant cette méthodologie en œuvre : une approche mixant la zone de
points, le couple de droites et un plan borné.
II.3 Technologies impliquées
II.3.1 Matériel
Un LIDAR est un laser doté d’une capacité :
• de balayage mécanique planaire et volumétrique, du fait de deux mouvements, un ba-
layage planaire (éventail) associé à la rotation de ce plan,
• de mesure de temps de vol de l’écho suite à une émission laser, associée à des données
accélérométriques, gyrométriques et magnétométriques, permettant de calculer les co-
ordonnées x, y, z (longitude, latitude, altitude) dans le référentiel initial de l’instrument
de mesure.
Ces dernières données sont issues d’une centrale inertielle intégrée au LIDAR.
D’une manière courante, après traitement, les données obtenues sont mises à disposition
au format *.las qui est un standard de présentation des données LIDAR (ce n’est pas le seul).Il
s’avère être le plus répandu, donc un standard de fait adopté par le LIDAR GEOSLAM d’EXA-
METRICS.
13](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-21-320.jpg)

![CHAPITRE II. CONTEXTE DE TRAVAIL
nuages de points LIDAR en 3D, construit sur une bibliothèque pouvant être intégrée dans
des développements C++, mais non pourvue d’une API d’interface au langage PYTHON.
.
• PCL (Licence BSD) : Point Cloud Library [26] une bibliothèque d’ algorithmes Libres de
droits pour des tâches de traitement de nuage 3D de points LIDAR et dotée d’une API
PYTHON.
• PDAL (Licence GNU/GPL) : Point Data Abstraction Library [29] : est une librairie de
traitement de nuage de points LIDAR, mettant en œuvre de nombreux algorithmes, dont
certains empruntés à PCL et dotée d’une API PYTHON.
• QT SDK , QT Creator (Licence Qt [31]) : librairie graphique développée en en C++. .
• VTK (Licence BSD) : Visualization Toolkit[28] (VTK) est un logiciel libre pour du trai-
tement graphique 3D et traite nuage de points et images. C’est une bibliothèque C++
doté d’API Tcl/Tk, Java, et Python. Le plus ancien dans ce type de logiciel VTK inclut un
large spectre d’algorithmes, scalaire, vectoriel, tensoriel, texture et maillage.
• OPEN3D[27] (Licence MIT) : Bibliothèque libre de droits, de traitement de données 3D,
écrite en C++ et dotée d’une API Python, elle tente de substituer à PDAL en offrant un
haut niveau de parallélisation.
15](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-23-320.jpg)
![Chapitre III
Greffon (Plugin) CloudCompare
Introduction
Dans ce chapitre, après avoir introduit les prérequis du traitement de nuages de points nous
abordons le développement d’un greffon CloudCompare dédié à l’extraction d’un sous nuage
de points à partir d’un fichier *.las. Ce travail a été effectué dans le cadre d’une collaboration
avec une équipe de 3 étudiants de 3ème année de L’IMERIR, lors d’un projet de deux mois,
piloté par EXAMETRICS [3] [2].
III.1 Mise en place des prérequis
Cette section est destinée pour définir les prérequis.
Définition 1 (LIDAR). La télédétection par laser ou LIDAR, acronyme de l’expression en langue
anglaise light detection and ranging ou « laser detection and ranging » (soit en français « détec-
tion et estimation de la distance par la lumière » ou « par laser »), est une technique de mesure
à distance fondée sur l’analyse du temps de vol d’une impulsion LIDAR se réfléchissant sur un
objet. Le LIDAR employé par EXAMETRICS est un instrument GEOSLAM, type Z-REVO. Il s’agit
d’un laser (longueur d’onde de 905nm) terrestre (poids 1 Kg) , porté à mains par un opérateur qui
se déplace en marchant (3 à 4 km/h) dans la zone à analyser. Le laser actif à une zone de balayage
dans un éventail plan ouvert à 270°. Le mouvement de rotation circulaire de la tête portant le laser
permet d’avoir une exploration volumique, (270° x 360°) l’éventail plan effectuant une rotation
permanente. La fréquence de rotation de la tête est de 2 Hz.
La résolution angulaire dans l’éventail plan est de 0.625 °, soit 432 angles de tir dans le plan de
l’éventail. Le balayage de l’éventail se fait en 10ms (100 Hz), ce qui permet une cadence d’acqui-
sition de 43 200 points par seconde sachant qu’un seul point est acquis sur chaque tir laser. Ceci
correspond à un volume de stockage de données de l’ordre de 170 Kbytes/s, soit 10 MB/min. La
précision relative point à point est de 2 à 3 cm, la précision absolu pour une boucle de mesure de
10 mn (100 MB de données) est de 30 cm.
16](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-24-320.jpg)
![CHAPITRE III. GREFFON (PLUGIN) CLOUDCOMPARE
Doté d’un IMU, cet outil offre l’avantage de pouvoir effectuer des relevés dans des zones où le
signal GPS est masqué, cependant l’inconvénient de cette technologie est lié à la dérive des accé-
léromètres avec le temps. Ceci nécessite de recommander des campagnes de mesures de quelques
dizaines de minutes pour limiter cette dérive, ou d’user d’artifice de rebouclage de parcours si l’al-
gorithme de fusion de données est en capacité de les détecter et de procéder à des recalages de la
centrale inertielle au cours de la fusion des données.
Figure III.1 – Lidar employé
Définition 2 (Nuage de points). Ensemble de points donnés dans un système de coordonnées (gé-
néralement X,Y,Z [Longitude, latitude, altitude]) dans le référentiel de l’instrument de mesure : le
LIDAR) et issu du processus de mesure par LIDAR. A l’issue d’une campagne de balayage ce denier
fournit un fichier compressé *.rosbag qui rassemble des données d’accélérométrie, de gyrométrie et
de magnétométrie pour ce qui nous concerne. La fusion de ces données, effectuée hors acquisition
par un logiciel spécialisé, fournit le nuage de points (un point est un écho élémentaire) au format
*.las l’unité de mesure étant le mètre, le tout étant fourni dans le référentiel de l’instrument de
mesure.
Définition 3 (Format *.las/*.Laz). C’est le format standard pour les données LIDAR qui regroupe
différentes informations.
Le *.laz est un format compressé du “*.las”.
Les spécifications détaillées des formats *.Las sont disponibles sur les liens suivants :
17](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-25-320.jpg)
![CHAPITRE III. GREFFON (PLUGIN) CLOUDCOMPARE
• http ://www.asprs.org/a/society/committees/standards/asprs_las_format_v10.pdf
• http ://www.asprs.org/a/society/committees/standards/asprs_las_format_v11.pdf
• http ://www.asprs.org/a/society/committees/standards/asprs_las_format_v12.pdf
• http ://www.asprs.org/a/society/committees/standards/LAS_1_3_r11.pdf
• http ://www.asprs.org/a/society/committees/standards/LAS_1_4_r11.pdf
la dernière version est la version 1.4 à sa révision candidate 13 de Juillet 2015. lL’ASPRS (
American Society for Photogrammetry & Remote Sensing) est la propriétaire de la spécification
*.las. Ce standard est maintenu par un groupe de travail animé par le comité de direction de
l’ASPRS. Les fichiers GEOSLAM issus du post-traitement de conversion au format *.las, utilise
la version 1.0 en fournissant uniquement la position géométrique de chaque écho élémentaire.
Pour le GEOSLAM, l’écho élémentaire, est le premier écho en retour pour une émission donnée. la
période d’émission est de l’ordre de 22µ secondes. En outre le post-traitement fournit le fichier de
trajectographie (x, y, z) de l’origine du référentiel de l’instrument, échantillonné à une période de
10 secondes associé à cet échantillonnage est donné le quaternion donnant le vecteur directeur de
l’émission laser du LIDAR.
Définition 4 (Matrice de transformation). Dans le plan cartésien, une matrice de transformation
est une matrice qui appliquée aux coordonnées d’un point initial représentées par une matrice
colonne permet de trouver celle de son image transformée par une opération géométrique donnée
(translation, rotation, mise à l’échelle). Les coordonnées de la nouvelle image sont alors obtenues
en effectuant la multiplication de chaque pont de l’image initiale sous forme de matrice colonne
(les coordonnées d’un point) par la matrice correspondant à la transformation géométrique que
l’on désire opérer. Il s’agit de la transformation de Helmert [13].
III.2 Développement du greffon CloudCompare
III.2.1 Problématique posée
Le but est de créer un outil, sous forme de greffon (plugin) permettant de sélectionner et
d’extraire les points d’un nuage, sachant que le critère de sélection est l’intersection de ce
nuage de points avec un objet géométrique. Il était proposé de rechercher les points intersec-
tant un plan de l’espace, dans une zone bornée de l’espace. Par ailleurs, l’introduction d’une
tolérance de mesure ramenait le problème à la recherche des points contenus dans un paral-
lélépipède rectangle. Les données initiales sont extrêmement simples :
18](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-26-320.jpg)











![CHAPITRE IV. ETUDES BIBLIOGRAPHIQUES SUR LE RECALAGE I.C.P.
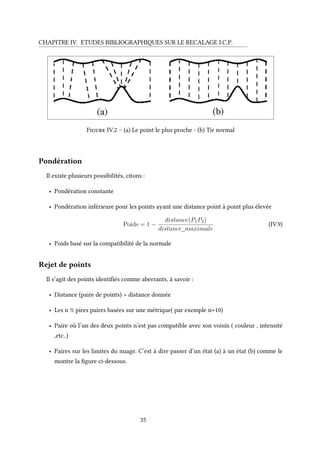
• le problème de mise à l’échelle est important, diverses approches :
– matrices orthonormales,
– recherche de valeurs propres,
– dérivées partielles avec un facteur unique de mise à l’échelle,
– dérivées partielles avec un facteur de mise à l’échelle pour chaque axe du référentiel
3D,
• la prise compte des erreurs de mesures, des points aberrants ou des zones occultées(exemple
courant nécessitant une seconde mesure sur la même zone selon un autre point de vue)
est fondamentale
IV.1.2 Mesures de distance Euclidiennes
Nous examinons les mesures de distance Euclidienne qui est la mesure de distance “natu-
relle”. Elles sont utilisées entre entités géométriques (points, droites, plans, etc.). Ces distances
sont utilisées dans les algorithmes d’estimation de transformation géométrique.[33]
Distance point-point : La distance entre deux points x et y de l’espace Euclidien de di-
mension p (p = 3 dans notre cas), ces points sont représentés respectivement par des vecteurs
de coordonnées homogènes de taille ((p + 1) × 1) notés x ∼ (¯x x) et y ∼ (¯y y) avec x = 0
et y = 0, est donnée par :
d2
PP(x, y) =
¯x
x
−
¯y
y
2
(IV.3)
Distance point-hyperplan : La distance entre un point x et un hyperplan Π ( droite en
2 dimensions et un plan en 3 dimensions), représentés respectivement par des vecteurs de
coordonnées homogènes de taille ((p+1)×1) notés x et Π avec x = 0 et ¯Π = 0, est donnée
par :
d2
PH(x, Π) =
(x Π)2
x2 ¯Π
2 (IV.4)
IV.1.3 Estimation de la transformation
Le problème de la recherche de la rotation et de la translation entre deux ensembles de
points correspondants est connu sous le nom de problème d’estimation de la transformation
30](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-38-320.jpg)
![CHAPITRE IV. ETUDES BIBLIOGRAPHIQUES SUR LE RECALAGE I.C.P.
rigide. Il joue un rôle crucial dans de nombreuses applications robotiques telles que la loca-
lisation et le mappage simultanés (SLAM), la reconstruction de surface et l’étalonnage des
capteurs inertiels. Ce problème est bien étudié dans la littérature .
Parmi les solutions proposés on peut citer la méthode SVD[32] qui se base sur la décom-
position en valeurs singulières d’une matrice calculée en utilisant la représentation standard
des transformations.
+
Figure IV.1 – Exemple simplifié SVD
La recherche de la matrice de transformation rigide optimale peut être décomposée en plu-
sieurs étapes :
1. Trouvez les centroïdes (centre de masse) des deux jeux de données A et B :
centroïdA =
1
N
×
N
i=1
Pi
A, avecP = (x, y, z) (IV.5)
de même pour centroïdB de l’ensemble de points B
2. En utilisant les vecteurs de centre de masse, caler les centroïdes des deux ensembles de
points à l’origine, puis trouver la rotation optimale (matrice R) :
La méthode la plus simple est d’utiliser la décomposition de valeur singulière (SVD), car
cette fonction est largement disponible dans de nombreux langages de programmation
(Matlab, Octave, C avec LAPACK, C ++ avec OpenCV...). SVD est une puissante baguette
magique en algèbre linéaire pour résoudre toutes sortes de problèmes numériques. Il
suffit de savoir que le SVD va décomposer une matrice E en 3 autres matrices, telles
31](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-39-320.jpg)
![CHAPITRE IV. ETUDES BIBLIOGRAPHIQUES SUR LE RECALAGE I.C.P.
que :
SV D(E) = [U, S, V ]
tel que
E = USV T
(IV.6)
Sachant que E pourrait être la matrice de représentation des deux ensembles de points
suivants, chaque point ∈ R3
• N1 = {P1, ..., Pnp}
• N2 = {Q1, ..., Qnq}
A étant la matrice représentative de N1 et B étant la matrice représentative de N2 ,
E = ABT
∈ R3x3
, la construction se faisant avec le même nombre de points dans
chaque nuage c.a.d que np = nq.
L’étape suivante consiste à accumuler une matrice, appelée H, et à utiliser SVD pour
trouver la rotation comme suit :
H =
N
i=1
(Pi
A − centroïdA)(Pi
B − centroïdB)T
(IV.7)
SV D(H) = [U, S, V ]
R = V UT
3. Trouver la translation t
t = −R × centroidA + centroidB (IV.8)
IV.2 L’algorithme ICP et ses variantes
Le premier algorithme ICP a été proposé par Paul Besl et Neil McKay dans un livre, désor-
mais célèbre, paru en 1992 dans IEEE Transactions on PAMI.
Depuis cette publication, différentes versions de l’algorithme ont été publiées soit, pour
accélérer les performances de l’algorithme, soit pour améliorer l’exactitude des informations.
Théoriquement, le principe de l’algorithme ICP présenté est le suivant :
• Élection de l’ensemble des points
32](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-40-320.jpg)
![CHAPITRE IV. ETUDES BIBLIOGRAPHIQUES SUR LE RECALAGE I.C.P.
• Effectuer un échantillonnage en associant, deux à deux, les points homologues d’un
nuage à l’autre,
• Pondération éventuelle des paires correspondantes
• Rejeter des paires pour éliminer les valeurs aberrantes,
• Affectation d’un seuil d’erreur, critère de convergence,
• La réduction de l’erreur de manière itérative.
Chaque étape de l’algorithme peut être réalisée d’une façon différente, d’où la richesse de
l’algorithme ICP et, également, l’une des explications de l’existence de plusieurs variantes de
ce dernier.
L’étape de la sélection des points du nuage
Cette étape d’initialisation diffère d’une variante à un autre. En effet, la sélection se fait en
prenant en considération soit :
• Tout le nuage de points
• Un échantillonnage linéaire 1 point sur n (n à définir dans [1,10] par exemple)
• Un échantillonnage aléatoire selon une loi uniforme
• une sélection des points avec une distribution de la normale à ces points soit la plus
élevés, ce qui évite une sélection de points appartenant à une même surface plane,
Pour l’échantillonnage normal la structure changeante de relief (même modeste)peuvent
jouer un rôle critique. Par ailleurs, la distribution selon la normale est simple, consommation
basse mais sa robustesse est faible ( Converge parfaitement que dans des nuages sans cour-
bures).
Ainsi, l’échantillonnage d’un seul des deux nuages de points n’a pas un effet considérable,
même si on permute les rôles des nuages, sur la convergence de l’algorithme car cette stratégie
d’échantillonnage de l’algorithme ICP préserve sa commutativité (Secret-key algorithm ).
Bruit + Distorsion + échantillons réduits = Mauvais résultats
En conclusion, un échantillon très dense et non bruité est le meilleur choix pour cette étape.
En effet, nous préservons toujours la densité d’un nuage dans cette opération commutative.
33](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-41-320.jpg)

![Chapitre V
Réalisation et test
Introduction
Ce chapitre est consacré à l’étape de réalisation et test. Il a pour objectif de présenter et tester
les limites des algorithmes déjà implémentés dans certaines librairies et de les comparer avec
nos propositions de code. Nous présentons l’environnement de développement et les librairies
adoptées. Nous allons ensuite montrer quelques courbes illustrant la performance d’exécution
et notamment la vitesse de convergence des algorithmes.
V.1 L’algorithme ICP dans la librairie Open3D
Open3D est une bibliothèque libre de droits qui prend en charge le développement rapide
de logiciels traitant des données 3D. Sa mise en oeuvre s’appuie sur le "notebook" JUPYTER.
Ce cadriciel est hautement optimisé et configuré pour la parallélisation.
Cette libraire propose deux variantes de l’algorithme ICP, la première se base sur "point-
to-point ICP" et la deuxième sur the point-to-plane ICP [Rusinkiewicz2001].
V.1.1 Open3d : Point-to-point ICP
En général, l’algorithme ICP itère sur deux étapes comme nous l’avons précisé dans le cha-
pitre précédent, à savoir :
• Trouver un ensemble de correspondance K = {(p, q)} à partir du nuage de points cibles
P et du nuage de points source Q transformé avec la matrice de transformation initiale
T.
• Mettre à jour la transformation T en minimisant une fonction E(T) définie sur l’en-
semble de correspondance K.
37](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-45-320.jpg)
![CHAPITRE V. RÉALISATION ET TEST
Dans ce cas "Point-to-point ICP" proposé par Besl et McKay en 1992 [réf article] la fontion
E(T) est comme suit :
E(T) =
(p,q)∈k
p − T × q 2
(V.1)
La transformation T est composée d’une matrice de rotation 3∗3 et d’un vecteur de transla-
tion. Donc, la classe développée TransformationEstimationPointToPoint, avec Open3D, fournit
des fonctions permettant de calculer les matrices résiduelles et jacobiennes de l’objectif. Par
défaut, registration_icp s’exécute jusqu’à la convergence ou atteint un nombre maximal d’ité-
rations (30 par défaut). Ce paramètre peut être modifié pour offrir plus de temps de calcul et
améliorer ainsi les résultats.
Figure V.1 – État initial avant le recalage Point-to-point ICP
Nous observons dans la figure ci-dessus, notre greffon implémenté avec le langage Python
et qui utilise l’état initial d’Open3D avant l’exécution de l’algorithme de recalage point-to-
point ICP. Les fichiers de nuages de points source et destination ont comme extension *.pcd.
Pour les paramètres d’entrée de notre algorithme, nous avons fixé le seuil de convergence
à 0.02 et le nombre maximale d’itérations à 30, sans application d’une transformation initiale.
Le nuage en rouge est la source (celui à recaler) et celui en bleu c’est le nuage de destination
(le nuage de référence).
38](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-46-320.jpg)
![CHAPITRE V. RÉALISATION ET TEST
Dans la figure ci-dessous, nous montrons le résultat de l’algorithme sur deux petits nuages
synthétiques de test.
Figure V.2 – Résultat du recalage Point-to-point ICP
Le nuage de points recalé est en vert.La couleur bleue est propre au nuage de référence.
V.1.2 Open3d : Point-to-plane ICP
L’algorithme Point-to-plane ICP [ChenAndMedioni1992] utilise une fonction E(T) sui-
vante (formule V.2), différente de l’algorithme Point-to-point ICP (formule V.1).
E(T) =
(p,q)∈k
((p − T × q) −
−−→
np )2
(V.2)
Avec l’utilisation
−−→
np la normale du point p, dans l’expression E(T) à minimiser, l’article
[Rusinkiewicz2001] a montré que l’algorithme ICP point à plan a une vitesse de convergence
plus rapide que l’algorithme ICP point à point.
Dans Open3D, l’appel de cet algorithme se fait aussi avec registration_icp mais en appelant
la classe d’estimation TransformationEstimationPointToPlane.
Ainsi, nous avons appliqué les deux différents algorithmes sur des jeux de données de 198835
points pour le nuage source et 137833 pour le nuage destination, trouvés dans les données de
39](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-47-320.jpg)







![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
des points sur une zone donnée. Ces divers relevés, tout en ayant des zones communes, peuvent
être effectués selon :
• des points de vue (référentiel instrument) distincts,
• des échelles (distance de la prise de vue) différentes,
ce qui complexifie d’autant les recalages de deux nuages de points. Les points ou échos en
retour sont positionnés dans le référentiel de l’instrument de mesure, suite à sa calibration
et le positionnement des référentiels initiaux n’est pas nécessairement le même si toutes les
précautions ne sont pas prise dans ce sens.
Ainsi des points ou objets homologues d’un nuage à un autre peuvent être positionnés
dans deux référentiels, ayant subi translation et rotation l’un par rapport à l’autre. Le recalage
nécessite d’être en capacité d’évaluer cette translation et cette rotation. Cette évaluation sera
d’autant plus aisée que nous trouverons des homologies entre le nuage de référence et le nuage
à recaler.
Mais divers travaux ont mis en évidence l’obtention de recalages d’autant meilleurs que
plusieurs caractéristiques du nuage de points, sont sollicités pour la conduite de cette opé-
ration. Nous les passons rapidement en revue en nous appuyant sur [7] afin de dégager des
priorités dans la maîtrise de leur mise en œuvre.
Des propositions sont faites pour utiliser toutes géométries (lignes, points, plans) de zones
homologues, d’un nuage de point à l’autre, faisant office d’amers en quelque sorte. Cepen-
dant cette maîtrise nécessite une gradation de compétences, sachant que toutes extractions de
caractéristique requièrent des démarches spécifiques.
Afin d’éliminer les inconsistances d’un nuage de point à l’autre toute une méthodologie doit
être mise à l’œuvre et ceci est crucial si on cherche de la qualité (précision) dimensionnelle. Le
processus de recalage doit pouvoir répondre à quatre problématiques [15] :
• l’extraction de primitives géométriques, points remarquables, des lignes, des plans,
les structures géométriques basique (cylindres, sphères, polygône)
• l’estimation de la meilleure transformation géométrique, associant rotation, trans-
lation, mise à l’échelle, afin d’établir la meilleure correspondance possible entre homo-
logues dans deux nuages de points,
• la mesure et la qualification de la mise en correspondance des homologues de
deux nuages,
• l’adoption de la bonne stratégie de mise en correspondance.
48](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-56-320.jpg)
![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
VI.1 Parcours bibliographique sommaire
Même si nos avions quelque peu connaissance des limites (convergence ou non, temps de
calcul) de l’ICP classique EXAMETRICS y est confronté tous les jours en production à son
bureau d’études, les lectures le confirmaient, il était nécessaire d’acquérir les fondamentaux
afin d’aller plus loin. L’objectif de l’entreprise est de s’approprier les technologies et les algo-
rithmes de traitement, le passage par les fondamentaux est nécessaire.
Afin d’identifier les axes de travaux à venir des compléments bibliographiques nous aident
à éclairer le paysage afin de cerner l’état d’avancement des nouvelles approches du recalage
ou des extensions apparaissant dans la famille des algorithmes ICP déjà très peuplée. Nous en
donnons ci-après un résumé très sommaire et un approfondissement sera nécessaire.
VI.1.1 Notes de lecture : EFFICIENT VARIANT OF ICP
Szymon Rusinskiewicz Marc Levoy Standford university [8]
L’algorithme I.C.P. est connu pour une large utilisation dans le recalage de nuage de points
par rapport à une référence, quand la position initiale du nuage à recaler est connue et qu’il
possède une zone commune avec le nuage de référence.
Les variantes de l’ICP peuvent intervenir dans différentes phases de l’algorithme. Dans le
cas présent nous nous calons uniquement sur la géométrie. Le principe repose sur la mini-
misation de la distance entre deux groupes de points a priori homologues entre le nuage de
référence et le nuage à recaler. Les transformations à appliquer concernent, ses rotations, des
translations et des mises à l’échelle, voire des redressements dans le cas de dérive de certaines
mesures géométriques. mais on s’intéresse à des surfaces homologues que l’on tente d’appai-
rer.
Disposer d’une transformation initiale qui diminue la distance initiale est un facteur positif
d’amélioration de la convergence. En absence de celle-ci, la convergence est fortement liée à
la qualité de l’estimateur initial. Cet estimateur peut être apprécié selon diverses méthodes :
• utilisation de la trajectoire du scanner,
• recherche de caractéristiques de surface,
• signatures de surface par spin de nuage par analogie avec le spin d’image.
49](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-57-320.jpg)
![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
VI.1.2 Notes de lecture : A ROBUST LINEAR FEATURES-BASED RE-
GISTRATION
Les balayage multiple de zone enrichit la densité des nuages de point et évite l’occultation
de certaines parties. La difficulté étant d’assurer le calage correct des zones se chevauchant
dans un système commun de coordonnées. [10]
Il est adopté un enregistrement fin et un enregistrement grossier tous deux basés sur la
reconnaissance de caractéristiques géométriques. Un algorithme Ransac identifie un triplet de
lignes, dans un nuage de points. Les lignes homologues sont recherchées dans le second nuage.
Il existe des méthodes de recalage rigides et non rigides :
• mise en correspondance de caractéristiques géométriques (points, lignes, plans, sphère,
cylindre), sous réserve de trouver les éléments adaptés dans la scène dont le filtrage est
coûteux et de disposer de règles de description de formes particulièrement pertinentes,
• passage par un maillage et détection de surfaces homologues locales,
• passage par la gestion des points mettant généralement en œuvre l’algorithme ICP, qui
malgré sa popularité et la diversité de ses variantes, se heurte au nombre d’itérations
nécessaires et la non assurance de sa convergence, vu que le calcul de ses paramètres de
transformation se fait pas à pas. Les recherches actuelles s’orientent vers une première
étape grossière permettant d’initialiser au mieux la phase de démarrage de l’algorithme
ICP sollicité.
Donc 4 problèmes à traiter :
• extraction des primitives géométriques, en disposant de descripteurs de forme perti-
nents,
• trouver les paramètres de transformation,
• trouver des critères de similarité pour associer les éléments homologues d’un nuage de
points à l’autre, afin de les faire coïncider,
• définir une stratégie de convergence.
En zone urbaines, les lignes sont plus faciles à trouver, intersection de plans. Il faut noter le
développement du cadriciel du «Robust Line Matching & Registration, RLMR» qui est décrit.
Survol ICL (Iterative Closest Line), par analogie avec ICP seule la matrice de rotation est
prise en compte. Autre approche pour le calcul de la translation. ici pour la recherche de la
50](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-58-320.jpg)
![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
transformation d’Helmert, la contrainte est qu’il faut que les extrémités de segment soient
des points homologues du nuage de référence au nuage à recaler, l’échelle est identique (on
s’installe dans le même volume d’observation [cube ou parallélépipède].
VI.1.3 Notes de lecture : FEATURE-BASED REGISTRATION
Note : en faire un document de référence même si il date, c’est une piste de solution.
[7] Avant tout recalage de nuage de points, ces derniers doivent être repositionnés, si ce
n’est le cas, dans un référentiel commun. Les paramètres de transformation (rotation, trans-
lation et mise à l’échelle) doivent être définis. A cette fin les propriétés des caractéristiques
géométriques homologues sont analysées statistiquement afin d’évaluer les transformations
nécessaires à opérer. C’est ce qui est conduit dans la présente proposition
Connu comme premier outil de recalage, bénéficiant de certaines améliorations, l’algo-
rithme ICP a largement occupé la scène du recalage avec une promotion excessive. Trouver
des points homologues d’un nuage à un autre, sauf amers bien spécifiques, reste difficile. Des
tentatives sont conduites entre courbes/lignes identifiées entre deux nuages et la minimisation
de leur distance à leur plan d’appartenance. D’autres tentatives en création d’image raster (z
en paramètre) sont conduites. La qualité du recalage reste faible.
En scènes urbaines, le point, la droite et le plan ont la priorité des recherches en cours.
Néanmoins l’hypothèse d’homologie point à point est à rejeter, tout au plus peut-on envisager
de rechercher des zones locales sous-jacentes de surface (minimisant la distance points/surface
au sens des moindres carrés) et pouvant coïncider d’un nuage à l’autre.
Cependant en travaillant les caractéristiques suivantes :
• points,
• lignes,
• surfaces,
il est possible d’aboutir à une paramétrisation de la transformée d’Helmert. En trouvant, au
minimum 3 points homologues de manière manuelle il est possible de définir :
• les termes de la matrice de transformation,
• le facteur d’échelle,
• le vecteur de translation.
51](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-59-320.jpg)
![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
Concernant les lignes, il est nécessaire d’avoir une colinéarité entre les deux lignes homo-
logues.
VI.1.4 Note lecture : ALTERNATIVE METHODOLOGIES FOR LIDAR
CALIBRATION
[14] Deux approches sont toujours privilégiées pour le recalage de deux nuages de points
de mesures sur des zones communes :
• une approche calée sur l’instrumentation, prenant en compte ses dérives (corrigées par
une transformation géométrique), et respectant une mise en œuvre stricte de la procé-
dure de mesure,
• une approche calée donnée, essayant de reconstituer la géométrie commune aux deux
nuages de points en s’affranchissant du bruit de mesure ou de la redondance des données.
Fondamentalement cet article revient sur les écarts géométriques, entre deux campagnes
de mesures, induit par la calibration des instruments et notamment la position des référentiels
de mesures au moment de l’acquisition à des moments différents. Ceci engendre déjà les écarts
systématiques qu’il nous faut retirer, sans oublier l’échelle ou la distance de la prise de mesure.
Deux procédures de recalage sont abordées :
• la méthode simplifiée n’utilise que les données géométriques, parfaitement représen-
tatives des données mises à disposition par le LIDAR, il faut estimer les écarts géomé-
triques entre les deux zones communément chevauchées, sous réserve qu’il n’y ait pas de
dérive intrinsèque de l’instrument de mesure, en prenant la précaution de la correction
minimale suite à des passages multiples sur une même zone.
• la méthode rigoureuse exige en outre la connaissance de la trajectographie de l’instru-
ment de mesures, et elle met en évidence le poids des erreurs du écarts entre les réfé-
rentiels de navigation. Considérant que l’identification de points homologues est im-
possible, cette méthode s’appuie sur un maillage à base de réseau de triangles irrégulier
(T.I.N.) dont la normale à la surface est estimée et il est procédé à la recherche du triangle
(le plus homologue) en utilisant la matrice de variance-covariance dans le second nuage,
sur les triangles d’une zone locale et l’évaluation de l’écart angulaire entre les normales
du triangle initial du premier nuage et le triangle sélecté dans le second.
52](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-60-320.jpg)
![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
Les deux approches nécessitent une construction du paramétrage de correction en tra-
vaillant sur des zones locales pour leur estimation.
VI.1.5 Fiche lecture de : MULTI-FEARURED REGISTRATION
[15] Par l’apport immédiat des trois dimensions, la mesure par LIDAR supplante peu à peu
les apports de la photogrammétrie. Cela est vrai tant pour les lidar satellitaires, aéroportés
ou terrestres mobiles. Cependant l’extraction de l’information dimensionnelle d’un nuage de
points LIDAR est d’autant plus précise qu’elle peut prendre en compte plusieurs caractéris-
tiques de ce nuage de points.
Le recalage («registration») de nuage de point est une opération couramment nécessaire
dans les chaînes de traitement. En effet, une campagne de mesures sur un site nécessite plu-
sieurs relevés indépendants. Ces derniers tout en ayant des zones communes peuvent être
effectués selon :
• des points de vue (référentiel instrument),
• des échelles (distance de la prise de vue),
distincts, ce qui complexifie d’autant les recalages de deux nuages de points. Les points ou
écho en retour sont positionnés dans le référentiel de l’instrument de mesure.
Ainsi des points ou objets homologues d’un nuage à un autre peuvent être positionnés
dans deux référentiels, ayant subi translation et rotation l’un par rapport à l’autre. Le recalage
nécessite d’être en capacité d’évaluer cette translation et cette rotation.
Mais divers travaux ont mis en évidence l’obtention de recalages d’autant meilleurs que
plusieurs caractéristiques du nuage de points, sont sollicités pour la conduite de cette opéra-
tion. Nous les passons rapidement en revue en nous appuyant sur [[7] afin de dégager des
priorités dans la maîtrise de leur mise en œuvre.
Des propositions sont faites pour utiliser toutes géométries (lignes, points, plans) de zones
homologues, d’un nuage de point à l’autre, faisant office d’amers en quelque sorte. Cepen-
dant cette maîtrise nécessite une gradation de compétences, sachant que toutes extractions de
caractéristique requièrent des démarches spécifiques.
Afin d’éliminer les inconsistances d’un nuage de point à l’autre toute une méthodologie doit
être mise à l’œuvre et ceci est crucial si on cherche de la qualité (précision) dimensionnelle.
Il existe une véritable panoplie de solutions en matière de recalage et d’agrégation de nuage
de points :
53](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-61-320.jpg)

![CHAPITRE VI. LE RECALAGE PAR CARACTÉRISTIQUES ÉTENDUES
A l’issue de la transformation, l’objectif est de minimiser l’écart entre les primitives du
nuage de référence et celles du nuage transformé. l’opération est conduite sur droite et sur
plan.
VI.1.6 lecture de : Georeferenced Point Clouds : A Survey of Features
and Point Cloud Management
[6] Ce document parcourt les caractérisation possibles de nuages de points, ainsi que les
choix de traitement adoptés, selon les caractéristiques de ce même nuage de points. Un nuage
de points se caractérise par une organisation non structuré de points géolocalisés dans un
repère 3D et avec des frontières relativement peu définies. En général, chaque point peut avoir
d’autres attributs : intensité, normale, couleur, heure d’acquisition (nx; ny; nz; z; r; g; b;
nIR; T). Ceci n’est pas le cas dans les nuages traités chez EXAMETRICS. La notion d’échelle
n’existe pas a priori, mais la recherche d’éléments homologues doit se faire dans une même
zone géométrique et selon les modalités d’acquisition des nuages, la densité de points peut
varier fortement d’un nuage à l’autre, pour une même zone géométrique.
Dans le cas présent l’acquisition d’un écho unique (le premier) fournit ses coordonnées et
l’heure d’acquisition. Nous disposons uniquement de la position géométrique du point et de
son heure d’acquisition, en temps normé (pour les fichiers *.las).
Toutes autres caractéristiques (primitives géométriques) , ne peuvent être construite que
par calcul issus des données précédentes :
• lignes et droites,
• normales à des surfaces locales,
• plans,
• formes géométriques élémentaires.
VI.1.7 Note de lecture : STRIP ADJUSTMENT USING CONJUGATE PLA-
NAR AND LINEAR FEATURES
[5] Partant du principe qu‘il n’est pas possible de trouver de manière native, des points
homologues dans des zones de chevauchement de de deux nuages de points distincts, la pré-
sente méthode développe l’identification locale de plans et de droites dont l’homologie (au
sens morphologique du terme) est identifiable d’un nuage de points à l’autre, ceci permettant
un recalage du second nuage par rapport au premier pris comme référence.
55](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-63-320.jpg)






![Bibliographie
[1] R&D Exametrics.
Agrégation Déformation Irrégularité manipulation de nuages de points LIDAR
Cahier des charges fonctionnelles Exametrics-R&d 10 mars 2018 St Estève France
[2] Clément Matysiak Jules Malard Noé Pichot Mahdi Smida.
Rapport Projet Industriel IMERIR - Projet LIDAR - Exametrics Années 2017-2018
Promotion Dessertine Rapport final projet LIDAR Mars 2018
[3] R&D Exametrics.
Découverte Cloud-Compare Manipulation de nuages de points Cahier des charges
projet IMERIR découverte Lidar Exametrics-R&D Février 2018 St Estève France
[4] Daniel Girardeau-Montaut.
“Détection de changement sur des données géométriques tridimensionnelles”.
Thèse de doctorat de l’École Nationale Supérieure des Télécommunications, 15 Mai 2006,
Paris, France.
[5] A. F. Habib a, *, A. P. Kersting a, Z. Ruifanga, M. Al-Durgham a, C. Kim a, D. C. Lee.
Lidar strip adjustemnt using conjugate linear features in overlapping strip
• Dept. of Geomatics Engineering, University of Calgary, 2500 University Dr.
NW,Calgary, Alberta, T2N 1N4, Canada, , habib@geomatics.ucalgary.ca.
• Department of Geo-Informatics, Sejong University, Seoul, South Korea,
dclee@sejong.ac.kr
[6] Johannes Otepka , Sajid Ghuffar, Christoph Waldhauser, Ronald Hochreiter and Norbert
Pfeifer.
Georeferenced Point Clouds : A Survey of Features and Point Cloud Management
[7] J.J. Jaw*, T.Y. Chuang.
Feature-based registration of terrestrial lidar points clouds Department of Civil
Engineering, National Taiwan University, 1, Roosevelt Rd., Sec. 4, Taipei 10617, Taiwan,
China – (jejaw,d95521008)@ntu.edu.tw
62](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-70-320.jpg)
![BIBLIOGRAPHIE
[8] Szymon Rusinkiewicz, Marc Levoy, .
Efficient variants of ICP algorithm
Stanford University
[9] Martyna Poreba, François Goulette.
A robust linear feature-based procedure for automated registration of point
clouds.
(MINES ParisTech)
[10] JA. Al-Rawabdeh a*, H. Al-Gurrani a, K. Al-Durgham a, I. Detchev a, F. He b, N. El-Sheimy
a, and A. Habib b.
A robust registration algorithm for point cloud from UAV images for change de-
tection
Dep’t of Geomatics Engineering, University of Calgary, 2500 University Dr. NW, Calgary,
AB, Canada T2N 1N4 - (amalrawa, htattya, kmaldurg, i.detchev, elsheimy)@ucalgary.ca
Lyles School of Civil Engineering, Purdue University, 47907 West Lafayette, IN, USA -
ahabib@purdue.edu
[11] von Kurt Leimer.
External Sorting Of Point Clouds
BACHELORARBEIT zur Erlangung des akademischen Grades Bachelor Of Science im Rah-
men des Studiums Medieninformatik und Visual Computing eingereicht
[12] Islem JEBARI.
Recalage de données 3D aériennes et terrestres pour cartographie numérique
Université ISTIA 2009 Angers
[13] Sasa Milenkovic1.
Quaternion Based Helmert Transformation
Research · June 2015 DOI : 10.13140/RG.2.1.2915.6004 Republic Geodetic Authority — Ser-
bia AGROS Control Centre
[14] Ayman Habib *, Ki In Bang, Ana Paula Kersting and Jacky Chow.
Alternative Methodologies for LiDAR System Calibration
Department of Geomatics Engineering, The University of Calgary, 2500 University
Drive NW, T2N 1N4, Calgary, AB, Canada; E-Mails : kibang@ucalgary.ca (K.B.);
ana.kersting@ucalgary.ca (A.K.); jckchow@ucalgary.ca (J.C.)
63](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-71-320.jpg)
![BIBLIOGRAPHIE
[15] Tzu-Yi Chuang and Jen-Jer Jaw .
Multi-Feature Registration of Point Clouds
Department of Civil Engineering, National Taiwan University, Taipei City, Taiwan 10617;
jtychuang@ntu.edu.tw * Correspondence : jejaw@ntu.edu.tw; Tel. : +886-2-3366-4276
Academic Editors : Jie Shan, Juha Hyyppä, Richard Gloaguen and Prasad S. Thenkabail
Received : 23 October 2016; Accepted : 12 March 2017; Published : 16 March 2017
[16] Ana Paula Kersting, Ruifang Zhai, Ayman Habib,.
Strip adjustement using conjugate planar and linear features in overlapping
strips
Dept. of Geomatics Engineering, University of Calgary, 2500 University Dr. NW, Calgary,
Alberta, T2N 1N4, Canada. ana.kersting@ucalgary.ca, rzhai@geomatics.ucalgary.ca, ha-
bib@geomatics.ucalgary.ca
[17] Adrien Gressin, C. Mallet, J. Demantké, Nicolas David
Towards 3D lidar point cloud registration improvement using optimal neighbo-
rhood knowledge.
Université Paris-Est – IGN/SR, MATIS, 73 avenue de Paris, 94160 Saint-Mandé, France
[18] F. Pommerleau, F. Colas, R. Siegward.
A Review of Point Cloud Registration Algorithms for Mobile Robotics
Space Robotics Laboratory – University of Toronto Toronto, Canada,
f.pomerleau@gmail.com Inria, Villers-lès-Nancy, F-54600, France CNRS, Loria, UMR
7503, Vandoeuvre-lès-Nancy, F-54500, France Université de Lorraine, Vandoeuvre-
lès-Nancy, F-54500, Francefrancis.colas@inria.fr Autonomous Systems Lab – ETH
ZurichZurich, Switzerlandrsiegwart@ethz.ch
[19] Georgios D. Evangelidis and Radu Horaud.
Joint Alignment of Multiple Point Sets with Batch and Incremental Expectation-
Maximization
[20] Francois Pomerleau Francis Colas RolandSiegwart Stephane Magnenat
Comparing ICP Variants on Real-World Data Sets Open-source library and
experimental protocol.
Space Robotics Laboratory – University of Toronto Toronto, Canada,
f.pomerleau@gmail.com Inria, Villers-lès-Nancy, F-54600, France CNRS, Loria, UMR
7503, Vandoeuvre-lès-Nancy, F-54500, France Université de Lorraine, Vandoeuvre-
64](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-72-320.jpg)
![BIBLIOGRAPHIE
lès-Nancy, F-54500, Francefrancis.colas@inria.fr Autonomous Systems Lab – ETH
ZurichZurich, Switzerlandrsiegwart@ethz.ch
[21] Ying He ,Bin Liang , Jun Yang, Shunzhi Li, Jin He
An Iterative Closest Points Algorithm for Registration of 3D Laser Scanner Point
Clouds with Geometric Features
Shenzhen Graduate School, Harbin Institute of Technology, Shenzhen 518055,
China Department of Automation, Tsinghua University, Beijing 100084, China; he-
j15@mails.tsinghua.edu.cn Shenzhen Graduate School, Tsinghua University, Shenzhen
518055, China; yangjun603@mail.tsinghua.edu.cn (J.Y.); lisz15@mails.tsinghua.edu.cn
(S.L.) Correspondence : heying@hitsz.edu.cn (Y.H.); bliang@tsinghua.edu.cn (B.L.); Tel. :
+86-010-6279-7036 (Y.H.)
Webographie
[22] Python : https://www.python.org
[23] cProfile : https://docs.python.org/2/library/profile
[24] PyCuda : https://mathema.tician.de/software/pycuda
[25] Numpy : https://www.numpy.org
[26] Pcl : http://www.pointclouds.org/documentation/
[27] Open3d : http://www.open3d.org/docs/index.html
[28] Vtk : https://www.vtk.org/doc/nightly/html/annotated.html
[29] Pdal : https://pdal.io/project/docs.html
[30] C++ : http://devdocs.io/cpp/
[31] Qt : http://doc.qt.io/
[32] Svd : http://web.mit.edu/be.400/www/SVD/Singular_Value_
Decomposition.htm
[33] Mesures de distance : https://tel.archives-ouvertes.fr/
tel-00004360/document
65](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-73-320.jpg)


![ANNEXES
maxIteration ) . pack ( )
72
73 s e l f . v = StringVar ( l1 , value = ’ output ’+ s t r ( datetime . now ( ) ) + ’ . l a s ’ )
74 s e l f . e = Entry ( l1 , t e x t v a r i a b l e = s e l f . v )
75 s e l f . e . pack ( )
76
77 " " " Compute Button " " "
78 tk . Button ( l1 , t e x t = " Compute " , command= s e l f . Compute ) . pack ( )
79
80
81 " " " SECTION " " "
82 s e l f . l 2 = LabelFrame ( s e l f , t e x t = "TRACE SECTION " , padx =30 , pady =30)
83 s e l f . l 2 . pack ( f i l l = " both " , expand= " yes " )
84
85 s e l f . mainloop ( )
86
87
88 def o p e n f i l e ( s e l f ) :
89 s e l f . filename = askopenfilename ( t i t l e = " Open f i l e " )
90
91 def maxIteration ( s e l f ) :
92 x= s e l f . spinbox . get ( )
93 type ( x ) == i n t
94 i f i n t ( x ) >200 or i n t ( x ) <2:
95 messagebox . showerror ( "ERROR" , "MAX ITERATION VALUE MUST BE AN
INTEGER BETWEEN 1 AND 200 " )
96 e l s e :
97 return i n t ( x )
98
99
100
101 def r e a d L a s F i l e ( s e l f , f i l e p a t h ) :
102 pip= {
103 " p i p e l i n e " : [
104 {
105 " type " : " r e a d e r s . l a s " ,
106 " filename " : f i l e p a t h
107 } ,
108
109 ]
110 }
111 p i p e l i n e = pdal . P i p e l i n e ( json . dumps ( pip ) )](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-76-320.jpg)
![ANNEXES
112 p i p e l i n e . v a l i d a t e ( )
113 p i p e l i n e . execute ( )
114 return p i p e l i n e
115
116
117 def recupereSource ( s e l f ) :
118 s e l f . filenameSource = askopenfilename ( t i t l e = " Open Source LAS F i l e " ,
f i l e t y p e s =[( ’ l a s f i l e s ’ , ’ . l a s ’ ) , ( ’ l a s f i l e s ’ , ’ . l a s ’ ) ] )
119 i f s e l f . filenameSource != " " :
120 l a b e l = Label ( s e l f . l2 , t e x t = " Source point Cloud i s s u c c e s s f u l l y
loaded . . . " , bg= " yellow " )
121 l a b e l . pack ( )
122 e l s e :
123 Label ( s e l f . l2 , t e x t = " Choose your Source point Cloud Pl e as e " , bg
= " red " ) . pack ( )
124
125
126
127 def recupereTarget ( s e l f ) :
128 s e l f . filenameTarget = askopenfilename ( t i t l e = " Open Source LAS F i l e " ,
f i l e t y p e s =[( ’ l a s f i l e s ’ , ’ . l a s ’ ) , ( ’ l a s f i l e s ’ , ’ . l a s ’ ) ] )
129 i f s e l f . filenameTarget != " " :
130 l a b e l = Label ( s e l f . l2 , t e x t = " Target point Cloud i s s u c c e s s f u l l y
loaded . . . " , bg= " yellow " )
131 l a b e l . pack ( )
132 e l s e :
133 Label ( s e l f . l2 , t e x t = " Choose your Target point Cloud Pl e as e " , bg
= " red " ) . pack ( )
134
135
136
137 def pipelineToxyz ( s e l f , p i p e l i n e ) :
138 " " " transform l a s f i l e information j u s t to XYZ information to our
point Cloud c l a s s " " "
139 arr = p i p e l i n e . arrays [ 0 ]
140 d e s c r i p t i o n = arr . dtype . descr
141 c o l s = [ c o l f o r col , __ in d e s c r i p t i o n ]
142 df = pd . DataFrame ( { c o l : arr [ c o l ] f o r c o l in c o l s } )
143 arr = p i p e l i n e . arrays [ 0 ]
144 xyz=np . array ( [ np . array ( df [ ’X ’ ] ) , np . array ( df [ ’Y ’ ] ) , np . array ( df [ ’Z ’
] ) ] ) . T
145 return xyz](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-77-320.jpg)
![ANNEXES
146
147 def V i s u a l i z e ( s e l f ) :
148 i f ( s e l f . filenameSource == " " ) or ( s e l f . filenameTarget == " " ) :
149 Label ( s e l f . l2 , t e x t = " Verify your input " , bg= " red " ) . pack ( )
150 e l i f s e l f . filenameOutput == " " :
151 Label ( s e l f . l2 , t e x t = " Wait . . . " , bg= " red " ) . pack ( )
152 s e l f . s o u r c e P i p e l i n e = s e l f . r e a d L a s F i l e ( s e l f . filenameSource )
153 s e l f . t a r g e t P i p e l i n e = s e l f . r e a d L a s F i l e ( s e l f . filenameTarget )
154 xyzSource= s e l f . pipelineToxyz ( s e l f . s o u r c e P i p e l i n e )
155 xyzTarget = s e l f . pipelineToxyz ( s e l f . t a r g e t P i p e l i n e )
156 xyzoutput = s e l f . pipelineToxyz ( s e l f . o u t P i p e l i n e )
157 # Renderer
158
159 #TARGET POINTCLOUD
160 pointCloud = PointCloud ( )
161 f o r k in range ( len ( xyzSource ) ) :
162 pointCloud . addPoint ( xyzSource [ k ] )
163 sourceActor = pointCloud . vtkActor
164
165 sourceActor . GetMapper ( ) . S c a l a r V i s i b i l i t y O f f ( )
166 sourceActor . GetProperty ( ) . SetColor ( 1 , 0 , 0) # ( R , G, B )
167 sourceActor . GetProperty ( ) . S e t P o i n t S i z e ( 4 )
168
169
170 #TARGET POINTCLOUD
171 pointCloud2 = PointCloud ( )
172 f o r k in range ( len ( xyzTarget ) ) :
173 pointCloud2 . addPoint ( xyzTarget [ k ] )
174 t a r g e t A c t o r = pointCloud2 . vtkActor
175
176 t a r g e t A c t o r . GetMapper ( ) . S c a l a r V i s i b i l i t y O f f ( )
177 t a r g e t A c t o r . GetProperty ( ) . SetColor ( 0 , 0 , 1 ) # ( R , G, B )
178 t a r g e t A c t o r . GetProperty ( ) . S e t P o i n t S i z e ( 4 )
179
180
181
182
183 #OUTPUT POINTCLOUD
184
185 outputPointCloud = PointCloud ( )
186 f o r k in range ( len ( xyzoutput ) ) :
187 outputPointCloud . addPoint ( xyzoutput [ k ] )](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-78-320.jpg)
![ANNEXES
188 outputActor = outputPointCloud . vtkActor
189
190 outputActor . GetMapper ( ) . S c a l a r V i s i b i l i t y O f f ( )
191 outputActor . GetProperty ( ) . SetColor ( 0 , 1 , 0) # ( R , G, B )
192 outputActor . GetProperty ( ) . S e t P o i n t S i z e ( 4 )
193
194 renderer = vtk . vtkRenderer ( )
195 renderWindow = vtk . vtkRenderWindow ( )
196 # i n t e r a c t o r
197 renderWindowInteractor = vtk . vtkRenderWindowInteractor ( )
198
199 renderer . AddActor ( sourceActor )
200 renderer . AddActor ( t a r g e t A c t o r )
201 renderer . AddActor ( outputActor )
202
203 renderer . SetBackground ( 0 , 0 , 0)
204 renderer . ResetCamera ( )
205
206 # Render Window
207
208 renderWindow . AddRenderer ( renderer )
209 # I n t e r a c t o r
210
211 renderWindowInteractor . SetRenderWindow ( renderWindow )
212 # Begin I n t e r a c t i o n
213 renderWindow . Render ( )
214 renderWindowInteractor . S t a r t ( )
215
216 " " " f i g = p l t . f i g u r e ( )
217 ax = f i g . add_subplot ( 1 1 1 , p r o j e c t i o n = ’3d ’ )
218 ax . p l o t ( xyzSource [ : , 0 ] , xyzSource [ : , 1 ] , xyzSource [ : , 2 ] )
219 p l t . show ( )
220
221
222 l a b e l = Label ( s e l f , t e x t =" ICP i s Running . . . " , bg =" yellow " )
223 l a b e l . pack ( ) " " "
224
225 def Compute ( s e l f ) :
226 # Verify input t e s t
227 i f s e l f . filenameSource == " " or s e l f . filenameTarget == " " :
228 Label ( s e l f . l2 , t e x t = " Verify your input " , bg= " red " ) . pack ( )
229 #TRACE MAX ITERATION](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-79-320.jpg)
![ANNEXES
230 x= s e l f . spinbox . get ( )
231 l a b e l = Label ( s e l f . l2 , t e x t = " ICP s t a r t running with " + x + "
i t e r a t i o n " , fg = " red " )
232 l a b e l . pack ( )
233
234 s e l f . s o u r c e P i p e l i n e = s e l f . r e a d L a s F i l e ( s e l f . filenameSource )
235 s e l f . t a r g e t P i p e l i n e = s e l f . r e a d L a s F i l e ( s e l f . filenameTarget )
236
237 xyzSource= s e l f . pipelineToxyz ( s e l f . s o u r c e P i p e l i n e )
238 xyzTarget = s e l f . pipelineToxyz ( s e l f . t a r g e t P i p e l i n e )
239
240 s t a r t = time . process_time ( )
241
242 t a r g e t P o i n t s = vtk . v t k P o i n t s ( )
243 s o u r c e P o i n t s = vtk . v t k P o i n t s ( )
244 t a r g e t V e r c t i c e s = vtk . vtkCellArray ( )
245 s o u r c e V e r c t i c e s = vtk . vtkCellArray ( )
246
247 t a r g e t = vtk . vtkPolyData ( )
248 source = vtk . vtkPolyData ( )
249
250 f o r i in range ( len ( xyzSource ) ) :
251 id = s o u r c e P o i n t s . I n s e r t N e x t P o i n t ( xyzSource [ i ] [ 0 ] , xyzSource [ i
] [ 1 ] , xyzSource [ i ] [ 2 ] )
252 s o u r c e V e r c t i c e s . I n s e r t N e x t C e l l ( 1 )
253 s o u r c e V e r c t i c e s . I n s e r t C e l l P o i n t ( id )
254
255 f o r i in range ( len ( xyzTarget ) ) :
256 id = t a r g e t P o i n t s . I n s e r t N e x t P o i n t ( xyzTarget [ i ] [ 0 ] , xyzTarget [ i
] [ 1 ] , xyzTarget [ i ] [ 2 ] )
257 t a r g e t V e r c t i c e s . I n s e r t N e x t C e l l ( 1 )
258 t a r g e t V e r c t i c e s . I n s e r t C e l l P o i n t ( id )
259
260
261 t a r g e t . S e t P o i n t s ( t a r g e t P o i n t s )
262 source . S e t P o i n t s ( s o u r c e P o i n t s )
263 t a r g e t . S e t V e r t s ( t a r g e t V e r c t i c e s )
264 source . S e t V e r t s ( s o u r c e V e r c t i c e s )
265 i f vtk . VTK_MAJOR_VERSION <= 5 :
266 t a r g e t . Update ( )
267 source . Update ( )
268](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-80-320.jpg)
![ANNEXES
269 # ============ run ICP ==============
270 icp = vtk . v t k I t e r a t i v e C l o s e s t P o i n t T r a n s f o r m ( )
271 #RMS
272 icp . SetMaximumMeanDistance ( 0 . 0 0 0 0 1 )
273 icp . CheckMeanDistanceOn ( )
274 icp . SetSource ( source )
275 icp . SetTarget ( t a r g e t )
276 icp . GetLandmarkTransform ( ) . SetModeToRigidBody ( )
277 # icp . DebugOn ( )
278 icp . SetMaximumNumberOfIterations ( s e l f . maxIteration ( ) )
279 #SAMPLING WITH ALL THE POINT CLOUD
280 icp . SetMaximumNumberOfLandmarks ( source . GetNumberOfPoints ( ) ) ;
281 icp . StartByMatchingCentroidsOn ( )
282 icp . Modified ( )
283 icp . Update ( )
284
285 i c p T r a n s f o r m F i l t e r = vtk . vtkTransformPolyDataFilter ( )
286 i f vtk . VTK_MAJOR_VERSION <= 5 :
287 i c p T r a n s f o r m F i l t e r . SetInput ( source )
288 e l s e :
289 i c p T r a n s f o r m F i l t e r . SetInputData ( source )
290 i c p T r a n s f o r m F i l t e r . SetTransform ( icp )
291 i c p T r a n s f o r m F i l t e r . Update ( )
292 transformedSource = i c p T r a n s f o r m F i l t e r . GetOutput ( )
293
294 p r i n t ( icp . GetMeanDistance ( ) )
295 #TRACE Distance
296 d i s t = Label ( s e l f . l2 , t e x t = " Mean d i s t a n c e i s " + s t r ( icp .
GetMeanDistance ( ) ) , fg = " black " , font =( " A r i a l " , 11) ) . pack ( )
297
298 e l a p s e d _ t i m e _ s e c s = time . process_time ( ) −s t a r t
299
300 msg = " ICP Execution took : " + s t r ( e l a p s e d _ t i m e _ s e c s ) + " secs "
301
302
303 Label ( s e l f . l2 , t e x t =msg , fg = " green " , font =( " A r i a l " , 10) ) . pack ( )
304 output =[]
305 f o r index in range ( len ( xyzSource ) ) :
306 point = [ 0 , 0 , 0 ]
307 transformedSource . GetPoint ( index , point )
308 # output p o i n t s in a l i s t
309 output = output +[ point ]](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-81-320.jpg)
![ANNEXES
310 # p r i n t ( output )
311 a l l x =[]
312 a l l y =[]
313 a l l z =[]
314 f o r index in range ( len ( xyzSource ) ) :
315 a l l x . append ( output [ index ] [ 0 ] )
316 a l l y . append ( output [ index ] [ 1 ] )
317 a l l z . append ( output [ index ] [ 2 ] )
318
319 header = laspy . header . Header ( )
320 s e l f . filenameOutput = s e l f . e . get ( )
321 o u t f i l e = laspy . f i l e . F i l e ( s e l f . filenameOutput , mode= "w" , header=
header )
322
323 xmin = np . f l o o r ( np . min ( a l l x ) )
324 ymin = np . f l o o r ( np . min ( a l l y ) )
325 zmin = np . f l o o r ( np . min ( a l l z ) )
326 o u t f i l e . header . o f f s e t = [ xmin , ymin , zmin ]
327 o u t f i l e . header . s c a l e = [ 0 . 0 0 0 0 0 0 0 1 , 0 . 0 0 0 0 0 0 0 1 , 0 . 0 0 0 0 0 0 0 1 ]
328
329 o u t f i l e . x =np . array ( a l l x )
330 o u t f i l e . y =np . array ( a l l y )
331 o u t f i l e . z=np . array ( a l l z )
332 o u t f i l e . c l o s e ( )
333
334 s e l f . o u t P i p e l i n e = s e l f . r e a d L a s F i l e ( s e l f . filenameOutput )
335 v= Label ( s e l f . l2 , t e x t = " You can V i s u a l i z e r e s u l t s now" , fg = " white "
, bg= " red " ) . pack ( )
336
337
338 c l a s s PointCloud :
339
340 def _ _ i n i t _ _ ( s e l f , zMin = −10.0 , zMax = 1 0 . 0 , maxNumPoints=1 e6 ) :
341 s e l f . maxNumPoints = maxNumPoints
342 s e l f . vtkPolyData = vtk . vtkPolyData ( )
343 s e l f . c l e a r P o i n t s ( )
344 mapper = vtk . vtkPolyDataMapper ( )
345 mapper . SetInputData ( s e l f . vtkPolyData )
346 #mapper . SetColorModeToDefault ( )
347 mapper . SetScalarRange ( zMin , zMax )
348 mapper . S e t S c a l a r V i s i b i l i t y ( 1 )
349 s e l f . vtkActor = vtk . vtkActor ( )](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-82-320.jpg)
![ANNEXES
350 s e l f . vtkActor . SetMapper ( mapper )
351
352
353 def addPoint ( s e l f , point ) :
354 i f s e l f . v t k P o i n t s . GetNumberOfPoints ( ) < s e l f . maxNumPoints :
355 p o i n t I d = s e l f . v t k P o i n t s . I n s e r t N e x t P o i n t ( point [ : ] )
356 s e l f . vtkDepth . InsertNextValue ( point [ 2 ] )
357 s e l f . v t k C e l l s . I n s e r t N e x t C e l l ( 1 )
358 s e l f . v t k C e l l s . I n s e r t C e l l P o i n t ( p o i n t I d )
359 e l s e :
360 r = random . randint ( 0 , s e l f . maxNumPoints )
361 s e l f . v t k P o i n t s . S e t P o i n t ( r , point [ : ] )
362 s e l f . v t k C e l l s . Modified ( )
363 s e l f . v t k P o i n t s . Modified ( )
364 s e l f . vtkDepth . Modified ( )
365
366 def c l e a r P o i n t s ( s e l f ) :
367 s e l f . v t k P o i n t s = vtk . v t k P o i n t s ( )
368 s e l f . v t k C e l l s = vtk . vtkCellArray ( )
369 s e l f . vtkDepth = vtk . vtkDoubleArray ( )
370 s e l f . vtkDepth . SetName ( ’ DepthArray ’ )
371 s e l f . vtkPolyData . S e t P o i n t s ( s e l f . v t k P o i n t s )
372 s e l f . vtkPolyData . S e t V e r t s ( s e l f . v t k C e l l s )
373 s e l f . vtkPolyData . GetPointData ( ) . S e t S c a l a r s ( s e l f . vtkDepth )
374 s e l f . vtkPolyData . GetPointData ( ) . S e t A c t i v e S c a l a r s ( ’ DepthArray ’ )
375
376
377 i f __name__ == " __main__ " :
378
379 import warnings
380 warnings . s i m p l e f i l t e r ( a c t i o n = ’ ignore ’ , category =FutureWarning )
381 App ( )
Utilitaire ICP Basé sur OPEN3D
1
2 #NEEDS TKINTER and OPEN3D
3 #BY Mahdi SMUIDA
4 # 2018
5 #TKINTER
6 import t k i n t e r as tk
7 from t k i n t e r . messagebox import ∗](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-83-320.jpg)


![ANNEXES
80
81
82 def maxIteration ( s e l f ) :
83 x= s e l f . spinbox . get ( )
84 type ( x ) == i n t
85 i f i n t ( x ) <2:
86 messagebox . showerror ( "ERROR" , "MAX ITERATION VALUE MUST BE AN
INTEGER > 2 " )
87 e l s e :
88 return i n t ( x )
89
90
91 def recupereSource ( s e l f ) :
92 s e l f . filenameSource = askopenfilename ( t i t l e = " Open Source PCD F i l e " ,
f i l e t y p e s =[( ’ pcd f i l e s ’ , ’ . pcd ’ ) ] )
93 i f s e l f . filenameSource != " " :
94 l a b e l = Label ( s e l f . l2 , t e x t = " Source point Cloud i s s u c c e s s f u l l y
loaded . . . " , bg= " yellow " )
95 l a b e l . pack ( )
96 s e l f . source = read_point_cloud ( s e l f . filenameSource )
97 e l s e :
98 Label ( s e l f . l2 , t e x t = " Choose your Source point Cloud Pl e as e " , bg
= " red " ) . pack ( )
99
100
101
102 def recupereTarget ( s e l f ) :
103 s e l f . filenameTarget = askopenfilename ( t i t l e = " Open Source PCD F i l e " ,
f i l e t y p e s =[( ’ pcd f i l e s ’ , ’ . pcd ’ ) , ( ’ pcd f i l e s ’ , ’ . pcd ’ ) ] )
104 i f s e l f . filenameTarget != " " :
105 l a b e l = Label ( s e l f . l2 , t e x t = " Target point Cloud i s s u c c e s s f u l l y
loaded . . . " , bg= " yellow " )
106 l a b e l . pack ( )
107
108 s e l f . t a r g e t = read_point_cloud ( s e l f . filenameTarget )
109 e l s e :
110 Label ( s e l f . l2 , t e x t = " Choose your Target point Cloud Pl e as e " , bg
= " red " ) . pack ( )
111
112
113 def V i s u a l i z e ( s e l f ) :
114 s e l f . source . paint_uniform_color ( [ 1 , 0 , 0 ] )](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-86-320.jpg)
![ANNEXES
115 s e l f . t a r g e t . paint_uniform_color ( [ 0 , 0 , 1 ] )
116 draw_geometries ( [ s e l f . source , s e l f . t a r g e t ] )
117
118 def ComputePlane ( s e l f ) :
119 sourceToArray= np . asarray ( s e l f . source . p o i n t s )
120 targetToArray = np . asarray ( s e l f . t a r g e t . p o i n t s )
121 p r i n t ( len ( sourceToArray ) )
122 p r i n t ( len ( targetToArray ) )
123 # s e u i l
124 t h r e s h o l d = 0 . 0 2
125 # I n i t i a l T r a n s l a t i o n
126 t r a n s _ i n i t = np . asarray (
127 [ [ 0 . 8 6 2 , 0 . 0 1 1 , −0.507 , 0 . 5 ] ,
128 [ −0.139 , 0 . 9 6 7 , −0.215 , 0 . 7 ] ,
129 [ 0 . 4 8 7 , 0 . 2 5 5 , 0 . 8 3 5 , −1.4] ,
130 [ 0 . 0 , 0 . 0 , 0 . 0 , 1 . 0 ] ] )
131 # I n i t i a l alignment
132 e v a l u a t i o n = e v a l u a t e _ r e g i s t r a t i o n ( s e l f . source , s e l f . target ,
threshold , t r a n s _ i n i t )
133 Label ( s e l f . l2 , t e x t = " Before ICP " + s t r ( e v a l u a t i o n ) , fg = " red " ) . pack ( )
134 #COMPUTE r e g i s t r a t i o n with point to point e s t i m a t i o n
135 reg_p2l = r e g i s t r a t i o n _ i c p ( s e l f . source , s e l f . target , threshold ,
t r a n s _ i n i t , TransformationEstimationPointToPlane ( ) , ICPConvergenceCriteria
( max_iteration = s e l f . maxIteration ( ) ) )
136 # apply tr an sf or ma ti on
137 reg_p2l . t ra nsf or ma ti on
138
139 Label ( s e l f . l2 , t e x t = " After ICP " + s t r ( reg_p2l ) , fg = " green " ) . pack ( )
140 Label ( s e l f . l2 , t e x t = " Transformation matrix i s : n " + s t r ( reg_p2l .
t ran sf or ma ti on ) , fg = " green " ) . pack ( )
141 s e l f . tr an sf orm at io n = reg_p2l . tr an sf or ma ti on
142
143 def Compute ( s e l f ) :
144 sourceToArray= np . asarray ( s e l f . source . p o i n t s )
145 targetToArray = np . asarray ( s e l f . t a r g e t . p o i n t s )
146 # s e u i l
147 t h r e s h o l d = 0 . 0 2
148 # I n i t i a l T r a n s l a t i o n
149 t r a n s _ i n i t = np . asarray (
150 [ [ 0 . 8 6 2 , 0 . 0 1 1 , −0.507 , 0 . 5 ] ,
151 [ −0.139 , 0 . 9 6 7 , −0.215 , 0 . 7 ] ,
152 [ 0 . 4 8 7 , 0 . 2 5 5 , 0 . 8 3 5 , −1.4] ,](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-87-320.jpg)
![ANNEXES
153 [ 0 . 0 , 0 . 0 , 0 . 0 , 1 . 0 ] ] )
154 # I n i t i a l alignment
155 e v a l u a t i o n = e v a l u a t e _ r e g i s t r a t i o n ( s e l f . source , s e l f . target ,
threshold , t r a n s _ i n i t )
156 Label ( s e l f . l2 , t e x t = " Before ICP " + s t r ( e v a l u a t i o n ) , fg = " red " ) . pack ( )
157 #COMPUTE r e g i s t r a t i o n with point to point e s t i m a t i o n
158 reg_p2p = r e g i s t r a t i o n _ i c p ( s e l f . source , s e l f . target , threshold ,
t r a n s _ i n i t , TransformationEstimationPointToPoint ( ) , ICPConvergenceCriteria
( max_iteration = s e l f . maxIteration ( ) ) )
159 reg_p2p . t ran sf or ma ti on
160
161 Label ( s e l f . l2 , t e x t = " After ICP " + s t r ( reg_p2p ) , fg = " green " ) . pack ( )
162 Label ( s e l f . l2 , t e x t = " Transformation matrix i s : n " + s t r ( reg_p2p .
t ran sf or ma ti on ) , fg = " green " ) . pack ( )
163 s e l f . tr an sf orm at io n =reg_p2p . tr an sf or ma ti on
164
165 def d r a w _ r e g i s t r a t i o n _ r e s u l t ( s e l f , source , target , tr ans fo rm at io n ) :
166 source_temp = copy . deepcopy ( source )
167 target_temp = copy . deepcopy ( t a r g e t )
168 source_temp . paint_uniform_color ( [ 0 , 1 , 0 ] )
169 target_temp . paint_uniform_color ( [ 0 , 0 , 0 . 9 2 9 ] )
170 source_temp . transform ( t ra ns fo rm at io n )
171 draw_geometries ( [ source_temp , target_temp ] )
172
173
174
175 def v i s u a l i z e R e s u l t ( s e l f ) :
176 s e l f . d r a w _ r e g i s t r a t i o n _ r e s u l t ( s e l f . source , s e l f . target , s e l f .
t ran sf or ma ti on )
177
178
179
180 i f __name__ == " __main__ " :
181
182 import warnings
183 warnings . s i m p l e f i l t e r ( a c t i o n = ’ ignore ’ , category =FutureWarning )
184 App ( )
Maquette ICP sur Jupyter Notebook
1 # coding : utf −8
2](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-88-320.jpg)
![ANNEXES
3 # In [ 1 ] :
4
5 " " " " t h i s notebook i s written by− Mahdi SMIDA { email : eng . smida@gmail . com
} " " "
6 " " " ∗ . Las f o r pointCloud " " "
7 # L i b r a r i e s
8 import numpy as np
9 from m p l _ t o o l k i t s . mplot3d import Axes3D
10 import m a t p l o t l i b . pyplot as p l t
11 import time
12 import pdal
13 import json
14 import ipyvolume . pylab as p3
15 import pandas as pd
16 import math
17
18
19 # In [ 2 ] :
20
21 # PointCloud Class
22 c l a s s PC ( o b j e c t ) :
23 def _ _ i n i t ( s e l f , other ) :
24 i f i s i n s t a n c e ( other , PC ) :
25 s e l f . initFromPC ( other )
26 s e l f . pts = None
27 s e l f . normPts=None
28 s e l f .Num= 0
29 s e l f . center = None
30
31 def getPointCloudInformation ( s e l f ) :
32 return " < Point cloud Points :% s normPts :% s Num:% s center :% s > " % (
s e l f . pts , s e l f . normPts , s e l f .Num , s e l f . center )
33
34 def initFromNdArray ( s e l f , other ) :
35 s e l f . pts = np . copy ( other )
36 s e l f .Num = other . shape [ 0 ]
37 s e l f . normalize ( )
38
39 def Sampling ( s e l f ) :
40 x= s e l f . pts [ 0 : : 1 6 ]
41 return x
42](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-89-320.jpg)
![ANNEXES
43 def initFromArray ( s e l f , other ) :
44 s e l f . pts =np . copy ( other )
45 s e l f .Num= len ( other )
46 s e l f . normalize ( )
47
48 def initFromPC ( s e l f , other ) :
49 a s s e r t i s i n s t a n c e ( other , PC )
50 s e l f . pts = np . copy ( other . pts )
51 s e l f .Num = other .Num
52 s e l f . normalize ( )
53
54 def normalize ( s e l f ) :
55 a s s e r t s e l f .Num !=0
56 s e l f . center = np . mean ( s e l f . pts , a x i s =0)
57 s e l f . normPts = s e l f . pts − s e l f . center
58
59 def applyTransformation ( s e l f , R=None , T=None ) :
60 s e l f . pts = s e l f . pts . dot ( R . T ) +T . T
61 s e l f . normalize ( )
62
63 def DisplayPcWithMatplotlib ( pointCloud ) :
64 # MatplotLib v i s u a l i s a t i o n
65 f i g u r e = p l t . f i g u r e ( )
66 ax = f i g u r e . add_subplot ( 1 1 1 , p r o j e c t i o n = ’ 3d ’ )
67 ax . s c a t t e r ( pointCloud . pts [ : , 0 ] , pointCloud . pts [ : , 1 ] , pointCloud . pts
[ : , 2 ] , c= ’ r ’ , marker= ’ . ’ )
68 ax . s e t _ x l a b e l ( ’X ’ )
69 ax . s e t _ y l a b e l ( ’Y ’ )
70 ax . s e t _ z l a b e l ( ’Z ’ )
71 p l t . show ( )
72
73 def DisplayPcWithIpyvolume ( pointCloud , c l r ) :
74 p3 . f i g u r e ( )
75 s = p3 . s c a t t e r ( pointCloud . pts [ : , 0 ] , pointCloud . pts [ : , 1 ] , pointCloud .
pts [ : , 2 ] , c o l o r = clr , s i z e =2)
76 p3 . squarelim ( )
77 p3 . show ( )
78
79
80
81 # In [ 3 ] :
82](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-90-320.jpg)
![ANNEXES
83
84 # Basic i t e r a t i v e C l o s e s t point algorithm
85 c l a s s BasicICP ( o b j e c t ) :
86 # i n i t
87 def _ _ i n i t _ _ ( s e l f , source , target , r e i n i t = F a l s e ) :
88 s e l f . source = source
89 s e l f . t a r g e t = t a r g e t
90 a s s e r t s e l f . source .Num == s e l f . t a r g e t .Num
91 s e l f . r e s u l t = PC ( )
92 s e l f . r e s u l t . initFromPC ( source )
93 PC . initFromPC ( s e l f . r e s u l t , source )
94 s e l f . r e i n i t = r e i n i t
95 # Point Cloud R e g i s t r a t i o n return Rotation and t r a n s l a t i o n
96 def getPCRegistation ( s e l f , t r g t ) :
97 a s s e r t s e l f . r e s u l t and t r g t
98 a s s e r t s e l f . r e s u l t .Num == t r g t .Num
99
100 H = np . dot ( s e l f . r e s u l t . normPts . T , t r g t . normPts )
101 U, S , Vt = np . l i n a l g . svd (H)
102 R=np . dot ( Vt . T , U . T )
103 # i f Refkection
104 i f np . l i n a l g . det ( R ) < 0 :
105 Vt [ 2 , : ] ∗= −1
106 R = np . dot ( Vt . T , U . T )
107 #Warn i f SVD i s not c o r r e c t l y performed
108 Epsilon =0.0001
109 i f abs ( np . l i n a l g . det ( R ) −1.0)> Epsilon :
110 Warning ( ’ Point Cloud R e g i s t r a t i o n u n s t a b l e ! ’ )
111 T= t r g t . center −s e l f . r e s u l t . center . dot ( R . T )
112 p r i n t ( R )
113 p r i n t ( T )
114 return R , T
115 #Compute correspondence
116 def computeCorrespondence ( s e l f ) :
117 a s s e r t s e l f . r e s u l t and s e l f . t a r g e t
118 a s s e r t s e l f . r e s u l t .Num == s e l f . t a r g e t .Num
119 #Main icp algorithm
120 def solveMe ( s e l f ) :
121 p r i n t ( ’ Solve Me ICP Algorithm ’ , s e l f . _ _ c l a s s _ _ . __name__ )
122 d i s t a n c e t h r e s h o l d =0.001
123 maxIteration =10
124 i t e r a t i o n =0](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-91-320.jpg)
![ANNEXES
125 currentDist , t r g t = s e l f . computeCorrespondence ( )
126 p r i n t ( " Current Distance before S t a r t i n g %f " , c u r r e n t D i s t )
127 # BasicICP ( loop )
128 while c u r r e n t D i s t > d i s t a n c e t h r e s h o l d and i t e r a t i o n < maxIteration :
129 #Compute Transformation
130 R , T = s e l f . getPCRegistation ( t r g t )
131 #Apply t ran sf or ma ti on
132 s e l f . r e s u l t . applyTransformation ( R , T )
133 # Compute correspondence
134 currentDist , t r g t = s e l f . computeCorrespondence ( )
135 # Next i t e r a t i o n
136 i t e r a t i o n +=1
137 p r i n t ( " I t e r a t i o n : %5d , with t o t a l d i s t a n c e : %f " % ( i t e r a t i o n ,
c u r r e n t D i s t ) )
138 return s e l f . r e s u l t . pts , s e l f . r e s u l t . DisplayPcWithIpyvolume ( " red " )
139
140
141
142 # In [ 4 ] :
143
144 c l a s s ICP ( BasicICP ) :
145 def _ _ i n i t _ _ ( s e l f , source , target , r e i n i t = F a l s e ) :
146 super ( ICP , s e l f ) . _ _ i n i t _ _ ( source , target , r e i n i t )
147
148 def g e t P C R e g i s t r a t i o n ( s e l f , t r g t ) :
149 return super ( ICP , s e l f ) . g e t P C R e g i s t r a t i o n ( t r g t )
150
151 def computeCorrespondence ( s e l f ) :
152 super ( ICP , s e l f ) . computeCorrespondence ( )
153 # i n i t index Array & t o t a l d i s t a n c e to zeros
154 indexArray = np . zeros ( s e l f . r e s u l t .Num, dtype=np . i n t )
155 t o t a l D i s t a n c e = 0 . 0
156
157 f o r r e s u l t I n d e x , r e s u l t V a l u e in enumerate ( s e l f . r e s u l t . pts ) :
158 minIndex , minDistance = −1, math . i n f
159 f o r targetIndex , t a r g e t V a l u e in enumerate ( s e l f . t a r g e t . Sampling
( ) ) :
160 d i s t a n c e = np . l i n a l g . norm ( r e s u l t V a l u e − t a r g e t V a l u e )
161 i f d i s t a n c e < minDistance :
162 minDistance , minIndex = distance , t a r g e t I n d e x
163 indexArray [ r e s u l t I n d e x ] = minIndex
164 t o t a l D i s t a n c e += minDistance](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-92-320.jpg)
![ANNEXES
165
166 t r g t = PC ( )
167 xyz= s e l f . t a r g e t . pts [ indexArray , 0 : 3 ]
168 t r g t . initFromNdArray ( xyz )
169 PC . initFromNdArray ( trgt , xyz )
170 return t o t a l D i s t a n c e , t r g t
171
172
173 # In [ 5 ] :
174
175 #Read Las F i l e
176 filename = ’ . / bun045 . l a s ’
177 pip= {
178 " p i p e l i n e " : [
179 {
180 " type " : " r e a d e r s . l a s " ,
181 " filename " : filename
182 } ,
183
184 ]
185 }
186 p i p e l i n e = pdal . P i p e l i n e ( json . dumps ( pip ) )
187 p i p e l i n e . v a l i d a t e ( )
188 get_ipython ( ) . run_line_magic ( ’ time ’ , ’ n_points = p i p e l i n e . execute ( ) ’ )
189 p r i n t ( ’ P i p e l i n e s e l e c t e d { } p o i n t s ( { : . 1 f } pts ) ’ . format ( n_points , n_points )
)
190
191 " " " transform l a s f i l e information j u s t to XYZ information to our point
Cloud c l a s s " " "
192 arr = p i p e l i n e . arrays [ 0 ]
193 d e s c r i p t i o n = arr . dtype . descr
194 c o l s = [ c o l f o r col , __ in d e s c r i p t i o n ]
195 df = pd . DataFrame ( { c o l : arr [ c o l ] f o r c o l in c o l s } )
196 arr = p i p e l i n e . arrays [ 0 ]
197 xyz=np . array ( [ np . array ( df [ ’X ’ ] ) , np . array ( df [ ’Y ’ ] ) , np . array ( df [ ’Z ’ ] ) ] ) . T
198 pointCloud = PC ( )
199 pointCloud . initFromArray ( xyz )
200 PC . initFromArray ( pointCloud , xyz )
201 pointCloud . DisplayPcWithIpyvolume ( ’ red ’ )
202
203
204 # In [ 6 ] :](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-93-320.jpg)
![ANNEXES
205
206 #Read Las F i l e
207 filename = ’ . / bun090 . l a s ’
208 pip= {
209 " p i p e l i n e " : [
210 {
211 " type " : " r e a d e r s . l a s " ,
212 " filename " : filename
213 } ,
214 ]
215 }
216 p i p e l i n e = pdal . P i p e l i n e ( json . dumps ( pip ) )
217 p i p e l i n e . v a l i d a t e ( )
218 get_ipython ( ) . run_line_magic ( ’ time ’ , ’ n_points = p i p e l i n e . execute ( ) ’ )
219 p r i n t ( ’ P i p e l i n e s e l e c t e d { } p o i n t s ( { : . 1 f } pts ) ’ . format ( n_points , n_points )
)
220
221 " " " transform l a s f i l e information j u s t to XYZ information to our point
Cloud c l a s s " " "
222 arr = p i p e l i n e . arrays [ 0 ]
223 d e s c r i p t i o n = arr . dtype . descr
224 c o l s = [ c o l f o r col , __ in d e s c r i p t i o n ]
225 df = pd . DataFrame ( { c o l : arr [ c o l ] f o r c o l in c o l s } )
226 arr = p i p e l i n e . arrays [ 0 ]
227 xyz=np . array ( [ np . array ( df [ ’X ’ ] ) , np . array ( df [ ’Y ’ ] ) , np . array ( df [ ’Z ’ ] ) ] ) . T
228 # p r i n t ( ( output ) )
229 pointCloud2 = PC ( )
230 pointCloud2 . initFromArray ( xyz )
231 PC . initFromArray ( pointCloud2 , xyz )
232 pointCloud2 . DisplayPcWithIpyvolume ( " yellow " )
233 # p r i n t ( output )
234
235
236 # In [ 7 ] :
237
238 i c p S o l v e r =ICP ( pointCloud , pointCloud2 , F a l s e )
239 # p r i n t ( pointCloud . Sampling ( ) )
240 get_ipython ( ) . run_line_magic ( ’ time ’ , ’ i c p S o l v e r . solveMe ( ) ’ )
241
242
243 # In [ 8 ] :
244](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-94-320.jpg)
![ANNEXES
245 p r i n t ( len ( pointCloud . Sampling ( ) ) )
246
247
248 # In [ 9 ] :
249
250 p3 . f i g u r e ( )
251 # Source
252 s = p3 . s c a t t e r ( pointCloud . pts [ : , 0 ] , pointCloud . pts [ : , 1 ] , pointCloud . pts
[ : , 2 ] , c o l o r = " black " , s i z e =2)
253 # D e s t i n a t i o n
254 s = p3 . s c a t t e r ( pointCloud2 . pts [ : , 0 ] , pointCloud2 . pts [ : , 1 ] , pointCloud2 . pts
[ : , 2 ] , c o l o r = " yellow " , s i z e =2)
255 s= p3 . s c a t t e r ( i c p S o l v e r . r e s u l t . pts [ : , 0 ] , i c p S o l v e r . r e s u l t . pts [ : , 1 ] , i c p S o l v e r
. r e s u l t . pts [ : , 2 ] , c o l o r = " blue " , s i z e =2)
256 #p3 . xyzlim ( − 0 . 2 , 0 . 2 )
257 #p3 . animation_control ( s ) # shows c o n t r o l s f o r animation c o n t r o l s
258 p3 . show ( )
Classe ICP parallèle
1 c l a s s IcpPara ( BasicICP ) :
2
3
4 # ________________________________________________________________
5 def _ _ i n i t _ _ ( s e l f , source , target , NumCore=0 , r e i n i t = F a l s e ) :
6 super ( IcpPara , s e l f ) . _ _ i n i t _ _ ( source , target , r e i n i t )
7 #Cuda u t i l i t i e s
8 s e l f . computeCorrespondenceWithCuda=None
9 s e l f . distances_gpu =None
10 s e l f . NumCore= s e l f . source .Num i f NumCore<=0 e l s e NumCore
11 p r i n t ( " Cuda cores f o r P a r a l l e l ICP s e t to " , s e l f . NumCore )
12 s e l f . initCuda ( )
13 # ________________________________________________________________
14
15 def initCuda ( s e l f ) :
16 " " "
17 I n i t i a l i z e CUDA environment
18 − Create CUDA C program , and compile i t
19 − Copy d e s t i n a t i o n PointCloud to CUDA g l o b a l and constant value
20 − Create handler of f i n d _ c l o s e s t f u nc t io n in CUDA
21 " " "
22 mod = SourceModule ( " " "](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-95-320.jpg)
![ANNEXES
23 # d e f i n e ROW ( " " " + s t r ( s e l f . source .Num) + " " " )
24 # d e f i n e OFFSET ( " " " + s t r ( s e l f . NumCore ) + " " " )
25 __constant__ f l o a t t a r g e t [ROW] [ 3 ] ;
26
27
28 __global__ void getTarget ( f l o a t ∗ r e t ) {
29 i n t idx = threadIdx . x ;
30 r e t [ idx ∗3]= t a r g e t [ idx ] [ 0 ] ;
31 r e t [ idx ∗3+1] = t a r g e t [ idx ] [ 1 ] ;
32 r e t [ idx ∗3+2] = t a r g e t [ idx ] [ 2 ] ;
33 }
34
35
36 __global__ void c l o s e s t P o i n t ( f l o a t ∗ res , f l o a t ∗ ret , f l o a t ∗
d i s t a n c e s )
37 {
38 f o r ( i n t idx = threadIdx . x ; idx < ROW; idx += OFFSET ) {
39 f l o a t x_source = res [ idx ∗ 3 ] ;
40 f l o a t y_source = res [ idx ∗ 3 + 1 ] ;
41 f l o a t z_source = res [ idx ∗ 3 + 2 ] ;
42 f l o a t x_distance , y_distance , z_distance , min_distance ,
d i s t a n c e ;
43 i n t min_index= −1;
44
45 f o r ( i n t i =0 ; i <ROW; i ++) {
46 x _ d i s t a n c e = t a r g e t [ i ] [ 0 ] ;
47 y_distance = t a r g e t [ i ] [ 1 ] ;
48 z _ d i s t a n c e = t a r g e t [ i ] [ 2 ] ;
49
50 d i s t a n c e =( x_source−x _ d i s t a n c e ) ∗ ( x_source−x _ d i s t a n c e ) +
( y_source−y_distance ) ∗ ( y_source−y_distance ) +( z_source −z _ d i s t a n c e ) ∗ (
z_source −z _ d i s t a n c e ) ;
51 i f ( distance < min_distance | | min_index <0) {
52 min_distance = d i s t a n c e ;
53 min_index= i ;
54 }
55 }
56 r e t [ idx ∗ 3 ] = t a r g e t [ min_index ] [ 0 ] ;
57 r e t [ idx ∗3+1] = t a r g e t [ min_index ] [ 1 ] ;
58 r e t [ idx ∗3+2] = t a r g e t [ min_index ] [ 2 ] ;
59 d i s t a n c e s [ idx ] = s q r t ( min_distance ) ;
60 }](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-96-320.jpg)
![ANNEXES
61 }
62 " " " )
63 targetCuda , _ = mod . g e t _ g l o b a l ( ’ t a r g e t ’ )
64 s e l f . t a r g e t . pts . dtype= np . f l o a t 3 2
65 a s s e r t s e l f . t a r g e t . pts . dtype==np . f l o a t 3 2
66 pycuda . d r i v e r . mem_get_info ( )
67 cuda . memcpy_htod ( targetCuda , s e l f . t a r g e t . pts )
68 d i s t a n c e s = np . zeros ( s e l f . source .Num, dtype=np . f l o a t 3 2 )
69 s e l f . distances_gpu = gpuarray . to_gpu ( d i s t a n c e s )
70 s e l f . computeCorrespondenceWithCuda ( ’ c l o s e s t P o i n t ’ )
71 getDistCuda = mod . g e t _ f u n c t i o n ( ’ getDistance ’ )
72 # ________________________________________________________________
73 def g e t P C R e g i s t r a t i o n ( s e l f , t r g t ) :
74 return super ( IcpPara , s e l f ) . g e t P C R e g i s t r a t i o n ( t r g t )
75 # ________________________________________________________________
76 def computeCorrespondence ( s e l f ) :
77 super ( IcpPara , s e l f ) . computeCorrespondence ( )
78 t r g t = np . zeros ( [ s e l f . s r c .Num, 3 ] , dtype=np . f l o a t 3 2 )
79 s e l f . computeCorrespondenceCuda ( cuda . In ( s e l f . r e s u l t . pts ) , cuda . Out (
t r g t ) , s e l f . distances_gpu , block =( s e l f . NumCore , 1 , 1) )
80 return gpuarray . sum ( s e l f . distances_gpu ) . get ( ) , PC ( t r g t )
81
82 # ________________________________________________________________](https://image.slidesharecdn.com/mahdismidarapportmaster2hpc-190920124909/85/Mahdi-smida-rapport-master-2-Calcul-Haute-performance-et-simulation-97-320.jpg)








































