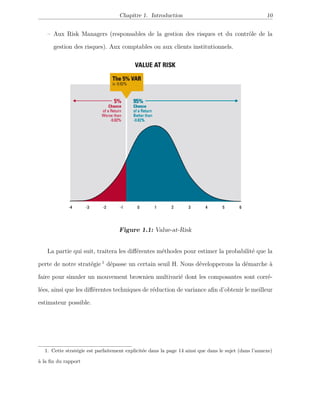
Ce document présente un projet de master sur l'application des méthodes de Monte Carlo pour la réduction de la variance dans le calcul de la valeur à risque (VaR). Il aborde des techniques variées telles que les variables antithétiques, le stratification et la méthode de fonction d'importance. Le travail souligne l'importance des simulations pour évaluer les risques associés à des portefeuilles d'actifs financiers.









![Chapitre 1
INTRODUCTION
1.1 Sujet
Soient S1
, S2
, S3
trois actifs risqués, où Sk
t := Sk
0 exp (µk−
σ2
k
2
)t+σkWk
t et (W1
, W2
, W3
)
sont des mouvements browniens avec la corrélation :
M = Var
W1
1
W2
1
W3
1
=
1 0, 5 0, 5
0, 5 1 0, 5
0, 5 0, 5 1
.
On considère un portefeuille (ou une stratégie) d’investissement qui contient λk actif
risquée Sk
, où λk sont des constantes déterministes (pourraient être négatives). Alors, le
valeur du portefeuille à l’instant t est
Vt = λ1S1
t + λ2S2
t + λ3S3
t
La perte de la stratégie à l’instant T sera donnée par
LT := V0 − VT
L’objectif de ce projet est d’évaluer
P(LT ≥ H) = E[1LT ≥H]
qui consiste une étape essentielle pour calculer le VaR du portefeuille.](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-9-320.jpg)


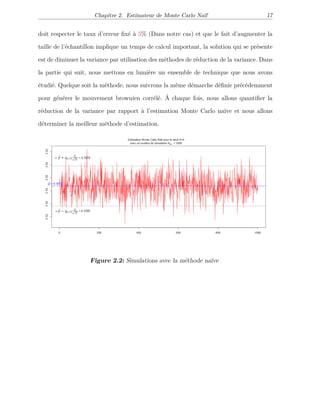
![Chapitre 2
ESTIMATEUR DE MONTE CARLO NAÏF
2.1 Objectif
:
Estimer p = P(LT ≥ H) = E[1LT ≥H] = E[X] par ˆp = 1
n
n
i=1 1LT ≥H d’après la L.F.G.N 1
,
et où ˆp = N(p, σ2
/N) d’après le T.C.L 2
On note que X = 1LT ≥H. On aura besoin pour simuler X, d’écrire X en fonction de
W = (W1, W2, W3) où W → N(µ, M) avec µ = (µ1, µ2, µ3) Par suite, les étapes à suivre
sont alors les suivantes :
1. Simuler 3 variables browniens indépendants,
2. Créer un vecteur de 3 browniens corrélés (méthode de Cholesky),
3. Obtenir un estimateur Monte Carlo naïf
2.2 Étape 1 : Simulation des browniens
1. Simulation de 3 variables uniformes indépendantes u1, u2, u3,
2. Transformation des v.a. 3
uniformes en v.a. normales centrées de variance t :
1. Loi forte des grands nombres
2. Théorème Central limite
3. Variables aléatoires](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-13-320.jpg)
![Chapitre 2. Estimateur de Monte Carlo Naïf 13
(a) si x → φ[x < S] : probabilité de distribution d’une v.a. S normale centrée de
variance 1,
(b) =⇒ (Z1, Z2, Z3) = (φ−1
[u1], φ−1
[u2], φ−1
[u3]) sont 3 v.a. normales centrées de
variance 1 indépendantes,
(c) =⇒ (B1
t , B2
t , B3
t ) = (
√
t × Z1,
√
t × Z2,
√
t × Z3) sont 3 v.a. normales centrées
de variance t indépendantes.
(B1
t , B2
t , B3
t ) sont donc 3 browniens indépendants.
2.3 Étape 2 : Corrélation des browniens
Soient (B1
t , B2
t , B3
t ) 3 browniens indépendants obtenus de l’étape 1.
1. Calcul de la matrice L telle que M = L × LT
(LT
est la transposée de L et
M = Var
W1
1
W2
1
W3
1
) par l’algorithme de Cholesky.
2. W =
W1
1
W2
1
W3
1
= L
B1
1
B2
1
B3
1
est alors le vecteur de browniens corrélés dont nous
avons besoin.
2.4 Étape 3 : Calcul du VaR du portefeuille
Soient (W1
t , W2
t , W3
t ) 3 browniens avec la corrélation M = Var
W1
1
W2
1
W3
1
.
1. Calcul des trois actifs risqués S1
, S2
, S3
tels que
Sk
t = Sk
0 exp (µk −
σ2
k
2
)t + σkWk
t](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-14-320.jpg)


![Chapitre 2. Estimateur de Monte Carlo Naïf 16
L’estimateur final est alors définie par :
ˆp = 1
Nsim
Nsim
j=1 ˆp(j)
et ayant pour variance ˆσ2 = 1
Nsim
Nsim
j=1
ˆσ2
(j)
Nous calculons pour chaque estimateur un intervalle de confiance de niveau α (IC)
ainsi que l’erreur relative .
d’où IC =] ˆp − qα/2
ˆσ√
N
; ˆp + qα/2
ˆσ√
N
[ et l’erreur relative : 1
p
σ2
N
≈ 1
ˆp
ˆσ2
N
−→ + ∞ lorsque
p → +∞
Dans le tableau ci-dessous nous présentons les valeurs obtenues pour différents seuils H.
H N ˆp ˆσ2 Nsim IC
0 103
0.5672 0.2457 103
0.0276 [0.5365 ; 0.5979]
0.2 103
0.1398 0.1202 103
0.0784 [0.1183 ; 0.1613]
0.5 103
0.0024 0.0024 103
0.6435 [63*10−
5; 54 ∗ 10−
5]
0.75 103
1.7e-05 1.7e-05 103
7.669 [238*10−
6; 272 ∗ 10−
6]
1 103
0 0 103
NaN –
Figure 2.1: Tableau des valeurs : Méthode Monte Carlo naïve
2.6 Conclusion
Nous remarquons que pour les valeurs élevées de H les estimations sont presque nulles.
Pour H = 0.2, la valeur de lestimation se détériore pour passer de ≈ 0.56 à ≈ 0.13 . En
augmentant la valeur du seuil H, la variance diminue considérablement par contre on ne
peut pas affirmer que notre estimation est bonne car en plus du fait qu’elle soit faible,
la variance devient égale à l’estimation. Pour H = 0, la variance est égale à ≈ 0.25 ce
qui est considéré comme une valeur assez importante. Cela nous ramène à essayer des
nouvelles méthodes d’estimation autre que l’estimateur Monte Carlo naïf, qui pourront
nous procurer des bonnes estimations et au même temps une variance faible. Puisqu’on](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-17-320.jpg)

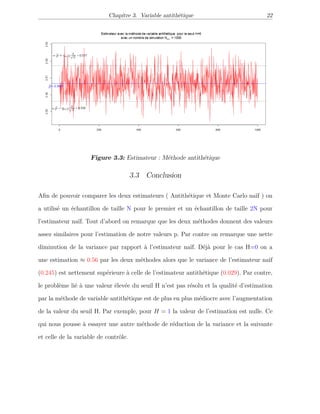
![Chapitre 3
VARIABLE ANTITHÉTIQUE
3.1 Présentation du problème
L’idée du contrôle antithétique est très simple. Nous la présentons dans le cadre du mo-
dèle de Black-Scholes multidimensionnel. Elle est basée sur la propriété de symétrie du
mouvement brownien W
loi
= −W =⇒ ST
loi
= S−
T où :
S−
T =
S
(−)1
T
S
(−)2
T
S
(−)3
T
=
S1
0 exp µ1 −
σ2
1
2
T − σ1W1
T
S2
0 exp µ2 −
σ2
2
2
T − σ2W2
T
S3
0 exp µ3 −
σ2
3
2
T − σ3W3
T
En notant alors que V
−(i)
T = −S
(−)1
T − S
(−)2
T − S
(−)3
T
et en posant L
−(i)
T = V0 − V
−(i)
T on a alors que X
(i)
− = 1L
−(i)
T >H
est de même loi que X(i)
. Soit g(−WT ) = 1L
−(i)
T >H
Ce qui implique que
E[(g(WT )+g(−WT ))
2
] = E[g(WT )]
Si V ar[(g(WT )+g(−WT ))
2
] < V ar[g(WT )]
2
, ce qui revient à dire que Cov(g(WT ), g(−WT )) < 0,
on peut obtenir une meilleure précision en simulant deux fois moins d’accroissements
du brownien. En effet, si N est le nombre de simulations par la méthode sans contrôle
antithétique, alors sous la condition précédente :
V ar[
(g(WT )+g(−WT ))
2
]
N/2
< V ar[g(WT )]
N](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-20-320.jpg)
![Chapitre 3. Variable antithétique 20
ce qui signifie que l’estimateur obtenu en simulant (g(WT )+g(−WT ))
2
avec N/2 trajectoires
est plus précis que celui qui consiste à simuler g(WT ) avec N trajectoires. D’après le cours
on a montré qu’il y a un gain de variance dès que WT −→ g(WT ) est monotone.
On applique cette méthode afin d’obtenir un nouvel estimateur de variance plus petite
que l’estimateur naïf.
3.2 Algorithme
Hypothèse : Soient deux browniens WT et −WT ayants la même espérance.
Méthode : On répète Nsim fois les étapes suivantes :
(a) Pour i = 1 . . . , N on génère Wi
T où : Wi
T → N(0R3,I3)
(b) On pose g(−Wi
T ) = 1L
−(i)
T >H
où −Wi
T est lantithétique de Wi
T
On définit Yi = g(Wi
T ) ; Yi = g(−Wi
T ) et Zi = Yi+Yi
2
(c) On définit l’estimateur antithétique ˆpAN = ZN = 1
N
N
i=1 Zi et la variance est
définit par ˆσ2
N = N
i=1(Zi − ˆpAN )2
(d) On définit l’intervalle de confiance par :
IC =] ˆpAN − qα/2
σ2
N√
N
; ˆpAN + qα/2
ˆσ2
N√
N
[
– ˆpAN = ZN = 1
N
N
i=1 Zi (Estimateur antithétique)
– ˆpMC = Y2N = 1
2N
2N
i=1 Yi (Estimateur Monte Carlo naïf)
Important : Il est important d’utiliser le même nombre de simulations pour
pouvoir comparer les méthodes.
Comparaison des variances :](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-21-320.jpg)
![Chapitre 3. Variable antithétique 21
V ar(ˆpMC) = V ar( 1
2N
2N
i=1 Yi) = V ar(Y )
2
V ar(ˆpAN ) = V ar(ˆpMC) + Cov(Y, ˜Y )
2N
Ainsi
V ar(ˆpAN ) < V ar(ˆpMC) ⇔ Cov(Y,˜Y ) < 0
Application numérique
Dans le tableau ci-dessous nous présentons les valeurs obtenues pour des seuils H diffé-
rents.
H N ˆp ˆσ2 Nsim IC
0 103
0.5667 0.029 103
0.0095 [0.556 ; 0.577]
0.2 103
0.14 0.0504 103
0.0507 [0.126 ; 0.154]
0.5 103
2.4*10−
4 1.2*10−
4 103
0.451 [3*10−
4; 4.6 ∗ 10 − 4]
0.75 103
1.8e-05 8e-06 103
5.27 [-1.68*10-4 ; 2*10−
4]
1 103
0 0 103
NaN –
Figure 3.1: Tableau des valeurs : Méthode de Variable antithétique avec un échantillon
de taille N
H N ˆp ˆσ2 Nsim IC
0 103
0.569 0.245 103
0.0276 [0.535 ; 0.597]
0.2 103
0.14 0.12 103
0.0784 [0.119 ; 0.161]
0.5 103
2.35*10-4 2.5*10−
4 103
0.451 [2.8*10−
4; 4.6 ∗ 10 − 4]
0.75 103
1.45e-05 1.45e-05 103
8.3 [-2.2*10-4 ; 2.5*10−
4]
1 103
0 0 103
NaN –
Figure 3.2: Tableau des valeurs : Méthode de Monte Carlo naïf avec un échantillon de
taille 2N](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-22-320.jpg)
![Chapitre 4
VARIABLE DE CONTRÔLE
4.1 Présentation générale de la méthode
4.2 Objectif :
calculer p = E [Y ] = E [f (X)] Cette technique consiste à ajouter une variable Z ayant
les caractéristiques suivantes :
– facilement simulable ;
– E [Z] connue ou facilement calculable (variance « petite »).
Deux calculs possibles de p :
– par méthode de Monte Carlo standard,
– en posant Wc = Y + c (Z − E [Z]) et en calculant E [Wc] par Monte Carlo
(c : paramètre constant fixé).
Question : Pour que le nouvel estimateur soit meilleur, il faut que sa variance
soit plus petite que celle de l’estimateur naïf. Alors la question qui se pose est :
A-t-on : V ar [Wc] < V ar [Y ] ?](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-24-320.jpg)
![Chapitre 4. Variable de contrôle 24
Calcul de la variance :
V ar [Wc] = V ar [Y ] + c2
× V ar [Z] + 2c × Cov (Y, Z) .
Choix optimal de c :
D’après le cours on a pu constaté que la valeur optimale est c∗
= −Cov(Y,Z)
V ar(Z)
or
V ar [Wc∗ ] = V ar [Y ] − Cov(Y,Z)2
V ar(Z)
par la suite on a que
V ar [Wc∗ ] < V ar [Y ] ⇔ Cov(Y, Z) < 0. Z est appelée variable de contrôle de Y .
Méthode :
ˆθN,c∗ = 1
N
N
i=1 (Yi + c∗
(Zi − E [Z])) ≈ θ
Problème :
Comment calculer E [Z] ainsi que Cov(Y, Z) ?
4.3 Algorithme :
Étape 1 :
– Simuler p v.a. (Yn)1≤n≤p et p v.a.(Zn)1≤n≤p.
– Poser :
ˆE [Z] = 1
p
p
i=1 Zi ; ˆE [Y ] = 1
p
p
i=1 Yi
V ar [Z] = 1
p
p
j=1 Zj − ˆE [Z]
2
Cov (Y, Z) = 1
p
p
j=1 Yj − ˆE [Y ] Zj − ˆE [Z]
– Calculer ˆc∗ = −Cov(Y,Z)
V ar(Z)](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-25-320.jpg)
![Chapitre 4. Variable de contrôle 25
Étape 2 :
Pour N grand
– Simuler N v.a. (Yn)1≤n≤N et N v.a.(Zn)1≤n≤N .
– Poser :
ˆθ =
1
N
N
i=1
Yi + ˆc∗ Zi − ˆE [Z] ≈ θ
4.4 Application numérique
Comme vue précédemment, on a :
S1
T = S1
0 exp µ1 −
σ2
1
2
T + σ1
√
T
√
ρ1,1Z1
S2
T = S2
0 exp µ2 −
σ2
2
2
T + σ2
√
T ρ2,1
√
ρ1,1
Z1 + ρ2,2 −
ρ2
2,1
ρ1,1
Z2
S3
T = S3
0 exp µ3 −
σ2
3
2
T + σ3
√
T ρ3,1
√
ρ1,1
Z1 + ρ2,3−ρ1,2ρ1,3
√
ρ1,1ρ3,2−ρ2
1,2ρ1,1
Z2 + ρ3,3 −
ρ2
1,3
ρ1,1
− (ρ2,3−ρ1,2ρ1,3)2
ρ1,1ρ1,3−ρ2
1,3ρ1,1
Z3
avec Zk ℵ(0, 1) ; k = 1, 2, 3.
D’autre part on a :
L = V0 − VT = (−S1
0 − S1
0 − S1
0) + (S1
T + S1
T + S1
T ) d’où
E[L] = −(S1
0 + S1
0 + S1
0) + (E[S1
T ] + E[S2
T ] + E[S3
T ])
En remplaçant les coefficients avec leurs valeurs on aura :
S1
T = exp 8.10−3
+
√
4.10−3Z1
S2
T = exp 8.10−3
+
√
4.10−3(0, 5Z1 +
√
3
2
Z2
S3
T = exp 8.10−3
+
√
4.10−3(0, 5Z1 + 1
2
√
3
Z2 + 2
3
Z3
d’où :
Y 1
= log(S1
T ) ℵ(8.10−3
, 4.10−3
)
Y 2
= log(S2
T ) ℵ(8.10−3
, 4.10−3
(0, 52
+ 3
4
)
Y 3
= log(S3
T ) ℵ(8.10−3
, 4.10−3
(0, 52
+ 1
12
+ 2
3
)](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-26-320.jpg)
![Chapitre 4. Variable de contrôle 26
Remarque
En théorie des probabilités et statistique, une variable aléatoire X est dite suivre une
loi log-normale de paramètres µ et σ2
si la variable Y = ln(X) suit une loi normale
d’espérance µ et de variance σ2
.
Cette loi est parfois également appelée loi de Galton. Elle est habituellement notée
log −ℵ(µ, σ2
) dans le cas d’une seule variable ou log −ℵ(µ, Σ) dans un contexte mul-
tidimensionnel.
L’espérance est
E[X] = exp µ +
σ2
2
et la variance est
V ar[X] = exp σ2
− 1 exp 2µ + σ2
Un vecteur aléatoire X est dit suivre une loi log-normale multidimensionnelle de para-
mètres µ ∈ RN
et Σ ∈ MN (R) si le vecteur Y = ln(X) (composante par composante) suit
une loi normale multidimensionnelle dont le vecteur des espérances est µ et la matrice
de covariance est Σ. Cette loi est habituellement notée log −N(µ, Σ).
Les espérances et covariances sont données par les relations (valables également dans le
cas dégénéré) :
E [[X]i] = exp µi +
1
2
Σii](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-27-320.jpg)
![Chapitre 4. Variable de contrôle 27
D’après la remarque précédente on a que :
E [S1
T ] = exp {10−2
} E [S2
T ] = exp {12.10−3
}
E [S3
T ] = exp {12.10−3
} E [S1
0] = E [S2
0] = E [S3
0] = S1
0 = 1
E [L] = −3 + exp {10−2
} + 2 exp {12.10−3
}
H N ˆp ˆσ2 Nsim IC
0 103
0.566 0.243 103
0.0271 [0.537 ; 0.595]
0.2 103
0.14 0.11 103
0.078 [0.12 ; 0.158]
0.5 103
2.35*10-4 2.3*10−
4 103
0.422 [2.75*10−
4; 4.43 ∗ 10 − 4]
1 103
0 0 103
NaN –
Figure 4.1: Tableau des valeurs : Méthode de Variable de contrôle
4.5 Conclusion
On remarque que pour notre cas la méthode de variable de contrôle semble être inefficace.
La réduction de variance par rapport à la méthode Monte Carlo naïve est très faible.
Cela peut être fortement lié au choix de la variable de contrôle. D’autre part le problème
lié au grande valeur du seuil persiste toujours ce qui nous amène à l’étape suivante qui
est la méthode de stratification.](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-28-320.jpg)
![Chapitre 5
STRATIFICATION
5.1 Présentation générale du problème
Objectif :
évaluer p = E[Y ] avec Y v.a.
Méthode
On procède à une stratification en fonction d’une variable aléatoire X où
P(Xi ∈ ∪iAi) = 1.
Soit N la taille de l’échantillon. On procède alors aux étapes suivantes :
– Choisir les Ai avec pi = P(X ∈ Ai)
– On pose ni = Npi (Considéré comme entier)
– Pour i = 1, . . . , K, simuler Yij, j = 1, . . . , ni i.i.d suivant la loi de Y |X ∈ Ai
On a alors
p ≈ ˆp = K
i=1 pi( 1
ni
ni
j=1 Yij)
Notation :
θi = E[Yij] = E[Y |X ∈ Ai], σ2
i = V ar[Yij] = V ar[Y |X ∈ Ai]
Montrons que cet estimateur est sans biais et calculons sa variance.](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-29-320.jpg)
![Chapitre 5. Stratification 29
E[ˆp] = K
i=1 pi( 1
ni
ni
j=1 E[Yij]) = N
i=1 piθi = p (sans biais)
de variance
V ar(ˆp) = K
i=1 p2
i V ar( 1
ni
ni
j=1 E[Yij]) = N
i=1 p2
i
σ2
i
ni
5.2 Application à notre problématique
But : Estimer p = E[g(U1, U2, U3)] où Ui → U[0, 1] ∀i = 1, 2, 3
Méthode : On va stratifier avec Y = 3
i=1 Ui
On pose T = −log( 3
i=1 Ui) = 3
i=1(−log(Ui))
Remarque : −log(Ui) → Exp(Λ = 1) ⇒ T → Gamma(3, 1)
On pose T= temps d’arrivé du 3éme
client.
−log(U1) = Temps d’arrivé du 1er client.
−log(U2) = Temps qui sépare l’arrivé du 1er
client et du 2ème
client.
−log(U3) = Temps qui sépare l’arrivé du 2ème
client et du 3ème
client.
Figure 5.1: Temps d’arrivée
On pose G = fonction de répartition d’une v.a de loi Gamma(3,1). On a alors T =
G−1
(U[0, 1]) . On partitionne l’intervalle [0, 1] en n intervalles :
[0, 1] = n
k=1[(0+k−1)
n
, 1+k−1
n
] = n
k=1 Ak.
Rappelons que Ak = [(0+k−1)
n
, 1+k−1
n
]. Pour tirer un nombre x appartenant à Ak, on tire
V → U[0, 1] et on pose x = (k−1+V )
n
. Notre formule sera donc :](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-30-320.jpg)
![Chapitre 5. Stratification 30
p = E[g(U1, U2, U3)] = 1
n
n
k=1 E[g(U1, U2, U3)|G−1( k−1
n
)≤T≤G−1( k
n
)]
On doit estimer : p=E[g(U1, U2, U3)|G−1( k−1
n
)≤T≤G−1( k
n
)]
5.3 Algorithme
But :
Estimer p où :
p = E[g(U1, U2, U3)]
p = n
k=1 E[g(U1, U2, U3)|G−1( k−1
n
)≤T≤G−1( k
n
)] P(G−1
(k−1
n
) ≤ T ≤ G−1
(k
n
))
p = 1/n n
k=1 E[g(U1, U2, U3)|G−1( k−1
n
)≤T≤G−1( k
n
)]
pour chaque simulation j = 1, . . . , Nsim on répète les étapes suivantes :
pour k = 1, . . . , N (où N est la taille de notre échantillon)
(a) On simule V k
→ U[0, 1] et on pose Tk
= G−1
(V k+k−1
N
)
(b) On simule V k
(1) et V k
(2) → U[0, 1] et on ordonne V k
(1) et V k
(2)
(c) On calcule Uk
1 , Uk
2 et Uk
3 telles que :
i. Uk
1 = exp[−Tk
(V k
(1) − V k
(0))] avec V k
(0) = 0
ii. Uk
2 = exp[−Tk
(V k
(2) − V k
(1))]
iii. Uk
3 = exp[−Tk
(V k
(3) − V k
(2))] avec V k
(3) = 1
(d) Soit φ−1
: le quantile d’une loi normale centrée réduite. On calcule :
i. Z1 = φ−1
(Uk
1 )
ii. Z2 = φ−1
(Uk
2 )
iii. Z3 = φ−1
(Uk
3 )
(e) On calcul les prix des actifs tels que :
i. S1,i
T = exp 8.10−3
+ 0, 2
√
0, 1Z
(i)
1](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-31-320.jpg)
![Chapitre 5. Stratification 31
ii. S2,i
T = exp 8.10−3
+
√
4.10−3(0, 5Z
(i)
1 +
√
3
2
Z
(i)
2
iii. S3,i
T = exp 8.10−3
+
√
4.10−3(0, 5Z
(i)
1 + 1
2
√
3
Z
(i)
2 + 2
3
Z
(i)
3
(f) On calcule la perte relative à notre stratégie :
Lk
T = V0 − V k
T où V0 = −3Sk
0 = −3 et V k
T = − 3
k=1 Sk
T
(g) On pose g(Uk
1 , Uk
2 , Uk
3 ) = 1Lk
T >H
(h) On note un estimateur relatif à la jème
simulation ˆp
(j)
Strat = 1
N
N
k=1 g(Uk
1 , Uk
2 , Uk
3 )
(i) D’autre part ˆσ
2(j)
Strat = 1
N
N
k=1(g(Uk
1 , Uk
2 , Uk
3 ) − ˆp
(j)
Strat)2
A la fin des Nsim simulations on obtient notre estimateur et que sa variance associée :
ˆpStrat = 1
Nsim
Nsim
j=1 ˆp
(j)
Strat
ˆσ2
Strat = 1
Nsim
Nsim
j=1 ˆσ
2(j)
Strat
Après différentes simulations on obtient le tableau suivant pour différentes valeurs du
seuil H :
5.4 Application numérique
H N ˆp ˆσ2 Nsim IC
0 103
0.568 2.45*10−
5 103
8.75*10−
5 [0.565 ; 0.567]
0.2 103
0.1397*10−
4 1.2*10−
4 103
2.48*10-3 [0.1391 ; 0.1404]
0.5 103
2.33*10-3 2.32e-06 103
0.0207 [2.231*10−
3; 2.42 ∗ 10 − 3]
0.75 103
1.4e-05 1.4e-08 103
0.267 [-6.667e-06 ; 2.133e-05]
1 103
0 0 103
NaN –
Figure 5.2: Tableau des valeurs : Méthode de Stratification](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-32-320.jpg)

![Chapitre 6
FONCTION D’IMPORTANCE
C’est de loin la méthode la plus efficace. C’est une technique utilisée beaucoup pour
calculer
p = P(L ≥ H) = E(1L≥H)
surtout quand l’occurrence de X ≥ H est très petite.
Exemples :
– Catastrophes climatiques, ferroviaires, aériennes, etc.
– Faillites de grosses entreprises, d’états, etc.
– Cracks boursiers importants
6.1 Objectif
:
Mesurer les risques de portefeuille, opérationnels, etc. (obligation légale pour les banques
ou les assurances). En effet, on va procéder à un changement de mesure de manière à ce
que la proportion des valeurs simulées vérifiant L ≥ H devient proche de 0.5 au lieu de
zéro.
p = P(L ≥ H) = E[1L≥H] = E[g(z1, z2, z3)] où Zi ∼ N(0, 1) ∀i = 1, 2, 3.](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-34-320.jpg)
![Chapitre 6. Fonction d’importance 34
p = R3
g(x1, x2, x3) 3
i=1 f(xi)dx1dx2dx3 p = R3
g(x1, x2, x3)
3
i=1
f(xi)
3
i=1
f(xi,ηi)
3
i=1 k(xi, η)dx1dx2dx3
où : f(,) = densité d’une variable de loi N(0, 1)
où : k(xi, ηi) = densité d’un v.a de loi N(ηi, 1)
p = Eη[g(X)f(X,0)
k(X,η)
] où :
f(X, 0) = densité du vecteur gaussien de loi N(0R3 , I3)
k(X, η) = densité du vecteur gaussien de loi N(η, I3) avec X = (X1, X2, X3) et où :
(E(Xi) = ηi ; V ar(Xi) = 1 et η = (η1, η2, η3) ∀i = 1, 2, 3
p est estimé par : ˆp = 1
N
N
i=1 g(Xi)f(Xi,0)
k(Xi,η)
où X → N(η, I3)
Examinons la variance de l’estimateur ˆp.
V ar(ˆp) = 1
N
V arη[g(X)f(X,0)
k(X,η)
].
On veut minimiser la variance :
V arη[g(X)f(X,0)
k(X,η)
]
= R3
(g2
(x)f2(x,0)
f2(x,η)
)k(x, η)dx − p2
= R3
(g2
(x)f(x,0)
k(x,η)
)f(x, 0)dx − p2
= E0[g2
(X)f(X,0)
k(X,η)
] − p2
Il suffit donc de minimiser l’espérance E0 (par rapport au gaussien N(0R3 , I3)), soit
calculer :
minηE0[g2
(X)f(X,0)
k(X,η)
]
6.2 Algorithme
(a) On génère X1, . . . , XN → N(0R3 , I3)
(b) On calcule ˆpη = 1
N
N
i=1 g2
(Xi)f(Xi,0)
k(Xi,η)
.
On veut minimiser ˆpη. Soit ˆη le minimum.](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-35-320.jpg)
![Chapitre 6. Fonction d’importance 35
(c) On génère X1, . . . , XN → N(ˆη, I3)
(d) ˆp = 1
N
N
i=1 g(Xi)f(Xi,0)
k(Xi,η)
6.3 Conclusion
D’après les différentes recherches littéraires effectuées, il s’est avéré que la méthode d’im-
portance et la méthode la plus intéressante pour notre cas. La difficulté majeure dans la
mise en uvre de cette méthode est de trouver le changement de loi (i.e. la densité instru-
mentale) adéquate. Plusieurs méthodes telle que glasserman ou glarkin nous permettent
de résoudre notre problème.
On peut par exemple utiliser la formule de Cameron-Martin. On considère la famille de
lois P = {densités gaussiennes Nd(θ, Id), θ ∈ Rd
}, de sorte que
gθ(x) = 1
√
2π
d exp(−1
2
x − θ 2
)
Pour simplifier les notations, on écrit Eθ pour Egθ
et E pour E0.
D’après la (Formule de Cameron-Martin) on montre que pour tout θ ∈ Rd
E[φ(Z)] = E[φ(Z + θ)exp(−0.5θ θ − θ Z)] .
Par suite on pourra alors déduire une méthode de Monte Carlo par échantillonnage
d’importance pour calculer E[φ(Z)] : on calculera cet estimateur à partir d’un générateur
de nombre N(0, 1) et on lui associe un intervalle de confiance.
D’autre part on a φ = 1LT >H on a alors : E[φ2
(Z)|Z|exp(|Z||θ|)] < +∞.
De plus pour tout θ et la variance est égale à :
σ2
(θ) = E[φ2
(Z)exp( − θ Z + 0.5θ θ)] − (E[φ(Z)])2
Enfin pour déterminer θ on minimise σ2
(θ) et on montre que ce minimum (θ∗
) implique
l’égalité suivante : E[(θ∗
− Z)exp(−θ∗
Z)φ2
(Z)] = 0](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-36-320.jpg)
![BIBLIOGRAPHIE
[1] P. Glasserman, P. Heidelberger and R. Shahabuddin, Importance sampling and stra-
tification for value-at-risk, pp.7-24 in Computational Finance 1999 (Proceedings of the
sixth international conference on computational finance), Y.S. Abu-Mostafa, B. LeBaron,
A.W. Lo, and A.S. Weigened, eds., MIT Press, Cambridge, Mass, 2000.
[2] [1] P. Glasserman, P. Heidelberger and R. Shahabuddin, Variance reduction techniques
for estimating value-at-risk, Management Science 46 :1349-1364, 2000.
[3] [2] COURS MÉTHODE DE MONTE CARLO, Alexandre Popier Université du Maine,
Le Mans
[4] [3] Introduction aux Méthodes de Monte-Carlo, LAURE ELIE BERNARD LAPEYRE,
Septembre 2001
[5] [4] COURS Introduction aux méthodes de Monte Carlo et applications à la finance,
MAT5502 , Randal DOUC, Telecom Sud Paris.
[6] [5] COURS METHODES DE SIMULATION MONTE CARLO, Université Paris | Dau-
phine Tunis, responsable du cours à Paris : Xiaolu TAN, responsable du cours à Tunis :
Hichem RAMMEH
[7] [6] Séance de TP Monte Carlo Paris | Dauphine Tunis , responsable du TP : Khaled
BENNOUR.](https://image.slidesharecdn.com/f602d84c-d0df-425a-86b8-56eba57e005c-151230155746/85/Projet_Monte_Carlo_Dauphine-37-320.jpg)
























































