Télécharger pour lire hors ligne


![Sujet de stage
La recherche en architecture de processeur est confront´ee actuellement `a des contraintes qui
rendent de plus en plus difficile l’augmentation des performances des processeurs. Ces contraintes
sont multiples : consommation ´electrique, latence de propagation des signaux sur les connexions,
temps et coˆut de developpement, etc. . . Pour esp´erer trouver d’´eventuelles solutions permettant
d’augmenter les performances de mani`ere significative sur une large gamme d’applications, il faut
trouver de nouveaux paradigmes d’architecture. Pour cela, il faut d’abord avoir une bonne compr´e-hension
du comportement des programmes.
Le sujet propos´e a pour but d’´evaluer la quantit´e de travail r´eellement utile dans l’ex´ecution des
programmes. L’id´ee sous-jacente est que si une fraction importante de l’ex´ecution d’un programme
consiste en du travail inutile, il peut ˆetre int´eressant de chercher un paradigme architectural per-mettant
d’exploiter cette propri´et´e.
Le probl`eme consiste `a donner une d´efinition de l’utilit´e d’un travail. Par exemple, dans la
r´ef´erence [1], un r´esultat interm´ediaire est consid´er´e inutile s’il est ´ecrit dans un registre et est
´ecras´e sans avoir ´et´e utilis´e. Dans la r´ef´erence [5], un store `a une adresse m´emoire est consid´er´e
inutile s’il ´ecrit une valeur ´egale `a la valeur d´ej`a stock´ee `a cette adresse. Nous proposons d’´etudier
une autre d´efinition, selon laquelle une instruction dynamique est consid´er´ee utile si
– Elle produit un r´esultat ´emis en sortie du programme (ex. printf)
– Elle produit un r´esultat utilis´e comme op´erande d’une instruction utile
– C’est un branchement dominant une instruction utile
La partie recherche du stage consiste `a concevoir un algorithme efficace en temps et en m´emoire
permettant d’´evaluer la quantit´e d’instructions dynamiques utiles. La partie mise-en-oeuvre consiste
`a ´ecrire le programme correspondant, et `a l’utiliser pour obtenir des statistiques sur la fraction de
travail utile, et d’autres statistiques, `a d´efinir, permettant de mieux appr´ehender le comportement
des programmes. La mise en oeuvre se fera `a l’aide des outils d´evelopp´es au sein du projet CAPS.
On travaillera sur des traces d’ex´ecution des programmes de la suite SPEC CPU2000.
2](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-2-320.jpg)






![Chapitre 1
Bibliographie
1.1 Introduction
Aujourd’hui, pour am´eliorer les performances d’un programme, il ne suffit plus seulement d’ajou-ter
du mat´eriel dans un syst`eme donn´e. Il faut avant tout ´etudier le comportement de ce programme
afin d’adapter au mieux les ajouts qui doivent ˆetre faits au syst`eme. De ce constat, les architectes
des microprocesseurs ont tir´e des id´ees aujourd’hui fondamentales (tels les diff´erents niveaux de
m´emoires caches qui exploitent la propri´et´e de localit´e temporelle et spatiale d’acc`es aux donn´ees
dans les programmes).
En ce sens, certains travaux de recherche s’int´eressent aujourd’hui au probl`eme du travail ef-fectu
´e inutilement par un microprocesseur. Ils mettent en ´evidence une quantit´e non n´egligeable
de travail inutile. Dans cette bibliographie, trois approches principales de travail inutile ont ´et´e
retenues.
1. Une instruction produisant un r´esultat jamais utilis´e par une autre instruction est consid´er´ee
comme inutile (approche de « l’instruction morte » retenue par l’article [1]).
2. Une instruction d’´ecriture est consid´er´ee comme inutile si cette derni`ere ne modifie pas l’´etat
de la m´emoire (i.e. la mˆeme valeur est ´ecrite `a la mˆeme adresse m´emoire) (approche de
« l’´ecriture silencieuse » retenue dans de nombreux articles [5, 3, 7]).
3. Une instruction est consid´er´ee comme utile si elle produit un r´esultat en sortie (affichage d’un
r´esultat par exemple) ou qu’elle est elle mˆeme utile `a une instruction utile (approche retenue
pour le stage).
Apr`es un bref tour d’horizon des travaux d´ej`a effectu´es dans le domaine au niveau des compila-teurs,
chacun des trois aspects d´ecrits ci-dessus du travail inutile sera d´evelopp´e dans un paragraphe
de cette bibliographie. S’en suivra un paragraphe de discussion sur la possibilit´e de mˆeler ces deux
approches pour essayer d’obtenir une coop´eration compilation/ex´ecution dans l’´elimination des
instructions inutiles.
9](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-9-320.jpg)
![1.2 Compilation et travail inutile
1.2.1 Vous avez dit « instructions inutiles » ?
Il peut paraˆıtre surprenant au premier abord d’entendre parler de travail inutile dans un pro-gramme.
En effet, `a partir du moment ou le programmeur demande d’effectuer un travail `a la
machine, (encore que celui-ci ne soit pas infaillible. . .) ce travail doit avoir une utilit´e (au sens
informatique du terme bien entendu. . .). Cependant, au del`a du programmeur, il existe toute une
chaˆıne de m´ecanismes permettant de passer du langage de haut niveau (i.e. langage de program-mation
classique) au code machine ex´ecutable. Ainsi ce programme va passer par toute sortes de
transformations qui vont introduire du travail inutile. De plus, il est possible de trouver, dans la
fa¸con dont sont con¸cus les programmes, du travail inutile (redondance de calculs par exemple).
1.2.2 Instructions statiques inutiles
Pour commencer, il est important de rappeler ce que sont les instructions statiques et les ins-tructions
dynamiques. Une instruction statique est une instruction telle qu’on peut la trouver dans
le code source d’un programme. Une instruction dynamique est une instance d’instruction statique.
A chaque instruction statique peut correspondre plusieurs instructions dynamiques (autant que de
fois o`u l’on ex´ecute cette instruction statique).
Exemple simple :
pour i de 1 à n faire
t[i] := 0;
fpour
Instruction statique : t[i] := 0
Instructions dynamiques associées : t[1] := 0, t[2] := 0, …, t[n] := 0
Dans l’exemple suivant, il est important de noter que si n n’est pas fix´e lors de la compilation, la
seule connaissance du compilateur est l’instruction statique. Il ne pourra donc pas, `a priori se servir
de la valeur de n `a des fins d’optimisation. Supposons maintenant qu’un programme ne soit compos´e
que des instructions de l’exemple et n’affiche aucun r´esultat. Le compilateur peut en d´eduire que
l’ensemble du travail `a effectuer pour ex´ecuter cette boucle est inutile. Cependant, il suffit d’ajouter
une instruction qui utilise t[m] en lecture (m ´etant un param`etre d’entr´ee du programme inconnu
`a la compilation) pour que, potentiellement, l’ensemble du travail de la boucle devienne utile. En
effet, le compilateur ne sachant pas quelle case du tableau t va ˆetre acc´ed´e, il est oblig´e de consid´erer
que l’ensemble de la boucle fournit du travail utile.
Il existe de nombreuses autres mani`eres d’´eliminer du travail inutile lors de la compilation [2, 4]
que nous n’aborderons pas ici car seul l’aspect d´ecrit ci-dessus se rapproche des travaux vis´es dans
cette ´etude.
Dans la suite de cette bibliographie, nous ne nous int´eresserons qu’aux instructions inutiles
dynamiques (i.e. qui ne peuvent pas ˆetre d´etect´ees par le compilateur puisqu’elles d´ependent de
valeurs d’entr´ees du programme non connues au moment de la compilation).
10](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-10-320.jpg)
![1.3 Premi`ere approche :
Instructions inutiles d´etect´ees dynamiquement
1.3.1 Introduction
Les auteurs de l’article [1] se sont aper¸cus que le r´earrangement des instructions fait par les com-pilateurs
lors des phases d’optimisations cr´e´e des instructions inutiles. En effet, comme le montre
leurs r´esultats, une compilation faite sans optimisations montre un niveau faible d’instructions in-utiles
alors qu’une compilation avec un fort niveau d’optimisation montre un taux d’instructions
inutiles relativement ´elev´e (parfois sup´erieur `a 10 %). Cependant, malgr´e ce travail effectu´e inuti-lement,
il est bon de rappeler que globalement, le temps d’ex´ecution de ces programmes diminue
(i.e. on a bien l’effet d´esir´e). La question qui vient alors est :
« Comment conserver ces optimisations tout en r´eduisant le travail inutile qui leur est associ´e ? »
1.3.2 Description du principe de d´etection et d’´elimination des instructions
inutiles
Dans un premier temps, l’important est d’analyser les instructions ex´ecut´ees inutilement afin
de savoir comment les d´etecter. Les auteurs de l’article [1] se sont ainsi aper¸cus que les instructions
dynamiques inutiles ´etaient tr`es souvent des instances d’un nombre r´eduit d’instructions statiques.
Ces instructions statiques sont appel´ees des instructions partiellement inutiles. En marquant ces
instructions particuli`eres comme ´etant propices `a g´en´erer des instructions dynamiques inutiles,
il est possible de ne faire un traitement particulier que sur ces derni`eres afin de savoir si une
instance pr´ecise sera r´eellement inutile. Lors de l’ex´ecution, pour chaque instance d’une instruction
partiellement inutile, une estimation de l’utilit´e de cette instruction dynamique sera faite. De cette
estimation d´ecoulera son ex´ecution ou non. Dans le cas d’une mauvaise pr´ediction, un m´ecanisme
de r´ecup´eration permet de lancer l’ex´ecution de cette instruction au moment ou l’on apprend que
la pr´ediction est ´erron´ee.
1.3.3 Id´ees d’impl´ementation
Les auteurs de l’article [1] ont donn´e quelques id´ees d’impl´ementation qui pourraient ˆetre mises
en oeuvre pour la d´etection de ce type d’instructions. La plus simple consiste `a m´emoriser dans un
cache totalement associatif les instructions statiques ayant d´ej`a g´en´er´e des r´esultats inutiles par le
pass´e. Du fait qu’un faible nombre de ces instructions g´en`erent un grand nombre des instructions
dynamiques inutiles, ce cache permettra de « suspecter » la prochaine instance d’une instruction
statique ayant d´ej`a g´en´er´e des r´esultats inutiles.
Par la suite, lors de la d´etection d’une instruction dynamique « suspect´ee » d’ˆetre inutile, son
ex´ecution sera suspendue jusqu’au « verdict » final permettant de savoir si il ´etait juste de la sus-pecter.
Si tel est le cas, cette instruction ne sera pas ex´ecut´ee, dans le cas contraire, cette instruction
sera ex´ecut´ee ajoutant ainsi un surcoˆut dˆu au retard d’ex´ecution pris par cette instruction. Il est
11](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-11-320.jpg)
![donc tr`es important d’avoir une estimation la plus fine possible afin d’´eviter ce genre de cas et afin
d’augmenter le nombre d’instruction inutiles suspect´ees `a juste titre. Pour cela, des optimisations
sont propos´ees : utilisation de l’information de flot de contrˆole et ajout d’un compteur deux bits `a
saturation principalement.
Il est important de noter que ces impl´ementations ne tiennent pas compte des r´esultats calcul´es
qui ne servent qu’`a des instructions inutiles. Autrement dit, cette impl´ementation ne prend pas en
compte le caract`ere transitif que peuvent avoir certaines instructions inutiles.
Instruction
produisant un résultat R
Instruction
utilisant R et produisant R’
Instruction
utilisant R’ et produisant R’’
Si R’’ est un résultat inutile R’ et R auront été produits inutilement
Fig. 1.1 – Mise en ´evidence de l’inutilit´e des instructions ne produisant des r´esultats utilis´es que
par des instructions inutiles
1.3.4 Conclusion sur cette approche
En conclusion, nous pouvons dire que les auteurs de l’article [1] ont mis en ´evidence une quantit´e
non n´egligeable de travail inutile mˆeme si elle reste, aujourd’hui, difficile `a exploiter. En effet, dans
un environnement o`u les ressources sont peu limit´ees, l’efficacit´e de l’impl´ementation d´ecrite ci-dessus
offre des gains en performance n´egligeables. En revanche, dans des conditions de ressources
plus limit´ees, les gains peuvent atteindre 10 % d’am´elioration des performances. De plus le fait
d’ex´ecuter moins d’instructions permet une diminution de la charge des Unit´es Arithm´etiques et
Logiques (UAL) et de la consommation ´electrique relativement importante. D’apr`es les auteurs, un
m´ecanisme mat´eriel diminuant l’impact des instructions inutiles sur la performance et la consom-mation
´electrique permettrait d’appliquer des optimisations de code plus pouss´ees `a la compilation.
12](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-12-320.jpg)
![1.4 Deuxi`eme approche :
´Ecritures silencieuses
1.4.1 Introduction
D’apr`es les auteurs de l’article [5], il existe principalement deux types d’´ecritures silencieuses.
D’une part les mises `a jours de valeurs silencieuses (qui ne changent pas l’´etat de la m´emoire dans
laquelle elles ´ecrivent) et d’autre part les ´ecritures silencieuses stochastiques qui mettent `a jour la
m´emoire de mani`ere pr´evisible. Dans la suite de ce chapitre, nous nous concentrerons sur les mises
`a jour de valeurs silencieuses et parlerons, par abus de langage, d’´ecritures silencieuses pour les
d´esigner.
1.4.2 Le ph´enom`ene d’´ecriture silencieuse
Au vu de la d´efinition de ce qu’est une ´ecriture silencieuse, il parait difficile de croire que ces
instructions puissent avoir un impact n´egatif important sur les performances d’un programme.
Pourtant, les articles sur le sujet montrent que souvent plus de 30 % des ´ecritures sont silencieuses
dans les applications test´ees. En effet, il existe de nombreux cas o`u, lors du parcours des ´el´ements
d’un tableau, les modifications apport´ees par ce parcours ne concernent qu’un petit nombre des
´el´ements de ce tableau.
Exemples simples :
pour i de 1 à n faire
b := (b & t[i]);
fpour
pour i de 1 à n faire
t[i] := (t[i] & b);
fpour
(a) (b) (c)
t étant un tableau de booléens
b étant un booléen
l'opération & étant un "ET" logique
pour i de 1 à n faire
t[i] := t[i] + e(i);
fpour
t étant un tableau d'entiers
e étant une fonction
Dans l’exemple (a), nous pouvons voir que pour chaque case du tableau t dont le bool´een est `a
vrai, l’ex´ecution du corps de la boucle ne produit aucun travail utile (la mˆeme valeur sera r´e-´ecrite
dans b). Dans l’exemple (b), le simple fait que b soit ´egal `a vrai entraˆıne une inutilit´e de l’ensemble
de la boucle. Dans l’exemple (c), lorsque "(i) renvoi z´ero, le corps de la boucle peut-ˆetre consid´er´e
comme inutile. Un autre cas assez fr´equent de travail inutile est celui o`u un tableau est initialis´e
apr`es avoir ´et´e utilis´e une premi`ere fois. Si lors de la premi`ere utilisation de ce tableau, toutes ses
valeurs n’ont pas ´et´e modifi´ees, il est inutile de r´e-initialiser l’ensemble des cases de ce tableau.
Il existe d’autres situations dans lesquelles un grand nombre d’´ecritures silencieuses peuvent ˆetre
observ´ees : lors de l’appel d’un sous-programme, si les registres sauvegard´es n’ont pas ´et´e utilis´es
dans ce sous-programme, leur restauration sera inutile. Ce mˆeme ph´enom`ene peut-ˆetre observ´e lors
de la sauvegarde/restauration de contexte d’un processus par un syst`eme d’exploitation.
13](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-13-320.jpg)
![1.4.3 Les cons´equences de l’´elimination des ´ecritures silencieuses
Au del`a du gain ´evident que provoquerait un m´ecanisme fiable de suppression des ´ecritures
silencieuses, un tel syst`eme permettrait ´egalement de supprimer une certaine quantit´e de travail
assez importante li´ee `a ces instructions. En premier lieu, les informations de contrˆole li´ees `a ces
instructions ne sont plus n´ecessaires (Ex : si une s´erie d’´ecritures silencieuses se trouve dans une
boucle, il est inutile d’ex´ecuter la boucle). De plus, lors de l’ex´ecution d’une instruction de range-ment
en m´emoire, tout un m´ecanisme lourd de rapatriement de la ligne de cache concern´ee vers la
m´emoire est mis en place (´ecriture de la donn´ee dans le cache, marquage de la ligne de cache comme
´etant modifi´ee puis, lors du chargement de nouvelles donn´ees dans cette ligne de cache, ´ecriture
de l’ancienne ligne de cache consid´er´ee comme modifi´ee en m´emoire). De fait, la suppression d’une
´ecriture ´evite d’avoir `a passer par toute ces op´erations d’acc`es `a la m´emoire tr`es coˆuteuses. Comme
expliqu´e dans l’article [3], cette remarque prend encore plus d’importance dans un syst`eme multi-processeur
puisque `a chaque ´ecriture m´emoire est associ´e un message d’invalidation `a destination
des autres processeurs provoquant un d´efaut de cache lors du prochain acc`es `a ces donn´ees. . . Il
est ´egalement important de noter que si certaines ´ecritures ne sont pas effectu´ees, de fait, certaines
d´ependances de donn´ees n’existent plus. De cette fa¸con, le processeur n’est plus oblig´e d’attendre
que ces valeurs soient ´ecrites pour pouvoir les utiliser. Le rendement du pipeline du processeur est
alors am´elior´e.
1.4.4 Id´ees d’impl´ementation
Les auteurs de l’article [5] ont propos´e une impl´ementation basique permettant de supprimer
les ´ecritures silencieuses. Cette impl´ementation consiste `a remplacer toute les op´erations de ran-gement
en m´emoire par trois op´erations : Chargement de l’ancienne valeur pr´esente en m´emoire,
comparaison avec la valeur qui doit y ˆetre ´ecrite et enfin, dans le cas o`u ces deux valeurs ne seraient
pas ´egales, ´ecriture de la nouvelle valeur en m´emoire. Cette m´ethode est sˆure et permet de d´etecter
l’ensemble des ´ecritures silencieuses. De plus, les lectures pouvant ˆetre servies en parall`eles, il peut
ˆetre int´eressant de remplacer les ´ecritures par des lectures suivies de comparaisons. Cependant,
dans la mesure ou le nombre d’´ecritures silencieuses ne repr´esente pas la majorit´e des ´ecritures
m´emoire, les auteurs ont ajout´e une « impl´ementation parfaite » dans laquelle un m´ecanisme per-met
de savoir si une ´ecriture va ˆetre utile et, dans ce cas, n’effectuera que l’´ecriture en m´emoire
sans avoir `a comparer la nouvelle valeur `a la valeur pr´ec´edente.
D’autres id´ees d’impl´ementations apparaissent ´egalement dans l’article [5] comme par exemple
la possibilit´e que la ligne de cache ne soit pas marqu´ee comme modifi´ee lorsqu’elle re¸coit une ´ecriture
silencieuse ´evitant ainsi d’avoir `a propager l’´ecriture en m´emoire centrale (avantage principal de
l’´elimination des ´ecriture silencieuses).
L’impl´ementation retenue pour les simulations faites par les auteurs de [5] est la premi`ere
propos´ee avec pour caract´eristique suppl´ementaire que seules les ´ecritures mises en attente vont
subir une v´erification de leur utilit´e. Ce qui veut dire qu’une ´ecriture survenant `a un moment o`u au
moins un port d’´ecriture de la m´emoire est disponible sera servie avant que la v´erification de son
utilit´e n’ai pu ˆetre faite. De cette fa¸con, les performances des ´ecritures ne sont jamais d´egrad´ees
puisque le m´ecanisme n’agit que sur la file d’attente des ´ecritures afin de la r´eduire.
14](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-14-320.jpg)
![1.4.5 Conclusion sur cette approche
Les auteurs de l’article [5] ont mis en ´evidence une grande quantit´e de travail inutile `a travers les
´ecritures silencieuses. En effet, les proportions d’´ecritures silencieuses obtenues lors des tests sont
parfois tr`es importantes et laissent penser qu’elles pourraient avoir une influence tr`es importante
sur les performances, notamment dans les syst`emes dont la purge des lignes de cache en m´emoire est
un goulet d’´etranglement. Les auteurs mettent ´egalement en avant la r´eduction du trafic sur le bus
d’un syst`eme multiprocesseur `a m´emoire partag´ee qui est souvent un point critique dans ce type de
syst`emes (ce trafic limite le nombre de processeurs sur un mˆeme bus). D’autres travaux ´elargissant le
th`eme de l’´ecriture silencieuse ont ´egalement ´et´e pr´esent´es comme celui sur les ´ecritures silencieuses
temporaires [6] consid´erant que si une valeur en m´emoire est modifi´ee puis remise `a son ancienne
valeur et qu’aucune lecture ne soit intervenue sur la valeur transitoire, elle peut-ˆetre consid´er´ee
comme silencieuse. Ce mod`ele semble bien s’adapter aux cas d´ecrits ci-dessus de sauvegarde et
de restauration de contexte fr´equents (appel de sous-programmes, passage d’un processus `a un
autre. . .).
15](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-15-320.jpg)


![trouv´ees pour r´eduire cette quantit´e de travail inutile. Cependant, l’objet du stage reste celui-ci :
« Concevoir et ´ecrire un programme permettant de calculer la quantit´e de travail inutile dans un
programme particulier apr`es son ex´ecution » .
Dans ce sens, le travail `a effectuer en stage sera, dans un premier temps, de r´efl´echir `a la mani`ere
de d´etecter quelles sont les instructions qui ont ´et´e ex´ecut´ees inutilement lorsque l’ex´ecution d’un
programme sera termin´ee (algorithme de construction puis d’exploration du graphe de d´ependance
des instructions d´ecrit dans cette section). Ces r´esultats devront ensuite ˆetre mis en forme afin de
d´egager des statistiques sur la quantit´e de travail inutile (pourcentage d’instructions inutiles) et
sur la nature de ces instructions (de quel type d’instructions s’agit-il ?). Une fois cet algorithme
impl´ement´e, il sera int´eressant de le tester sur diff´erent type de programme afin de savoir quelle
est la quantit´e de travail r´eellement inutile (d’apr`es la d´efinition donn´ee en introduction de cette
section) dans ces programmes.
1.5.4 Conclusion sur cette approche
En conclusion nous pouvons dire que l’approche retenue pour le stage est une d´emarche scien-tifique
exp´erimentale permettant de savoir quelle est la proportion globale de travail inutile dans
un programme. Si les r´esultats r´ev`elent une grande quantit´e de travail inutile, de nombreuses
ouvertures paraissent possibles : D´etection de ces instructions grˆace `a des compilateurs « intel-ligents
», d´etection de ces instructions « au vol » (approche d´ej`a retenue par [1]), coop´eration
compilateur/mat´eriel ou encore ajout de nouvelles instructions afin de faciliter leur d´etection.
18](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-18-320.jpg)






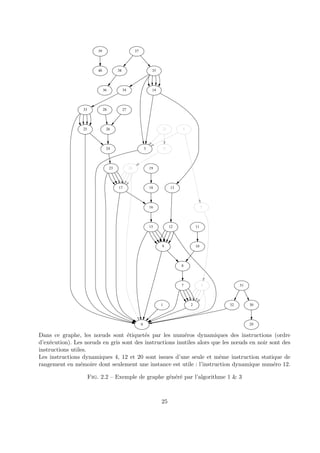

![de r´eduire notre graphe en supprimant les noeuds repr´esentant ce type d’instructions ainsi que leurs
arcs sortants.
Une mani`ere simple d’impl´ementer un tel m´ecanisme serait de consid´erer que chaque instruction
inutile est un objet et que les ressources (registres et zones m´emoire) sont des moyens d’acc´eder `a ces
objets. Si une instruction est accessible depuis au moins une ressource, alors il n’est pas possible
de supprimer les informations concernant cette instruction. En revanche, si aucune ressource ne
« r´ef´erence » l’objet, alors cet objet est inaccessible depuis les ressources et le restera jusqu’`a la fin
de l’ex´ecution du programme. Cet objet peut donc ˆetre supprim´e (noeud ainsi que ses arcs sortants).
Cette m´ethode s’apparente `a un syst`eme de ramasse-miettes comme il est souvent mis en place dans
un environnement d’ex´ecution pour lib´erer des zones m´emoires n’´etant plus r´ef´erenc´ees par aucun
pointeur.
2.2.3 Le r´esultat
La figure 2.3 page suivante est un exemple simple permettant de comprendre comment est
construit le graphe de d´ependance de donn´ee `a partir du code assembleur du programme dont on
veut ´evaluer la quantit´e de travail inutile.
Dans la figure 2.3 page suivante, les noeuds sources sont les instruction utiles par hypoth`ese (en
caract`ere gras). Ces instructions sont soit des instructions de sortie (print %valeur dans l’exemple)
soit des instructions de branchement (bne boucle dans l’exemple). Une fois ces instructions jug´ees
comme ´etant utile au programme, nous pouvons appliquer la d´efinition r´ecursive permettant de
trouver toutes les instructions ayant servi `a produire les valeurs utiles `a ces instructions. Ainsi,
dans notre exemple, l’instruction dynamique num´ero 18 (print %valeur) poss`ede comme entr´ee le
registre %valeur. Il est donc n´ecessaire de trouver la derni`ere instruction ayant ´ecrit dans ce registre.
Cette instruction est l’instruction dynamique num´ero 17 (load [@tab+2],%valeur). Ainsi de suite
r´ecursivement, l’instruction dynamique num´ero 17 poss`ede comme entr´ee la seconde case du tableau
rang´e `a l’adresse m´emoire @tab dont la derni`ere ´ecriture a ´et´e faite par l’instruction dynamique
num´ero 8 et ainsi de suite jusqu’`a n’arriver qu’`a des instructions n’ayant aucune entr´ee (copie
d’une constante dans un registre (mov 1,%indice dans l’exemple), instruction d’entr´ee au clavier
par l’utilisateur. . .).
De cette mani`ere, en parcourant le graphe, il est possible d’identifier le travail utile. Les ins-tructions
n’´etant accessible depuis aucune des sources (instructions de sorties ou de branchement)
sont identifi´ees comme ´etant du travail inutile (instructions dynamiques 2, 3, 12 et 13 dans notre
exemple).
Grˆace `a cet exemple, nous avons mis en ´evidence un cas simple comportant peu de travail inutile.
En revanche, il est facile de prendre conscience de l’importance que peut atteindre ce travail inutile
d`es lors que le traitement `a l’int´erieur d’une boucle du type de celle pr´esent´ee dans l’exemple devient
important. En effet, dans notre exemple, seule la multiplication par 10 et le rangement en m´emoire
sont inutiles mais si la valeur `a ranger dans le tableau avait ´et´e un calcul effectu´e par une fonction
comportant 10 000 instructions, les chiffres auraient ´et´e diff´erents. De mˆeme, si la taille du tableau
avait ´et´e de 10 000 cases dont seulement une aurait ´et´e utilis´ee, la quantit´e de travail inutile aurait
´et´e beaucoup plus importante. En revanche si, dans notre exemple, les trois cases du tableau avaient
27](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-27-320.jpg)
![1: mov 1,%indice
boucle:
2: mul %indice,10,%valeur
3: store %valeur,[%indice+@tab-1]
4: add %indice,1,%indice
5: cmp 4,%indice
6: bne boucle
7: load [@tab+2],%valeur
8: print %valeur
Code en assembleur RISC
(code statique)
Dépendances de données permettant d’identifier le travail
utile (arcs du graphe parcourus par l’algorithme).
Dépendance de donnée n’étant pas parcourues par
l'algorithme.
Trace d’exécution des instructions
(dynamique)
1ère itération de la boucle
2ème itération de la boucle
3ème itération de la boucle
Numéro
Dynamique
Numéro
Statique
123456789
10
11
12
13
14
15
16
17
18
123456234562345678
n Numéro d’instruction statique utile par essence
(instructions de sorties ou de branchement).
n Numéro d’instruction statique utile après parcours du
graphe de dépendance (définition récursive).
n Numéro d’instruction dynamique (indique l’ordre
d’éxécution des instructions dans le temps)
n
Numéro d’instruction statique jugés comme étant inutile
d’après la définition (instruction n’appartenant pas au
graphe de dépendance de données).
Compilation
Pour i de 1 à 3 faire
t[i] := i*10;
Finpour
Ecrire (t[2]);
Code source original
Fig. 2.3 – Du code source en langage de haut niveau au graphe de d´ependance de donn´ee dynamique
´et´e affich´ees (instruction print), la quantit´e de travail inutile aurait ´et´e nulle.
Un exemple plus complet montrant dans le d´etail comment l’algorithme a ´et´e impl´ement´e est
en annexe (figure 3.2 page 59).
28](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-28-320.jpg)

![mov r1,r2
add r2,3,r2
store r2,[a0]
Code source
mov r1,r2
mov r2,tmp
call fct
add r2,3,r2
mov r2,tmp
call fct
store r2,[a0]
load [a0],tmp
call fct
Code source
instrumenté
instrumentation
Fig. 2.4 – Instrumentation de code source en assembleur
Note
Dans l’exemple de la figure 2.4, les instructions sont instrument´ees apr`es leur ex´ecution, ce
qui n’est pas le cas dans notre impl´ementation : l’instrumentation se trouve avant l’ex´ecution de
l’instruction pour des raisons de suivi des branchements (pour pouvoir instrumenter correctement
les branchements, il est n´ecessaire de placer le code d’instrumentation avant ceux-ci).
L’instrumentation dans notre programme
L’instrumentation, dans le cas g´en´eral, permet d’ins´erer des instructions dans un programme. A
partir de ce concept simple, nous avons d´ecid´e d’utiliser l’instrumentation pour ins´erer des appels
de fonctions (´ecrites en C et compil´ees par ailleurs). De fait, les appels de fonctions en assembleur
ne faisant pas de sauvegarde des registres globaux (accessible de n’importe o`u dans le programme).
Il nous a fallu ajouter `a cette instrumentation une sauvegarde de contexte avant l’appel `a cette
fonction puis une restauration apr`es (figure 2.5 page suivante). Mais ce n’est pas tout : Chaque
instruction assembleur ayant un nombre variable d’op´erandes et de r´esultats, il nous a fallu ajouter
une instruction d’appel `a une fonction pour chaque op´erande et pour chaque r´esultat. De plus,
chaque acc`es `a la m´emoire n´ecessitant la r´ecup´eration de l’adresse de cet acc`es, il nous a fallu
r´ecup´erer des informations sur la valeur des registres utilis´es par l’instruction `a instrumenter afin
de savoir quelle ´etait l’adresse de cet acc`es m´emoire.
L’instrumentation d’une instruction dans notre programme d’´evaluation de la quantit´e de travail
inutile peut-ˆetre r´esum´ee en sept phases :
– Sauvegarde : Une phase de sauvegarde du contexte (registres globaux, d´ecalage de la fenˆetre
de registres. . .).
– D´ebut : Une phase de cr´eation de la structure de donn´ee repr´esentant une instruction (fi-gure
2.1 page 24).
– Op´erandes : Une phase permettant de cr´eer les arcs vers les instructions ayant ´ecrit en
dernier dans les ressources op´erandes de l’instruction.
30](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-30-320.jpg)








![ex´ecutions qui ne sont alors plus ´equivalentes. Ceci se produit en raison d’un mauvais jugement
port´e sur l’instruction add. En effet, celle-ci est utile au bon d´eroulement du programme alors
qu’elle a ´et´e jug´ee comme ne l’´etant pas par le programme de d´etection du travail inutile. Grˆace `a
ce syst`eme, il est facile de corriger les incorrections et impr´ecisions que comporte le programme de
d´etection du travail inutile. Par processus incr´emental, il est alors possible de corriger ces erreurs
une `a une jusqu’`a l’obtention d’un programme qui ne juge inutile que du travail r´eellement inutile
(Ce qui ne prouve pas pour autant qu’il d´etecte tout le travail inutile que peut comporter un
programme).
La M´ethode
Pour pouvoir mettre au point ce deuxi`eme programme, il faut tout d’abord que le programme
d’´evaluation de la quantit´e de travail inutile laisse une trace des instructions inutiles dans un
fichier qui sera utilis´e par le programme de v´erification. Pour la mise au point de ce programme de
v´erification, Salto a, l`a encore, ´et´e sollicit´e afin d’instrumenter chaque instruction. Lorsque cette
instruction est jug´ee inutile (d’apr`es la trace de la premi`ere ex´ecution) alors cette instruction est
saut´ee au moyen d’un jump d’une valeur constante puisque, dans les processeurs Sparc, toutes les
instructions ont une taille de quatre octets (« merci » les jeux d’instructions RISC). De cette fa¸con,
il est assez facile de « sauter » une instruction lorsqu’elle apparaˆıt dans la trace des instructions
inutiles.
Conclusion
Ce programme `a permis, sur des exemples simples, de v´erifier que la quantit´e de travail inutile
´evalu´ee ´etait bien du travail inutile quelque soit le niveau d’optimisation utilis´e et les cas de figure
rencontr´es. Cependant, par manque de temps, nous n’avons r´eussi `a le faire fonctionner que sur gzip
compil´e avec un niveau d’optimisation de 0. N´eanmoins, cette v´erification nous `a permis d’accroˆıtre
la confiance en nos r´esultats (figures 2.7 page 37 et 2.9 page suivante).
2.4.3 La r´epartition du travail inutile
Une fois les informations sur le travail inutile lors de l’ex´ecution d’un programme r´ecup´er´ees,
il est n´ecessaire de les organiser afin de pouvoir analyser d’ou provient ce travail inutile. Dans
un premier temps, nous avons essay´e de voir `a quelles instructions statiques correspondaient nos
instructions dynamiques inutiles. Nous avons trouv´e, sans surprise ´etant donn´e les r´esultats de
l’article [1], que seul un petit nombre d’instructions statiques ´etaient concern´ees. Ce qui signifie
que la plupart des instructions dynamiques inutiles sont concentr´ees sur un nombre d’instructions
statiques r´eduit (de l’ordre de 12.4 % des instructions statiques totales g´en`erent au moins une
instance dynamique inutile). Une fois ces instructions statiques en assembleur identifi´ees, nous
avons cherch´e `a « remonter », lorsque c’´etait possible, au code source en C correspondant afin
de mieux comprendre la raison pour laquelle ce travail est jug´e comme ´etant inutile par notre
d´efinition.
39](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-39-320.jpg)

![ˆetre r´eellement inh´erent `a l’algorithme et non du `a une mauvaise impl´ementation de celui-ci.
Exemple simple :
Dans la fonction local void gen codes (tree, max code), on observe que le code source
suivant est inutile la plupart du temps (lors de l’ex´ecution sur un fichier de test) :
for (bits = 1; bits <= MAX_BITS; bits++) {
next_code[bits] = code = (code + bl_count[bits-1]) << 1;
}
L’affectation dans le tableau next code est inutile 52 fois sur 60 dans l’exemple test´e (le nombre
d’it´erations de la boucle est MAX BITS et est ´egal `a 60). Le fait que cette affectation soit inutile un
certain nombre de fois engendre qu’une partie des calculs fait dans la boucle devient inutile. Ce
qui nous donne, pour l’ensemble de la boucle, un nombre de 824 instructions inutiles pour 1440 au
total (soit une proportion de 57 %).
Etant donn´e ces r´esultats, il est int´eressant de se pencher sur le cas de l’initialisation des
structures de donn´ees en g´en´eral. En effet, le premier r´eflexe d’un programmeur, lorsqu’il d´eclare
une structure de donn´ee (tableau, liste. . .) est de l’initialiser pour ´eviter, par la suite, d’y faire
un acc`es en lecture sans y avoir pr´ealablement rang´e une valeur. Or ce r´eflexe de programmation
est probablement ce que nous observons ici ´etant donn´e que les structures de donn´ees de gzip
n’´echappent apparemment pas `a cette r`egle.
Le coeur de l’algorithme Au coeur de l’algorithme, nous observons diff´erents cas d’instructions
dynamiques inutiles. Parfois, nous observons que le travail inutile est du `a l’initialisation de va-riables
locales dont le contenu est, la plupart du temps, r´e-´ecrit avant d’ˆetre lu. Parfois, il s’agit de
param`etres pass´es `a une fonction et qui ne servent que dans certaines conditions. Et enfin, un cas
assez fr´equent ´egalement est celui des variables globales qui sont maintenues `a jour de fa¸con inutile.
En effet, si une telle variable refl`ete une valeur lors du dernier passage dans une certaine fonction,
il est possible que cette fonction soit appel´ee plusieurs fois sans que cette valeur n’ai ´et´e lue entre
temps.
Exemples :
L’affectation prev match = match start ; peut-ˆetre inutile car la seule utilisation de la variable
prev match en lecture est le cas suivant :
if (prev_length >= MIN_MATCH && match_length <= prev_length) {
check_match(strstart-1, prev_match, prev_length);
flush = ct_tally(strstart-1-prev_match, prev_length - MIN_MATCH);
...
}
41](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-41-320.jpg)
![Ce qui signifie que lorsque la condition ci-dessus sera fausse, l’affectation de la variable prev match
sera inutile (c’est le cas 78 fois 82 dans notre test). En supposant que le calcul de la valeur de la
variable match start puisse ˆetre coˆuteux, et que cette variable ne soit pas r´e-utilis´ee en lecture
entre temps, on prend conscience de la port´ee que peut avoir le travail inutile.
Note
Dans l’exemple pr´ec´edent, il est int´eressant de noter que le d´eplacement de l’instruction d’affec-tation
prev match = match start ; dans le corps de la conditionnelle aurait suffit `a ´eliminer
ce travail inutile (dans la mesure o`u on ne fait pas d’´ecriture dans match start entre temps).
En effet, la variable prev match n’´etant utilis´ee que dans ce bloc, il est inutile de faire cette
affectation si la condition n’est pas vraie.
Une macro un peu particuli`ere a ´egalement retenu notre attention. Elle se trouve au coeur de
l’algorithme de compression, dans la fonction deflate(). Il s’agit de la macro INSERT STRING qui
ins`ere une chaˆıne de caract`ere dans la liste des chaˆınes de caract`eres qu’utilise gzip pour trouver
les chaˆınes les plus fr´equemment pr´esentes dans le fichier `a compresser.
Voici le code de cette macro apr`es passage du pr´e-processeur :
((ins_h = (((ins_h)<<((15+3-1)/3)) ^
( window[(strstart) + 3-1])) &
((unsigned)(1<<15)-1)),
prev[(strstart) & (0x8000-1)] = hash_head = (prev+0x8000)[ins_h],
(prev+0x8000)[ins_h] = (strstart));
Pour des raisons de lisibilit´e, nous avons r´e-´ecrit ce code :
ins_h = ( ins_h<<5 ^ window[strstart+2] & (unsigned)(1<<15)-1 );
hash_head = (prev+0x8000)[ins_h];
prev[strstart & (0x8000-1)] = hash_head;
(prev+0x8000)[ins_h] = strstart;
Dans cette macro, qui se trouve au coeur de l’algorithme de compression, les deux derni`eres
instructions (remplissage du tableau prev) se trouvent ˆetre tr`es souvent inutile (77 fois sur 82 dans
notre exemple). Ceci tend `a montrer que l’algorithme de compression utilis´e par gzip contient, par
nature, du travail inutile.
Travail inutile introduit par le compilateur. . .
. . . lors des phases d’optimisation de compilation On observe ´egalement que la version
compil´ee avec un niveau d’optimisation de 0 pr´esente une quantit´e globale de travail inutile moins
important (proportionnellement) `a la version compil´ee avec un niveau d’optimisation de 5. De plus,
42](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-42-320.jpg)
![l’´ecart entre les deux versions s’accentue dans le coeur de l’algorithme. En effet, durant la phase
d’initialisation, les deux versions se comportent `a peu pr`es de la mˆeme fa¸con (aux alentours de
50 % de travail inutile) alors que dans le coeur de l’ex´ecution, la version non optimis´ee comporte en
moyenne 6.9 % de travail inutile `a comparer aux 9.9 % observ´e dans le cas de la version optimis´ee.
Ce ph´enom`ene avait d´ej`a ´et´e constat´e dans l’article [1] mais uniquement au sujet des valeurs mortes.
. . . du au jeu d’instruction du processeur Cette ´etude n’est absolument pas exhaustive sur
les diverses causes que peut avoir le travail inutile. Cependant, mˆeme si cet aspect n’a pu ˆetre
explor´e pour des raisons de temps, il parait raisonnable de penser qu’une partie du travail inutile
pourrait avoir ´et´e introduit en raison des contraintes impos´ees par le jeu d’instructions utilis´e. En
effet, dans un jeu d’instruction RISC (comme le Sparc) une instruction de haut niveau (en langage
C par exemple) peut ˆetre convertie par le compilateur en une suite tr`es importante d’instructions
comme en une seule. Ceci d´epend de l’´eloignement de cette instruction en langage C par rapport aux
instructions disponibles dans le jeu d’instruction assembleur utilis´e. A contrario, un jeu d’instruction
CISC (comme le x86) aura des instructions assembleur plus proche des instructions en langage de
haut niveau. De cette fa¸con, les proportions d’instructions assembleur inutiles peuvent ne pas ˆetre
identiques aux proportions d’instructions inutiles de haut niveau (en langage C par exemple).
De plus, certaines optimisations de compilation effectuant un r´e-ordonnancement des instructions
assembleur, il est parfois difficile de savoir quel ensemble d’instructions assembleur repr´esente quelle
instruction de haut niveau.
Conclusion
En conclusion, nous pouvons dire que les proportions de travail inutile trouv´ees se rattachent
majoritairement au travail inutile pr´esent dans l’algorithme en langage de haut niveau. De fait, une
piste qui pourrait ˆetre int´eressante pour r´eduire ce travail inutile serait de signaler au programmeur,
lors des premi`eres ex´ecutions d’un prototype de programme, que certaines parties de l’algorithme
g´en`erent une grande quantit´e de travail inutile et que, par cons´equent, une r´e-´ecriture en prenant en
compte cet ´etat de fait pourrait ´eviter ce travail. Il est mˆeme possible d’imaginer un outil proposant
au programmeur une ´ebauche de solution pour l’aider `a restructurer une partie de son code afin
d’´eviter ce travail inutile. Cependant, ce type d’outils ne peut rien pour aider `a ´eliminer le travail
inutile intrins`eque `a l’algorithme.
43](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-43-320.jpg)

![Bibliographie
[1] G. Sohi A. Butt. Dynamic dead-instruction detection and elimination. ASPLOS X, October
2002.
[2] Jeffrey D. Ullman Alfred V. Aho, Ravi Sethi. Compilers : Principles, Techniques and Tools.
Addison-Wesley, 1986.
[3] Gordon B. Bell. Characterization of silent stores. Submitted in partial fulfillment of the M.S.
Degree in Electrical and Computer Engineering, May 2001.
[4] F. Bodin. Cours d’optimisation : Transformer pour la performance. Septembre 2002.
[5] M. Lipasti K. Lepak, G. Bell. Silent stores and store value locality. IEEE Transactions on
Computers, 50(11), November 2001.
[6] Mikko H. Lipasti Kevin M. Lepak. Temporally silent stores. ASPLOS X, October 2002.
[7] Kevin M. Lepak. Silent stores for free : Reducing the cost of store verification. Submitted in
partial fulfillment of the M.S. Degree in Electrical and Computer Engineering, December 2000.
[8] Charles N. Fischer Milo M. Martin, Amir Roth. Exploiting dead value information. Proceedings
of Micro-30, December 1997.
45](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-45-320.jpg)



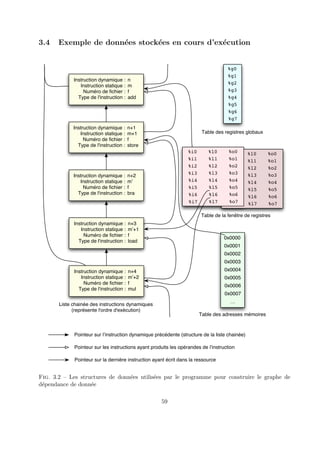
![3.3 R´esultat de l’´evaluation du travail inutile sur un exemple
simple
3.3.1 Code source en C de l’exemple
1 #include <stdio.h>
2
3
4 int main(void)
5 {
6 int tab[3],i;
7
8
9 for(i=0; i<3; i++) tab[i]=i*10;
10
11 printf("%d",tab[1]);
12
13 exit(0);
14 }
3.3.2 Code source en assembleur Sparc de l’exemple
Ce code est g´en´er´e par le compilateur cc avec les options ”-SO” et ”-XO0” (niveau d’optimisation
´egal `a 0).
! FILE exemple.c
! 1 !#include <stdio.h>
! 4 !int main(void)
! 5 !{
!
! SUBROUTINE main
!
! OFFSET SOURCE LINE LABEL INSTRUCTION
.global main
main:
/* 000000 5 */ save %sp,-120,%sp
! 6 ! int tab[3],i;
! 9 ! for(i=0; i<3; i++) tab[i]=i*10;
49](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-49-320.jpg)
![.L90:
/* 0x0004 9 */ or %g0,0,%g2
/* 0x0008 */ st %g2,[%fp-20]
/* 0x000c */ ld [%fp-20],%g3
/* 0x0010 */ cmp %g3,3
/* 0x0014 */ bl .L95
/* 0x0018 */ nop
/* 0x001c */ ba .L94
/* 0x0020 */ nop
.L95:
.L92:
/* 0x0024 9 */ ld [%fp-20],%g2
/* 0x0028 */ sll %g2,2,%g3
/* 0x002c */ add %g3,%g2,%g4
/* 0x0030 */ sll %g4,1,%o2
/* 0x0034 */ ld [%fp-20],%o3
/* 0x0038 */ sll %o3,2,%o4
/* 0x003c */ add %fp,-16,%o3
/* 0x0040 */ st %o2,[%o4+%o3] ! volatile
/* 0x0044 */ ld [%fp-20],%o4
/* 0x0048 */ add %o4,1,%o5
/* 0x004c */ st %o5,[%fp-20]
/* 0x0050 */ ld [%fp-20],%o7
/* 0x0054 */ cmp %o7,3
/* 0x0058 */ bl .L92
/* 0x005c */ nop
/* 0x0060 */ ba .L96
/* 0x0064 */ nop
.L96:
! 10 ! printf("%dn",tab[1]);
.L94:
/* 0x0068 10 */ sethi %hi(.L97),%g2
/* 0x006c */ add %g2,%lo(.L97),%g3
/* 0x0070 */ or %g0,%g3,%g4
/* 0x0074 */ or %g0,%g4,%o0
/* 0x0078 */ ld [%fp-12],%o2
/* 0x007c */ or %g0,%o2,%o1
/* 0x0080 */ call printf ! params = %o0 %o1 ! Result =
/* 0x0084 */ nop
! 11 !
! 12 ! exit(0);
/* 0x0088 12 */ or %g0,0,%o3
/* 0x008c */ or %g0,%o3,%o0
/* 0x0090 */ call exit ! params = %o0 ! Result =
50](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-50-320.jpg)
![/* 0x0094 */ nop
/* 0x0098 */ ba .L89
/* 0x009c */ nop
.L89:
/* 0x00a0 */ ret ! Result =
/* 0x00a4 */ restore %g0,%g0,%g0
/* 0x00a8 0 */ .type main,2
/* 0x00a8 0 */ .size main,(.-main)
/* 0x00a8 0 */ .global __fsr_init_value
/* 0x00a8 */ __fsr_init_value=0
3.3.3 Identifiant d’instruction statique
Ce fichier texte est obtenu apr`es passage de Salto sur le code source en assembleur de notre
exemple. Le num´ero statique permettant d’identifier une instruction se trouve entre crochets.
Salto rev. 1.4.2beta1 (built with g++ on sun4u)
Copyright (C) 1997 Inria, France
Machine description file ok.
CFG (0) :
BB (0) :
INST (0) [1] : save %o6,-120,%o6 in : 55 out : 55
BB (1) :
INST (0) [2] : or %g0,0,%g2 in : 41 out : 43
INST (1) [3] : st %g2,[%i6-20] in : 71 in : 43 out : 113
INST (2) [4] : ld [%i6-20],%g3 in : 71 in : 113 out : 44
INST (3) [5] : subcc %g3,3,%g0 in : 44 out : 74 out : 41
INST (4) [6] : bl .L95 in : 74
BB (2) :
INST (0) [7] : nop in : 39
INST (1) [8] : ba .L94 in : 74
BB (3) :
INST (0) [9] : nop in : 39
BB (4) :
INST (0) [10] : ld [%i6-20],%g2 in : 71 in : 113 out : 43
INST (1) [11] : sll %g2,2,%g3 in : 43 out : 44
INST (2) [12] : add %g3,%g2,%g4 in : 44 in : 43 out : 45
INST (3) [13] : sll %g4,1,%o2 in : 45 out : 51
INST (4) [14] : ld [%i6-20],%o3 in : 71 in : 113 out : 52
INST (5) [15] : sll %o3,2,%o4 in : 52 out : 53
INST (6) [16] : add %i6,-16,%o3 in : 71 out : 52
INST (7) [17] : st %o2,[%o4+%o3] in : 53 in : 52 in : 51 out : 113
INST (8) [18] : ld [%i6-20],%o4 in : 71 in : 113 out : 53
INST (9) [19] : add %o4,1,%o5 in : 53 out : 54
51](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-51-320.jpg)
![INST (10) [20] : st %o5,[%i6-20] in : 71 in : 54 out : 113
INST (11) [21] : ld [%i6-20],%o7 in : 71 in : 113 out : 56
INST (12) [22] : subcc %o7,3,%g0 in : 56 out : 74 out : 41
INST (13) [23] : bl .L92 in : 74
BB (5) :
INST (0) [24] : nop in : 39
INST (1) [25] : ba .L96 in : 74
BB (6) :
INST (0) [26] : nop in : 39
BB (7) :
INST (0) [27] : sethi %hi(.L97),%g2 out : 43
INST (1) [28] : add %g2,%lo(.L97),%g3 in : 43 out : 44
INST (2) [29] : or %g0,%g3,%g4 in : 41 in : 44 out : 45
INST (3) [30] : or %g0,%g4,%o0 in : 41 in : 45 out : 49
INST (4) [31] : ld [%i6-12],%o2 in : 71 in : 113 out : 51
INST (5) [32] : or %g0,%o2,%o1 in : 41 in : 51 out : 50
BB (8) :
INST (0) [33] : call printf out : 56
BB (9) :
INST (0) [34] : nop in : 39
INST (1) [35] : or %g0,0,%o3 in : 41 out : 52
INST (2) [36] : or %g0,%o3,%o0 in : 41 in : 52 out : 49
BB (10) :
INST (0) [37] : call exit out : 56
BB (11) :
INST (0) [38] : nop in : 39
INST (1) [39] : ba .L89 in : 74
BB (12) :
INST (0) [40] : nop in : 39
BB (13) :
INST (0) [41] : jmpl %i7+8,%g0 in : 72 out : 41
BB (14) :
INST (0) [42] : restore %g0,%g0,%g0 in : 41 in : 41 out : 41
3.3.4 Trace d’ex´ecution dynamique
La trace d’ex´ecution dynamique de ce programme de test est donn´ee par le programme d’´evaluation
de la quantit´e de travail inutile.
I.Dynamic 66 -- I.Static 38 -- File 1 -- nop -- D´epend de 0
I.Dynamic 65 -- I.Static 37 -- File 1 -- utile -- D´epend de 64
I.Dynamic 64 -- I.Static 36 -- File 1 -- utile -- D´epend de 63
I.Dynamic 63 -- I.Static 35 -- File 1 -- utile
I.Dynamic 62 -- I.Static 34 -- File 1 -- nop -- D´epend de 0
I.Dynamic 61 -- I.Static 33 -- File 1 -- utile -- D´epend de 58,60
52](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-52-320.jpg)







![12 mai 03 13:40 instrumentation.h Page 1/2
/* Défini le nom du fichier contenant les fonction définies localement par rappo
rt au programme (pas dans une bibliothèques) */
#define NOM_FICHIER_FONCTIONS_INTERNES "fonctions.txt"
/* Défini le nom du fichier contenant les fonction définies hors du programme (b
ibliothèques) mais non redéfinies dans le fichier redefinition.c */
#define NOM_FICHIER_FONCTIONS_EXTERNES_SPECIALES "fonctions_externes_speciales.txt"
void appelDeFonctionInstDebut(BB *bb, int position, unsigned int *nbInstructions
Ajoutees, int numeroInst, int typeInst, char *chaineAnnulBit);
void appelDeFonctionInstMilieu(BB *bb, int position, unsigned int *nbInstruction
sAjoutees, char *chaineAnnulBit);
void appelDeFonctionInstFin(BB *bb, int position, unsigned int *nbInstructionsAj
outees, char *chaineAnnulBit);
void appelDeFonctionReg(BB *bb, int position, unsigned int *nbInstructionsAjoute
es, int es, int indentificateurRessource, char *chaineAnnulBit);
int tailleAccesMemoire(INST *inst);
void appelDeFonctionMem(BB *bb, INST *inst, int position, unsigned int *nbInstru
ctionsAjoutees, int es, char *acces1, char *acces2, char *chaineAnnulBit, int ta
illeAccesMemoire);
void appelDeFonctionCopierInstDelay(BB *bb, int position, unsigned int *nbInstru
ctionsAjoutees);
void appelDeFonctionEchangerInstDelay(BB *bb, int position, unsigned int *nbInst
ructionsAjoutees);
int rechercheChaine(char *chaine, FILE *fichier);
int estPresent(char *motif, char *chaine);
int typeInstruction(INST *inst);
void operandeMemoire(char *instruction, char *acces1, char *acces2);
// Fonction permettant de sauvagarder le contexte du programme (registres généra
ux et codes conditions) afin de ne pas
// intervenir sur les valeurs des registres et codes conditions utilisés par le
programme
void sauvegardeContexte(BB *bb, int position, unsigned int *nbInstructionsAjoute
es);
// Fonction permettant de restaurer le contexte du programme (registres généraux
et codes conditions) afin de ne pas
// intervenir sur les valeurs des registres et codes conditions utilisés par le
programme
void restaurationContexte(BB *bb, int position, unsigned int *nbInstructionsAjou
tees);
int registreSalto(char *acces);
void blancSuivant(char **ptr);
// Insère le code permettant d’instrumenter en fonction des entrées produites pa
r inst
void appelDeFonctionsEntrees(INST *inst, BB *bb, int position, unsigned int *nbI
nstructionsAjoutees, char *chaineAnnulBit);
// Ajout de l’instrumentation représentant les entrées fictives des call externe
s
void appelDeFonctionsEntreesAppelExterne(INST *inst, BB *bb, int position, unsig
ned int *nbInstructionsAjoutees);
// Insère le code permettant d’instrumenter en fonction des sorties produites pa
r inst
void appelDeFonctionsSorties(INST *inst, BB *bb, int position, unsigned int *nbI
nstructionsAjoutees, char *chaineAnnulBit);
// Ajout de l’instrumentation représentant les sorties fictives des call externe
s
void appelDeFonctionsSortiesAppelExterne(INST *inst, BB *bb, int position, unsig
ned int *nbInstructionsAjoutees);
void instrumenter(INST *inst, BB *bb, BB *bbSuivant, int position, unsigned int
*nbInstructionsAjoutees, int numeroInst);
void ajouterCommentaireAppelExterne(INST *inst);
void Salto_hook();
12 mai 03 13:40 instrumentation.h Page 2/2
void Salto_init_hook(int argc, char *argv[]);
void Salto_end_hook();
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation.h 1/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-61-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 1/23
#include <stdio.h>
#include <fcntl.h>
#include <errno.h>
#include <fstream>
#include <iostream>
#include <sys/types.h>
#include <regex.h>
#include <stdlib.h>
#include <string.h>
#include "salto.h"
#include "instrumentation.h"
#include "instrument.h"
#define FICHIER_SOURCE_ASSEMBLEUR ".s$"
#define REPERTOIRE_FICHIER_INSTRUMENTES "instrumente/"
#define IN 0
#define OUT 1
#define EXP_REGISTRE "^%[golisf][0−7p]$"
#define EXP_MEMOIRE "[[−+%a−zA−Z0−9_.()]+]"
#define EXP_FONCTION "[ ]+call[ ]+"
#define EXP_SAVE "[ ]+save[ ]+"
#define EXP_RESTORE "[ ]+restore[ ]+"
#define EXP_ANNUL_BIT ",a"
#define EXP_LOAD "ld[usd]?[bh]?"
#define EXP_STORE "st[bhd]?"
#define ETIQUETTE_FONCTION_NOP "f_nop"
#define PREFIXE_FONCTIONS_EXTERNES "my_"
#define SAVE "save %sp,−136,%sp"
#define RESTORE "restore %g0,%g0,%g0"
#define NOP "nop"
// Pointeur sur le fichier dans lequel sera écrit le code instrumenté
FILE *fichierSInstrumente;
// Pointeur sur le fichier contenant le code original (non instrumenté)
FILE *fichierSOriginal;
// Permet d’identifier de manière unique le fichier en cours de traitement
unsigned char numeroFichier;
void appelDeFonctionInstDebut(BB *bb, int position, unsigned int *nbInstructions
Ajoutees, int numeroInst, int typeInst, char *chaineAnnulBit)
{
char chaine[20],tmp[100];
// On empile un paramètre de type entier à passer à la fonction (équivaut à m
ov typeInst,%o0)
sprintf(chaine,"or %%g0,%d,%%o0",typeInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Si la constante numeroInst à ranger dans %o1 peut être codée sur 13 bits (
Imprimé par Benjamin Vidal
03 jun 03 16:11 instrumentation.cc Page 2/23
i.e. est entre −4096 et 4095)
if(numeroInst <= 4095)
{
// On empile un paramètre de type entier à passer à la fonction (équivaut à
mov numeroInst,%o1)
sprintf(chaine,"or %%g0,%d,%%o1",numeroInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
}
else
{
// On empile ce même paramètre mais en deux fois (les 22 premiers bits du r
egistre d’abbord)
sprintf(chaine,"sethi %%hi(%d),%%o1",numeroInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Puis les 10 derniers bits ensuite
sprintf(chaine,"or %%o1,%%lo(%d),%%o1",numeroInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
}
// On empile un paramètre de type entier à passer à la fonction (équivaut à m
ov numeroFichier,%o1)
sprintf(chaine,"or %%g0,%d,%%o2",numeroFichier);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Si l’instruction que l’on instrumente est un branchement avec un annulBit
(ex : bl,a ...) on insère une instruction qui
// va inhiber l’effet du call suivant lorsque l’annulation de l’exécution de
l’instruction se trouvant dans le DelaySlot
// sera effective (cela ne peut être vu qu’à l’exécution et donc ne peut être
fait statiquement)
if (chaineAnnulBit != NULL)
{
INST *inst_br_nop;
inst_br_nop = newAsm(NOP);
inst_br_nop−>addAttribute(UNPARSE_ATT, chaineAnnulBit, strlen(chaineAnnulBi
t)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_br_nop);
(*nbInstructionsAjoutees)++;
strcpy(tmp,"b ");
}
else strcpy(tmp,"call ");
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_DEB
UT_INST)));
(*nbInstructionsAjoutees)++;
// On ajoute un nop afin de combler le delay slot
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
void appelDeFonctionInstMilieu(BB *bb, int position, unsigned int *nbInstruction
sAjoutees, char *chaineAnnulBit)
{
mercredi 18 juin 2003 instrumentation.cc 2/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-62-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 3/23
char tmp[100];
// Si l’instruction que l’on instrumente est un branchement avec un annulBit
(ex : bl,a ...) on insère une instruction qui
// va inhiber l’effet du call suivant lorsque l’annulation de l’exécution de
l’instruction se trouvant dans le DelaySlot
// sera effective (cela ne peut être vu qu’à l’exécution et donc ne peut être
fait statiquement)
if (chaineAnnulBit != NULL)
{
INST *inst_br_nop;
inst_br_nop = newAsm(NOP);
inst_br_nop−>addAttribute(UNPARSE_ATT, chaineAnnulBit, strlen(chaineAnnulBi
t)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_br_nop);
(*nbInstructionsAjoutees)++;
strcpy(tmp,"b ");
}
else strcpy(tmp,"call ");
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_MIL
IEU_INST)));
(*nbInstructionsAjoutees)++;
// On ajoute un nop afin de combler le delay slot
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
void appelDeFonctionInstFin(BB *bb, int position, unsigned int *nbInstructionsAj
outees, char *chaineAnnulBit)
{
char tmp[100];
// Si l’instruction que l’on instrumente est un branchement avec un annulBit
(ex : bl,a ...) on insère une instruction qui
// va inhiber l’effet du call suivant lorsque l’annulation de l’exécution de
l’instruction se trouvant dans le DelaySlot
// sera effective (cela ne peut être vu qu’à l’exécution et donc ne peut être
fait statiquement)
if (chaineAnnulBit != NULL)
{
INST *inst_br_nop;
inst_br_nop = newAsm(NOP);
inst_br_nop−>addAttribute(UNPARSE_ATT, chaineAnnulBit, strlen(chaineAnnulBi
t)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_br_nop);
(*nbInstructionsAjoutees)++;
strcpy(tmp,"b ");
}
else strcpy(tmp,"call ");
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_FIN
_INST)));
(*nbInstructionsAjoutees)++;
Imprimé par Benjamin Vidal
// On ajoute un nop afin de combler le delay slot
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
void appelDeFonctionReg(BB *bb, int position, unsigned int *nbInstructionsAjoute
es, int es, int indentificateurRessource, char *chaineAnnulBit)
{
char chaine[20],tmp[100];
// On empile le paramètre de type entier à passer à la fonction (équivaut à m
ov %d,%o0)
sprintf(chaine,"or %%g0,%d,%%o0",indentificateurRessource);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Si l’instruction que l’on instrumente est un branchement avec un annulBit
(ex : bl,a ...) on insère une instruction qui
// va inhiber l’effet du call suivant lorsque l’annulation de l’exécution de
l’instruction se trouvant dans le DelaySlot
// sera effective (cela ne peut être vu qu’à l’exécution et donc ne peut être
fait statiquement)
if (chaineAnnulBit != NULL)
{
INST *inst_br_nop;
inst_br_nop = newAsm(NOP);
inst_br_nop−>addAttribute(UNPARSE_ATT, chaineAnnulBit, strlen(chaineAnnulBi
t)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_br_nop);
(*nbInstructionsAjoutees)++;
strcpy(tmp,"b ");
}
else strcpy(tmp,"call ");
// Appel de la fonction définie "ailleurs" (fichier instrument.c)
// Si le paramètre de l’instruction à instrumentée est un paramètre d’entrée
if (es==IN)
{
// On appelle la fonction de traitement spécifique aux paramètres d’entrée
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_I
N_REG)));
(*nbInstructionsAjoutees)++;
}
// Si le paramètre de l’instruction a instrumenter est un paramètre de sortie
else
{
// On appelle la fonction de traitement spécifique aux paramètres de sortie
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_O
UT_REG)));
(*nbInstructionsAjoutees)++;
}
// On ajoute un nop afin de combler le delay slot
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
03 jun 03 16:11 instrumentation.cc Page 4/23
mercredi 18 juin 2003 instrumentation.cc 3/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-63-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 5/23
int tailleAccesMemoire(INST *inst)
{
regex_t *preg = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch[nmatch];
// Compilation de l’expression régulière permettant de détecter si une instruc
tion est un load
if (regcomp(preg, EXP_LOAD, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_LOAD""n");
exit(4);
}
// Si l’instruction est un load
if (regexec(preg, inst−>unparse(), nmatch, pmatch, 0) != REG_NOMATCH)
{
regfree(preg);
// Si le dernier caractère de l’expression est un b, alors le load est un lo
ad byte
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’b’) return 1;
// Si le dernier caractère de l’expression est un h, alors le load est un lo
ad half−word
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’h’) return 2;
// Si le dernier caractère de l’expression est un d et que ce caractère est
en deuxième position, alors le load est un load word
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’d’ && pmatch[0].rm_eo == 3) return
4;
// Si le dernier caractère de l’expression est un d et que ce caractère est
en troisième position, alors le load est un load double−word
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’d’ && pmatch[0].rm_eo == 4) return
8;
fprintf(STDERR,"Impossible de reconnaitre la taille des données lues par l’instruction "%s"n",inst−>
unparse());
fprintf(STDERR,"Fonction tailleAccesMemoire du fichier instrumentation.ccn");
exit(7);
}
// Compilation de l’expression régulière permettant de détecter si une instruc
tion est un store
if (regcomp(preg, EXP_STORE, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_STORE""n");
exit(4);
}
// Si l’instruction est un store
if (regexec(preg, inst−>unparse(), nmatch, pmatch, 0) != REG_NOMATCH)
{
regfree(preg);
// Si le dernier caractère de l’expression est un b, alors le store est un s
tore byte
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’b’) return 1;
// Si le dernier caractère de l’expression est un h, alors le store est un s
tore half−word
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’h’) return 2;
// Si le dernier caractère de l’expression est un t, alors le store est un s
tore word
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’t’) return 4;
// Si le dernier caractère de l’expression est un d, alors le store est un s
tore double−word
if(inst−>unparse()[pmatch[0].rm_eo−1] == ’d’) return 8;
03 jun 03 16:11 instrumentation.cc Page 6/23
fprintf(STDERR,"Impossible de reconnaitre la taille des données lues par l’instruction "%s"n",inst−>
unparse());
fprintf(STDERR,"Fonction tailleAccesMemoire du fichier instrumentation.ccn");
exit(7);
}
}
void appelDeFonctionMem(BB *bb, INST *inst, int position, unsigned int *nbInstru
ctionsAjoutees, int es, char *acces1, char *acces2, char *chaineAnnulBit, int ta
illeAccesMemoire)
{
char chaine[200],tmp[100];
// * Sauvegarde de la valeur stockée dans %i0 dans la pile afin de pouvoir la
récupérer par la suite
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm("st %i0,[%sp+124]"));
(*nbInstructionsAjoutees)++;
// Cette instruction permet de récupérer l’état des registres tels qu’ils éta
it au moment
// ou l’appel de l’instruction instrumentée était iminent (on descend d’un cr
an le contexte)
restaurationContexte(bb, position, nbInstructionsAjoutees);
// Insertion de l’instruction permettant de faire passer le résultat du calcu
l au contexte supérieure
// (fenêtre de registre placée au dessus)
sprintf(chaine,"add %s,%s,%%o0",acces1,acces2);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Puis on repasse dans le contexte supérieur
sauvegardeContexte(bb, position, nbInstructionsAjoutees);
// En fin on récupère le résultat calculé par l’addition pour le passer en pa
ramètre à la fonction
// qui va être appellée (mov %i0,%o0)
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm("or %g0,%i0,%o0"));
(*nbInstructionsAjoutees)++;
// * Restauration de la valeur stockée dans %o0 (valeur qui avait été sauvega
rdée par "st %i0,[%sp+124]")
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm("ld [%sp+124],%i0"));
(*nbInstructionsAjoutees)++;
// On range dans %o1 la taille de l’acces mémoire effectué (nombre d’octets l
us ou écrits par l’instruction
sprintf(chaine,"or %%g0,%d,%%o1",tailleAccesMemoire);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Si l’instruction que l’on instrumente est un branchement avec un annulBit
(ex : bl,a ...) on insère une instruction qui
// va inhiber l’effet du "call suivant" lorsque l’annulation de l’exécution d
e l’instruction se trouvant dans le DelaySlot
// sera effective (cela ne peut être vu qu’à l’exécution et donc ne peut être
fait statiquement)
if (chaineAnnulBit != NULL)
{
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation.cc 4/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-64-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 7/23
INST *inst_br_nop;
inst_br_nop = newAsm(NOP);
inst_br_nop−>addAttribute(UNPARSE_ATT, chaineAnnulBit, strlen(chaineAnnulBi
t)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_br_nop);
(*nbInstructionsAjoutees)++;
strcpy(tmp,"b ");
}
else strcpy(tmp,"call ");
// Appel de la fonction définie "ailleurs" (fichier instrument.c)
// Si le paramètre de l’instruction à instrumentée est un paramètre d’entrée
if (es==IN)
{
// On appelle la fonction de traitement spécifique aux paramètres d’entrée
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_I
N_MEM)));
(*nbInstructionsAjoutees)++;
}
// Si le paramètre de l’instruction à instrumentée est un paramètre de sortie
else
{
// On appelle la fonction de traitement spécifique aux paramètres de sortie
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(strcat(tmp,NOM_FCT_O
UT_MEM)));
(*nbInstructionsAjoutees)++;
}
// On comble le delay slot de l’appel de fonction précédent par un nop
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
void appelDeFonctionCopierInstDelay(BB *bb, int position, unsigned int *nbInstru
ctionsAjoutees)
{
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm("call copierInstDelay"));
(*nbInstructionsAjoutees)++;
// On ajoute un nop afin de combler le delay slot
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
void appelDeFonctionEchangerInstDelay(BB *bb, int position, unsigned int *nbInst
ructionsAjoutees)
{
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm("call echangerInstDelay"));
(*nbInstructionsAjoutees)++;
// On ajoute un nop afin de combler le delay slot
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(NOP));
(*nbInstructionsAjoutees)++;
}
int rechercheChaine(char *chaine, FILE *fichier)
{
03 jun 03 16:11 instrumentation.cc Page 8/23
char chaine2[100];
while (!feof(fichier))
{
fscanf(fichier,"%s",chaine2);
if(!strcmp(chaine,chaine2)) return 1;
}
return 0;
}
int estPresent(char *motif, char *chaine)
{
int i;
regex_t *preg = new regex_t();
size_t nmatch = 10;
regmatch_t pmatch[nmatch];
// Compilation de l’expression régulière
if (regcomp(preg, motif, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière "%s"n",motif);
exit(4);
}
// Exécution de l’expression régulière et renvoi du résultat en fonction
if (regexec(preg, chaine, nmatch, pmatch, 0) == REG_NOMATCH)
{
regfree(preg);
return 0;
}
for(i=0; i<nmatch && pmatch[i].rm_so!=−1; i++);
regfree(preg);
return i;
}
int typeInstruction(INST *inst)
{
int i,j;
char tmp[100];
regex_t *preg = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch[nmatch];
FILE *fichier;
// Si l’instruction est une instruction "save", on retourne la valeur T_SAVE
if (estPresent(EXP_SAVE,inst−>unparse())) return T_SAVE;
// Si l’instruction est une instruction "restore", on retourne la valeur T_RES
TORE
if (estPresent(EXP_RESTORE,inst−>unparse())) return T_RESTORE;
// Compilation de l’expression régulière permettant de détecter si une instruc
tion est une instruction de sortie
// (printf entre autre)
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation.cc 5/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-65-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 9/23
if (regcomp(preg, EXP_FONCTION, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_FONCTION""n");
exit(4);
}
// Si l’instruction est un call
if (regexec(preg, inst−>unparse(), nmatch, pmatch, 0) != REG_NOMATCH)
{
// On récupère dans la chaine tmp l’étiquette à laquelle on va brancher en e
xécutant le call
for(i=0,j=pmatch[0].rm_eo; j<strlen(inst−>unparse()); j++)
if((inst−>unparse())[j]!=’ ’ && (inst−>unparse())[j]!=’t’) tmp[i++]=(inst−
>unparse())[j];
tmp[i] = ’0’;
regfree(preg);
fichier = fopen(NOM_FICHIER_FONCTIONS_INTERNES, "r");
if(fichier == NULL)
{
fprintf(STDERR,"Problème lors de l’ouverture du fichier ""NOM_FICHIER_FONCTIONS_INTERNE
S"" ");
fprintf(STDERR,"(fonction typeInstruction dans le fichier instrumentation.cc)n");
exit(11);
}
// On recherche dans notre base de nom de fonctions définies localement si l
a fonction désignée par l’étiquette
// fait partie du code qui à était instrumenté ou non
if(rechercheChaine(tmp,fichier))
{
fclose(fichier);
return T_APPEL_INTERNE;
}
fclose(fichier);
fichier = fopen(NOM_FICHIER_FONCTIONS_EXTERNES_SPECIALES,"r");
if(fichier == NULL)
{
fprintf(STDERR,"Problème lors de l’ouverture du fichier ""NOM_FICHIER_FONCTIONS_EXTERNE
S_SPECIALES"" ");
fprintf(STDERR,"(fonction typeInstruction dans le fichier instrumentation.cc)n");
exit(11);
}
if(rechercheChaine(tmp,fichier))
{
fclose(fichier);
return T_APPEL_EXTERNE_SPECIAL;
}
fclose(fichier);
return T_APPEL_EXTERNE;
}
// Si l’instruction est un "nop", on retourne la valeur T_NOP
if (inst−>isNop()) return T_NOP;
// Si l’instruction est un branchement, on retourne la valeur T_BRANCHEMENT
if (inst−>isCTI())
if(estPresent(EXP_ANNUL_BIT,inst−>unparse()))
Imprimé par Benjamin Vidal
03 jun 03 16:11 instrumentation.cc Page 10/23
return T_BRANCHEMENT_ANNUL_BIT;
else return T_BRANCHEMENT;
// Si l’instruction est une instruction "ld", on retourne la valeur T_LOAD
if (estPresent(EXP_LOAD,inst−>unparse())) return T_LOAD;
// Si l’instruction est une instruction "st", on retourne la valeur T_STORE
if (estPresent(EXP_STORE,inst−>unparse())) return T_STORE;
return T_AUTRE;
}
void operandeMemoire(char *instruction, char *acces1, char *acces2)
{
int i,j;
char tmp[10];
regex_t *preg_mem = new regex_t();
regex_t *preg_signe = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch_mem[nmatch];
regmatch_t pmatch_signe[nmatch];
// Compilation de l’expression régulière permettant de détecter un acces mémoi
re d’une instruction
if (regcomp(preg_mem, EXP_MEMOIRE, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_MEMOIRE""n");
exit(4);
}
if (regcomp(preg_signe, "[−+]", REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière "[−+]"n");
exit(4);
}
if (regexec(preg_mem, instruction, nmatch, pmatch_mem, 0) == REG_NOMATCH)
{
fprintf(STDERR,"Erreur lors de l’exécution de l’expression régulière ""EXP_MEMOIRE"" : impossible d
e ");
fprintf(STDERR,"trouver un motif correspondant à cette expression dans l’instruction "%s"n",instru
ction);
exit(4);
}
if (regexec(preg_signe, instruction, nmatch, pmatch_signe, 0) == REG_NOMATCH)
{
// On récupère la chaine de caractère correspondant au nom du registre auque
l on accède
for(i=0,j=pmatch_mem[0].rm_so+1; j<pmatch_mem[0].rm_eo−1; j++) acces1[i++]=i
nstruction[j];
acces1[i] = ’0’;
strcpy(acces2,"0");
}
else
{
// On récupère la chaine de caractère correspondant au nom du premier regist
re auquel on accède
for(i=0,j=pmatch_mem[0].rm_so+1; j<pmatch_signe[0].rm_so; j++) acces1[i++]=i
mercredi 18 juin 2003 instrumentation.cc 6/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-66-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 11/23
nstruction[j];
acces1[i] = ’0’;
i=0;
// Si le signe reconnu par l’expression régulière [−+] est un moins, on le r
ejoute en début de chaine
// possible seulement si le deuxième acces est une constante (ex : ld [%i6−6
0],%o0)
if (instruction[pmatch_signe[0].rm_so] == ’−’) acces2[i++] = ’−’;
// On récupère la chaine de caractère correspondant au nom du deuxième regis
tre auquel on accède ou à la constante
for(j=pmatch_signe[0].rm_eo; j<pmatch_mem[0].rm_eo−1; j++)
acces2[i++] = instruction[j];
acces2[i] = ’0’;
}
regfree(preg_mem);
regfree(preg_signe);
}
// Fonction permettant de sauvagarder le contexte du programme (registres généra
ux et codes conditions) afin de ne pas
// intervenir sur les valeurs des registres et codes conditions utilisés par le
programme
void sauvegardeContexte(BB *bb, int position, unsigned int *nbInstructionsAjoute
es)
{
INST *inst_ccr;
char *lectureCodesConditions = "trd %ccr,%l0n";
// "Empilement" du contexte du programme (création d’un contexte intermédiaire
artificiel entre l’exécution du
// programme et l’exécution des fonctions d’instrumentation du code. Ce contex
te permet de travailler avec
// les registres %o[0−5] afin de faire passer les paramètres aux fonctions d’i
nstrumentations.
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(SAVE));
(*nbInstructionsAjoutees)++;
inst_ccr = newAsm(NOP);
inst_ccr−>addAttribute(UNPARSE_ATT, lectureCodesConditions, strlen(lectureCode
sConditions)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_ccr);
(*nbInstructionsAjoutees)++;
// Sauvegarde en mémoire (dans la pile) des registres globaux
for(int i=1; i<=4; i++)
{
char tmp[20];
// Sauvegarde du registre (%gi) (ex : "st %g1,[%sp+92]")
sprintf(tmp,"st %%g%d,[%%sp+%d]",i,88+(4*i));
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(tmp));
(*nbInstructionsAjoutees)++;
}
}
// Fonction permettant de restaurer le contexte du programme (registres généraux
et codes conditions) afin de ne pas
// intervenir sur les valeurs des registres et codes conditions utilisés par le
03 jun 03 16:11 instrumentation.cc Page 12/23
programme
void restaurationContexte(BB *bb, int position, unsigned int *nbInstructionsAjou
tees)
{
INST *inst_ccr;
char *ecritureCodesConditions = "twr %l0,%ccrn";
// Récupération des registres globaux depuis la mémoire (depuis la pile)
for(int i=1; i<=4; i++)
{
char tmp[20];
// Restauration du registre (%gi) (ex : "ld [%sp+92],%g1")
sprintf(tmp,"ld [%%sp+%d],%%g%d",88+(4*i),i);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(tmp));
(*nbInstructionsAjoutees)++;
}
inst_ccr = newAsm(NOP);
inst_ccr−>addAttribute(UNPARSE_ATT, ecritureCodesConditions, strlen(ecritureCo
desConditions)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, inst_ccr);
(*nbInstructionsAjoutees)++;
// "Dépilement" du contexte du programme
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(RESTORE));
(*nbInstructionsAjoutees)++;
}
int registreSalto(char *acces)
{
regex_t *preg = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch[nmatch];
// Compilation de l’expression régulière permettant de détecter un registre
if (regcomp(preg, EXP_REGISTRE, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_REGISTRE""n");
exit(4);
}
if (regexec(preg, acces, nmatch, pmatch, 0) == REG_NOMATCH)
{
regfree(preg);
return 0;
}
regfree(preg);
// Traitement des cas particuliers : %sp et %fp (correspondant à %o6 et %i6)
if (!strcmp(acces,"%sp")) return ID_REG_SALTO_O+6;
if (!strcmp(acces,"%fp")) return ID_REG_SALTO_I+6;
// Traitement du cas général
switch (acces[1])
{
case ’g’ : return ID_REG_SALTO_G+atoi(&(acces[2]));
case ’o’ : return ID_REG_SALTO_O+atoi(&(acces[2]));
case ’l’ : return ID_REG_SALTO_L+atoi(&(acces[2]));
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation.cc 7/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-67-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 13/23
case ’i’ : return ID_REG_SALTO_I+atoi(&(acces[2]));
default : fprintf(STDERR,"Passage impossible : fonction registreSalto dans instrumentation.ccn")
;
}
}
void blancSuivant(char **ptr)
{
while ((*ptr)[0]!=’ ’ && (*ptr)[0]!=’t’ && (*ptr)[0]!=’n’ && (*ptr)[0]!=’0’) (
*ptr)++;
while ((*ptr)[0]==’ ’ || (*ptr)[0]==’t’ || (*ptr)[0]==’n’) (*ptr)++;
}
// Insère le code permettant d’instrumenter en fonction des entrées produites pa
r inst
void appelDeFonctionsEntrees(INST *inst, BB *bb, int position, unsigned int *nbI
nstructionsAjoutees, char *chaineAnnulBit)
{
ResourceDataBase &rdb = xxx_server −> GetResT();
res_ref* in;
ResId_T identificateurRessource;
// Ajout de l’instrumentation représentant les entrées de l’instruction fourni
e par salto (lectures)
for (int i=0; i < inst−>numberOfInput(); i++)
{
in = inst−>getInput(i);
identificateurRessource = in−>get_res_id();
// Traitement fait pour chaque opérandes d’entrée
switch ((rdb.get_res(identificateurRessource))−>getType())
{
case MEMORY_RTYPE :
char acces1[100],acces2[100];
operandeMemoire(inst−>unparse(), acces1, acces2);
appelDeFonctionMem(bb, inst, position, nbInstructionsAjoutees, IN, acces
1, acces2, chaineAnnulBit, tailleAccesMemoire(inst));
break;
case REGISTER_RTYPE :
appelDeFonctionReg(bb, position, nbInstructionsAjoutees, IN, identificat
eurRessource, chaineAnnulBit);
break;
default :
fprintf(STDERR,"Passage impossible : fonction appelDeFonctionsEntrees dans instrumentation.ccn"
);
}
}
}
// Ajout de l’instrumentation représentant les entrées fictives des call externe
s
void appelDeFonctionsEntreesAppelExterne(INST *inst, BB *bb, int position, unsig
ned int *nbInstructionsAjoutees)
{
char acces[20];
char *ptr = (char *)(inst−>attributeValue(IN,COMMENT_ATT));
int identificateurRessource;
03 jun 03 16:11 instrumentation.cc Page 14/23
sscanf(ptr,"%s",acces);
// Tant qu’on n’a pas atteint la fin de la chaine de caractère contenant les e
ntrées effectuées par le call traité
while (ptr[0] != ’0’)
{
blancSuivant(&ptr);
identificateurRessource = registreSalto(acces);
if(identificateurRessource != 0)
appelDeFonctionReg(bb, position, nbInstructionsAjoutees, IN, identificateu
rRessource, NULL);
else
{
char tmp[20],acces1[100],acces2[100];
strcpy(tmp,"[");
strcat(tmp,acces);
strcat(tmp,"]");
operandeMemoire(tmp, acces1, acces2);
appelDeFonctionMem(bb, inst, position, nbInstructionsAjoutees, IN, acces1,
acces2, NULL, 4);
}
sscanf(ptr,"%s",acces);
}
// Les fonctions définies hors du fichier local font toujours un accès en lect
ure à %o6 (pointeur de pile)
// et à %o7 (adresse de retour)
/*appelDeFonctionReg(bb, position, nbInstructionsAjoutees, IN, ID_REG_SALTO_O+
6, NULL);
appelDeFonctionReg(bb, position, nbInstructionsAjoutees, IN, ID_REG_SALTO_O+7,
NULL);*/
}
// Insère le code permettant d’instrumenter en fonction des sorties produites pa
r inst
void appelDeFonctionsSorties(INST *inst, BB *bb, int position, unsigned int *nbI
nstructionsAjoutees, char *chaineAnnulBit)
{
ResourceDataBase &rdb = xxx_server −> GetResT();
res_ref* out;
int identificateurRessource;
// Ajout de l’instrumentation représentant les sorties de l’instruction fourni
e par salto (écritures)
for (int i=0; i < inst−>numberOfOutput(); i++)
{
out = inst−>getOutput(i);
identificateurRessource = out−>get_res_id();
// Traitement fait pour chaque opérandes de sortie
switch ((rdb.get_res(identificateurRessource))−>getType())
{
case MEMORY_RTYPE :
char acces1[100],acces2[100];
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation.cc 8/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-68-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 15/23
operandeMemoire(inst−>unparse(), acces1, acces2);
appelDeFonctionMem(bb, inst, position, nbInstructionsAjoutees, OUT, acce
s1, acces2, chaineAnnulBit, tailleAccesMemoire(inst));
break;
case REGISTER_RTYPE :
appelDeFonctionReg(bb, position, nbInstructionsAjoutees, OUT, identifica
teurRessource, chaineAnnulBit);
break;
default :
fprintf(STDERR,"Passage impossible : fonction appelDeFonctionsSorties dans instrumentation.ccn"
);
}
}
}
// Ajout de l’instrumentation représentant les sorties fictives des call externe
s
void appelDeFonctionsSortiesAppelExterne(INST *inst, BB *bb, int position, unsig
ned int *nbInstructionsAjoutees)
{
char *acces = (char *)(inst−>attributeValue(OUT,COMMENT_ATT));
ResId_T identificateurRessource = registreSalto(acces);
if(identificateurRessource == 0)
{
fprintf(STDERR,"Erreur : la chaine "%s" n’est pas reconnue comme étant un registre par la fonction ",a
cces);
fprintf(STDERR,"registreSalto(char*) (fonction appelDeFonctionsSortiesAppelExterne dans instrumentatio
n.cc)n");
exit(9);
}
appelDeFonctionReg(bb, position, nbInstructionsAjoutees, OUT, identificateurRe
ssource, NULL);
}
void instrumenter(INST *inst, BB *bb, BB *bbSuivant, int position, unsigned int
*nbInstructionsAjoutees, int numeroInst)
{
static unsigned char flagDelaySlot = 0;
// Si l’instruction est une instruction d’appel externe, on remplace "call tar
tampion" par "call my_tartempion"
// pour détourner l’appel "normal" à la fonction de la librairie en un appel à
une fonction redéfinie permettant de
// rendre compte des accès mémoires fait par ces fonctions
if(typeInstruction(inst) == T_APPEL_EXTERNE)
{
char chaine[100],chaine2[100], *tmp;
sscanf(inst−>unparse(),"%s %s",chaine,chaine2);
strcpy(chaine, "tcall "PREFIXE_FONCTIONS_EXTERNES);
// Allocation d’une nouvelle chaine de caractère contenant la nouvelle repré
sentation de l’instruction
tmp = (char *)malloc((strlen(chaine)+strlen(chaine2)+2)*sizeof(char));
strcpy(tmp,chaine);
Imprimé par Benjamin Vidal
03 jun 03 16:11 instrumentation.cc Page 16/23
strcat(tmp,chaine2);
strcat(tmp,"n");
inst−>addAttribute(UNPARSE_ATT, tmp, strlen(tmp)+1);
}
// Si on n’a pas à faire à une instruction se trouvant dans un DelaySlot
if(flagDelaySlot == 0)
// Si l’instruction n’est pas un branchement, alors, on instrumente cette in
struction normalement
if(!inst−>isCTI())
{
sauvegardeContexte(bb, position, nbInstructionsAjoutees);
appelDeFonctionInstDebut(bb, position, nbInstructionsAjoutees, numeroInst,
typeInstruction(inst), NULL);
appelDeFonctionsEntrees(inst, bb, position, nbInstructionsAjoutees, NULL);
if(typeInstruction(inst)==T_SAVE || typeInstruction(inst)==T_RESTORE)
appelDeFonctionInstMilieu(bb, position, nbInstructionsAjoutees, NULL);
appelDeFonctionsSorties(inst, bb, position, nbInstructionsAjoutees, NULL);
appelDeFonctionInstFin(bb, position, nbInstructionsAjoutees, NULL);
restaurationContexte(bb, position, nbInstructionsAjoutees);
}
// Si l’instruction courante est un branchement, alors, on l’instrumente ain
si que son DelaySlot
else
{
char *chaineAnnulBit = (char *)malloc(100*sizeof(char));
INST *instDelaySlot = bbSuivant−>getAsm(0);
/*fprintf(STDERR,"Inst <%s>tttDelay <%s>n",inst−>unparse(),instDelaySl
ot−>unparse());*/
// On met le flag à 1 pour indiquer que l’instrumentation de l’instruction
se trouvant dans le DelaySlot
// du branchement que l’on est en train de traiter a déjà été instrumentée
flagDelaySlot = 1;
sauvegardeContexte(bb, position, nbInstructionsAjoutees);
// On traite le début de l’instruction de branchement
appelDeFonctionInstDebut(bb, position, nbInstructionsAjoutees, numeroIns
t, typeInstruction(inst), NULL);
// On traite les lectures de l’instruction de branchement
appelDeFonctionsEntrees(inst, bb, position, nbInstructionsAjoutees, NULL
);
// On traite les écritures de l’instruction de branchement
appelDeFonctionsSorties(inst, bb, position, nbInstructionsAjoutees, NULL
);
appelDeFonctionCopierInstDelay(bb, position, nbInstructionsAjoutees);
// Si le branchement est un brachement avec annul_bit (ex : bl,a ...
) alors on rempli la chaine de caractère
// chaineAnnulBit en conséquence (on y met les instructions pour tra
iter ce cas correctement)
if(typeInstruction(inst) == T_BRANCHEMENT_ANNUL_BIT)
mercredi 18 juin 2003 instrumentation.cc 9/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-69-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 17/23
{
int i;
char tmp[20];
regex_t *preg = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch[nmatch];
if (regcomp(preg, EXP_ANNUL_BIT, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_ANNUL
_BIT""n");
exit(4);
}
if (regexec(preg, inst−>unparse(), nmatch, pmatch, 0) == REG_NOMAT
CH)
{
fprintf(STDERR,"Erreur lors de l’exécution de l’expression régulière ""EXP_ANNUL_B
IT"" :n");
fprintf(STDERR,"Impossible de trouver l’expression régulière dans l’instruction "%s"n
",inst−>unparse());
exit(4);
}
regfree(preg);
for(i=0; i<pmatch[0].rm_eo; i++)
tmp[i] = (inst−>unparse())[i];
tmp[i] = ’0’;
strcpy(chaineAnnulBit,"trd %pc,%o7n");
strcat(chaineAnnulBit,"tadd %o7,16,%o7n");
strcat(chaineAnnulBit,"twr %l0,%ccrn");
strcat(chaineAnnulBit,tmp);
strcat(chaineAnnulBit," "ETIQUETTE_FONCTION_NOP"n");
}
else chaineAnnulBit = NULL;
// On traite le début de l’instruction qui se trouve dans le DelaySl
ot
appelDeFonctionInstDebut(bb, position, nbInstructionsAjoutees, numer
oInst+1, typeInstruction(instDelaySlot), chaineAnnulBit);
// On traite les lectures de l’instruction se trouvant dans le Delay
Slot du branchement
appelDeFonctionsEntrees(instDelaySlot, bb, position, nbInstructionsA
joutees, chaineAnnulBit);
appelDeFonctionInstMilieu(bb, position, nbInstructionsAjoutees, chai
neAnnulBit);
// On traite les écritures de l’instruction se trouvant dans le Dela
ySlot du branchement
appelDeFonctionsSorties(instDelaySlot, bb, position, nbInstructionsA
joutees, chaineAnnulBit);
// On traite la fin de l’instruction qui se trouve dans le DelaySlot
appelDeFonctionInstFin(bb, position, nbInstructionsAjoutees, chaineA
nnulBit);
appelDeFonctionEchangerInstDelay(bb, position, nbInstructionsAjoutees);
// Si l’instruction est un call externe, on lui ajoute comme entrées et
sorties les paramètres consommés
// et produits par cette fonction
if(typeInstruction(inst) == T_APPEL_EXTERNE || typeInstruction(inst) ==
T_APPEL_EXTERNE_SPECIAL)
Imprimé par Benjamin Vidal
03 jun 03 16:11 instrumentation.cc Page 18/23
{
switch (inst−>numberOfAttributes(COMMENT_ATT))
{
case 1 :
appelDeFonctionsEntreesAppelExterne(inst, bb, position, nbInstruct
ionsAjoutees);
break;
case 2 :
appelDeFonctionsEntreesAppelExterne(inst, bb, position, nbInstruct
ionsAjoutees);
appelDeFonctionsSortiesAppelExterne(inst, bb, position, nbInstruct
ionsAjoutees);
break;
default :
fprintf(STDERR,"Passage impossible : fonction instrumenter dans instrumentation.ccn");
}
}
// On traite la fin de l’instruction de branchement seulment si on n’a p
as à faire à un appel externe interceptées par les
// fonctions redéfinies dans redefinition.c
if(typeInstruction(inst)!=T_APPEL_EXTERNE) appelDeFonctionInstFin(bb, po
sition, nbInstructionsAjoutees, NULL);
appelDeFonctionEchangerInstDelay(bb, position, nbInstructionsAjoutees);
restaurationContexte(bb, position, nbInstructionsAjoutees);
}
// Si l’instruction se trouve dans un DelaySlot, on remet le flag correspondan
t à 0
else flagDelaySlot = 0;
}
void ajouterCommentaireAppelExterne(INST *inst)
{
int i,j;
char etiquette[100], ligneCourante[200];
regex_t *preg_fct = new regex_t();
regex_t *preg_etiquette = new regex_t();
regex_t *preg_params = new regex_t();
regex_t *preg_result = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch[nmatch];
regmatch_t pmatch_params[nmatch];
regmatch_t pmatch_result[nmatch];
// Compilation de l’expression régulière permettant de détecter si une instruc
tion est une fonction
if (regcomp(preg_fct, EXP_FONCTION, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_FONCTION""n");
exit(4);
}
regexec(preg_fct, inst−>unparse(), nmatch, pmatch, 0);
// On récupère dans la chaine etiquette l’étiquette associée au call traité
for(i=0,j=pmatch[0].rm_eo; j<strlen(inst−>unparse()); j++)
mercredi 18 juin 2003 instrumentation.cc 10/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-70-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 19/23
if((inst−>unparse())[j]!=’ ’ && (inst−>unparse())[j]!=’t’) etiquette[i++]=(i
nst−>unparse())[j];
etiquette[i] = ’0’;
if (regcomp(preg_etiquette, etiquette, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière "%s"n",etiquette);
exit(4);
}
if (regcomp(preg_params, "[ ]+! params =[ ]+", REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière "[ t]+! params =[ t]+"n");
exit(4);
}
if (regcomp(preg_result, "[ ]+! Result =[ ]+", REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière "[ t]+! Result =[ t]+"n");
exit(4);
}
// On cherche, dans le fichier assembleur original, la ligne contenant l’appel
à la fonction traitée
do
{
char c;
i=0;
do
{
c = fgetc(fichierSOriginal);
ligneCourante[i++] = c;
}
while(c != ’n’);
ligneCourante[i] = ’0’;
}
while (regexec(preg_fct, ligneCourante, nmatch, pmatch, 0) == REG_NOMATCH ||
regexec(preg_etiquette, ligneCourante, nmatch, pmatch, 0) == REG_NOMATC
H ||
regexec(preg_params, ligneCourante, nmatch, pmatch_params, 0) == REG_NO
MATCH ||
regexec(preg_result, ligneCourante, nmatch, pmatch_result, 0) == REG_NO
MATCH ||
feof(fichierSOriginal));
regfree(preg_fct);
regfree(preg_etiquette);
regfree(preg_params);
regfree(preg_result);
if(feof(fichierSOriginal))
{
fprintf(STDERR,"Erreur : fin du fichier .s original atteinte ");
fprintf(STDERR,"(fonction ajouterCommentaireAppelExterne dans instrumentation.cc)n");
exit(7);
}
// Ici, la variable ligneCourante contient la ligne du fichier assembleur corr
espondant à l’appel
// de la fonction traitée (qui contient donc aussi en commentaire les paramètr
es de cette fonction)
char liste[100],*tmp;
03 jun 03 16:11 instrumentation.cc Page 20/23
// On récupère la liste des paramètres d’entrée
for(i=0,j=pmatch_params[0].rm_eo; j<pmatch_result[0].rm_so; j++) liste[i++]=li
gneCourante[j];
liste[i] = ’0’;
// Puis on la range dans les attributs à mettre en commentaire dans le fichier
généré
// NOTE : ces commentaires servent aussi par la suite à identifier quels sont
les accès fait par la fonction externe
tmp = (char *)malloc((strlen(liste)+1)*sizeof(char));
strcpy(tmp,liste);
inst−>addAttribute(COMMENT_ATT, tmp, strlen(liste)+1);
// On récupère la liste contenant le résultat (paramètre de sortie)
for(i=0,j=pmatch_result[0].rm_eo; ligneCourante[j]!=’!’ &&
ligneCourante[j]!=’ ’ &&
ligneCourante[j]!=’t’ &&
ligneCourante[j]!=’n’; j++) liste[i++]=lign
eCourante[j];
liste[i] = ’0’;
// Puis, si la chaine n’est pas vide, on la range dans les attributs à mettre
en commentaire dans le fichier généré
// NOTE : ces commentaires servent aussi par la suite à identifier quels sont
les accès fait par la fonction externe
if(liste[0] != ’0’)
{
tmp = (char *)malloc((strlen(liste)+1)*sizeof(char));
strcpy(tmp,liste);
inst−>addAttribute(COMMENT_ATT, tmp, strlen(tmp)+1);
}
}
void Salto_hook()
{
CFG *proc;
BB *bb,*bbSuivant;
INST *inst;
int numeroInst;
unsigned int nbInstructionsAjoutees;
// Parcours du programme permettant de récupérer les paramètres des fonctions
définies à
// l’extérieur des fichiers .s locaux
for (int i=0; i < numberOfCFG(); i++)
{
proc = getCFG(i);
for (int j=0; j < proc−>numberOfBB(); j++)
{
bb = proc−>getBB(j);
for (int k=0; k < bb−>numberOfAsm(); k++)
{
inst = bb−>getAsm(k);
if(typeInstruction(inst) == T_APPEL_EXTERNE ||
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation.cc 11/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-71-320.jpg)
![03 jun 03 16:11 instrumentation.cc Page 21/23
typeInstruction(inst) == T_APPEL_EXTERNE_SPECIAL) ajouterCommentaireA
ppelExterne(inst);
}
}
}
// Parcours du programme permettant d’insérer le code d’instrumentation des in
structions
numeroInst = 0;
for (int i=0; i < numberOfCFG(); i++)
{
proc = getCFG(i);
for (int j=0; j < proc−>numberOfBB(); j++)
{
bb = proc−>getBB(j);
bbSuivant = proc−>getBB(j+1);
int nbAsm = bb−>numberOfAsm();
nbInstructionsAjoutees = 0;
for (int k=0; k < nbAsm; k++)
{
numeroInst++;
inst = bb−>getAsm(k+nbInstructionsAjoutees);
instrumenter(inst, bb, bbSuivant, k, &nbInstructionsAjoutees, numeroInst
);
}
}
}
// Parcours du programme permettant d’insérer le code pour l’initialisation de
s variables globales
// et d’affichage de ces variables en fin d’exécution du programme.
for (int i=0; i < numberOfCFG(); i++)
{
proc = getCFG(i);
if(!strcmp(proc−>getName(),"main"))
{
// Insertion d’un appel à la procédure initialisant les variables globales
(proc−>getBB(0))−>insertAsm(0, newAsm("call initVariablesGlobales"));
(proc−>getBB(0))−>insertAsm(1, newAsm(NOP));
for (int j=0; j < proc−>numberOfBB(); j++)
{
bb = proc−>getBB(j);
for (int k=0; k < bb−>numberOfAsm(); k++)
{
inst = bb−>getAsm(k);
// Insertion d’un appel à la procédure d’affichage des structures de d
onnées juste avant l’instruction "call exit"
if(estPresent("call",inst−>unparse()) && estPresent("exit",inst−>unparse(
)))
{
bb−>insertAsm(k, newAsm("call afficherSdd"));
bb−>insertAsm(k+1, newAsm(NOP));
break;
}
}
}
break;
}
}
// Envoi du code instrumenté vers la sortie standard
produceCode(fichierSInstrumente);
}
void Salto_init_hook(int argc, char *argv[])
{
int i,j,k;
char nomFichierSortie[100];
Imprimé par Benjamin Vidal
// Récupération dans la ligne de commande entrée par l’utilisateur du nom du f
ichier original
for(i=1; i<argc && !estPresent("−i",argv[i]); i++);
if(i == argc−1)
{
fprintf(STDERR,"Erreur, votre ligne de commande ne comporte pas l’option "−i"n");
exit(6);
}
// On ouvre le fichier .s original à traiter pour pouvoir s’en servir dans sal
to_hook()
fichierSOriginal = fopen(argv[i+1],"r");
if(fichierSOriginal == NULL)
{
fprintf(STDERR,"Problème lors de l’ouverture du fichier "%s" ",argv[i+1]);
fprintf(STDERR,"(fonction Salto_init_hook dans le fichier instrumentation.cc)n");
exit(11);
}
nomFichierSortie[0]=’0’;
strcat(nomFichierSortie,REPERTOIRE_FICHIER_INSTRUMENTES);
strcat(nomFichierSortie,argv[i+1]);
// On ouvre le fichier .s instrumenté en écriture à traiter pour pouvoir s’en
servir dans salto_hook()
fichierSInstrumente = fopen(nomFichierSortie,"w");
if(fichierSInstrumente == NULL)
{
fprintf(STDERR,"Problème lors de l’ouverture du fichier "%s" ",nomFichierSortie);
fprintf(STDERR,"(fonction Salto_init_hook dans le fichier instrumentation2.cc)n");
exit(11);
}
// Recherche de l’expression "−−" dans la ligne de commande
for(; i<argc && !estPresent("−−",argv[i]); i++);
// Si cette expression n’est pas présente, on ne numérote pas les fichiers
if(i == argc−1) numeroFichier = 0;
else numeroFichier=atoi(argv[i+1]);
}
03 jun 03 16:11 instrumentation.cc Page 22/23
mercredi 18 juin 2003 instrumentation.cc 12/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-72-320.jpg)


![18 jun 03 17:55 instrument.c Page 1/13
#include <stdio.h>
#include <stdlib.h>
#include "instrument.h"
#define NB_REGISTRES 115
#define NB_REGISTRES_TOURNANTS 100000
/* MAX_NB_OPERANDES doit etre égal au maximum d’opérandes que peuvent avoir les
instruction +1 ! */
#define MAX_NB_OPERANDES 150
/* Défini les différentes valeur que peuvent prendre les variables utiliteInst[i
], i allant de 0 à MAX_NB_INST_DYNAMIQUE.*/
#define INUTILE 0
#define UTILE 1
#define NOP 2
#define GENERER_FICHIER_DOT 1
#define FICHIER_TRACE_DOT "graphe_dependances.dot"
#define MAX_NB_INST_STATIQUES 11000
#define MAX_INST_STATIQUES_TOTAL 250000
#define NB_FICHIERS 15
typedef unsigned char flag;
typedef struct instru {
unsigned char numeroFichier;
unsigned int numeroStatique;
unsigned int numeroDynamique;
flag typeInstruction;
struct instru *origineOperandes[MAX_NB_OPERANDES];
struct instru *precedent;
} instruction;
typedef struct mem {
int adresse;
unsigned int nbLecture;
instruction *derniereEcriture;
struct mem *suivant;
} elementMemoire;
/* Définition des registres généraux */
instruction *tableRegistres[NB_REGISTRES];
unsigned int tableLectureRegistres[NB_REGISTRES];
/* Définition des registres tournants */
instruction *tableRegistresTournants[NB_REGISTRES_TOURNANTS];
unsigned int tableLectureRegistresTournants[NB_REGISTRES_TOURNANTS];
unsigned int niveauFenetreRegistre = 0;
/* Définition des zones mémoires (point d’entrée dans la liste chainée) */
elementMemoire *adresseInitiale = NULL;
/* Définition des instructions (point d’entrée dans la liste chainée et tableau
18 jun 03 17:55 instrument.c Page 2/13
de flag) */
flag utiliteInst[MAX_NB_INST_DYNAMIQUE];
flag valeursMortes[MAX_NB_INST_DYNAMIQUE];
instruction *instInitiale;
instruction *instCourante = NULL;
instruction *instCouranteDelay = NULL;
unsigned int occurencesInutileInstStatiques[MAX_NB_INST_STATIQUES][NB_FICHIERS];
unsigned int occurencesInstStatiques[MAX_NB_INST_STATIQUES][NB_FICHIERS];
unsigned int allocation=0;
/* Utile uniquement pour la version donnant la proportion d’instruction statique
s inutiles */
int cptInstStatiquesTraitees;
void initVariablesGlobales(void)
{
int i,j;
/* Création d’une instruction initiale fictive sur laquelle vont pointer celle
s qui
utilisent des registres déjà initialisés lors du lancement du programme */
instInitiale = malloc(sizeof(instruction));
allocation++;
if(instInitiale == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction initVariablesGlobales dans le fichier instrument.c)n");
exit(10);
}
instInitiale−>numeroStatique = 0;
instInitiale−>numeroDynamique = 0;
instInitiale−>numeroFichier = 0;
for(i=0; i<MAX_NB_OPERANDES; i++) instInitiale−>origineOperandes[i] = NULL;
instInitiale−>typeInstruction = T_AUTRE;
instInitiale−>precedent = NULL;
instCourante = instInitiale;
for(i=0; i<NB_REGISTRES; i++)
{
tableRegistres[i] = instInitiale;
tableLectureRegistres[i] = 0;
}
for(i=0; i<NB_REGISTRES_TOURNANTS; i++)
{
tableRegistresTournants[i] = instInitiale;
tableLectureRegistresTournants[i] = 0;
}
for(i=0; i<MAX_NB_INST_DYNAMIQUE; i++)
{
utiliteInst[i] = INUTILE;
valeursMortes[i] = 0;
}
for(i=0; i<MAX_NB_INST_STATIQUES; i++)
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument.c 15/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-75-320.jpg)
![18 jun 03 17:55 instrument.c Page 3/13
for(j=0; j<NB_FICHIERS; j++)
{
occurencesInstStatiques[i][j]=0;
occurencesInutileInstStatiques[i][j]=0;
}
}
void remonterArbre(instruction *inst)
{
int i;
/* Si on n’a pas encore parcouru l’arbre de dépendance de l’instuction inst,
on le parcours pour pour positionner les flag d’utilité utiliteInst[inst−>n
umeroDynamique] */
if(utiliteInst[inst−>numeroDynamique]!=UTILE)
{
utiliteInst[inst−>numeroDynamique] = UTILE;
for(i=0; inst−>origineOperandes[i]!=NULL; i++) remonterArbre(inst−>origineOp
erandes[i]);
}
}
insert(float *tableauInstStatiqueInutiles, float valeur)
{
int i,j,k;
for(i=0; tableauInstStatiqueInutiles[i]>valeur; i++);
for(k=cptInstStatiquesTraitees; k!=i; k−−) tableauInstStatiqueInutiles[k]=tabl
eauInstStatiqueInutiles[k−1];
tableauInstStatiqueInutiles[i] = valeur;
cptInstStatiquesTraitees++;
}
/* Fonction de debug permettant d’afficher la liste chainée des instructions,
la table des registres et enfin le pourcentage d’instructions utile et inutil
es */
void afficherSdd(void)
{
instruction *i;
elementMemoire *a;
int j,k,cptUtile=0,cptInutile=0,cptNop=0,cptInstStatique=0,cptInstStatiqueOccu
rencesInutile=0,
cptLoadInutile=0,cptLoad=0,cptStoreInutile=0,cptStore=0,cptMortes=0,nbTotalIns
tructions;
unsigned int instInutileArtificiel;
float tableauInstStatiqueInutiles[MAX_INST_STATIQUES_TOTAL];
/* Définition du fichier contenant la trace (numéro) des instructions inutiles
) */
FILE *traceInstructionsInutiles = fopen(TRACE_INSTRUCTIONS_INUTILES,"w");
FILE *traceInstructionsStatiquesInutiles = fopen(TRACE_INSTRUCTIONS_STATIQUES_
INUTILES,"w");
FILE *fichierEvolutionQtValeursMortes = fopen(TRACE_VALEURS_MORTES,"w");
FILE *fichierDot;
if(GENERER_FICHIER_DOT)
{
18 jun 03 17:55 instrument.c Page 4/13
fichierDot = fopen(FICHIER_TRACE_DOT,"w");
if(fichierDot==NULL)
{
fprintf(stderr,"Problème lors de l’ouverture du fichier ""FICHIER_TRACE_DOT"" ");
fprintf(stderr,"(fonction afficherSdd dans le fichier instrument.c)n");
exit(11);
}
fprintf(fichierDot,"digraph G {n");
}
if(traceInstructionsInutiles==NULL)
{
fprintf(stderr,"Problème lors de l’ouverture du fichier ""TRACE_INSTRUCTIONS_INUTILES"" "
);
fprintf(stderr,"(fonction afficherSdd dans le fichier instrument.c)n");
exit(11);
}
/* Affichage des dépendances entre les instructions dynamiques
(stockées dans la liste chainée d’instructions dynamiques) */
for(i=instCourante; i!=NULL; i=i−>precedent)
{
if(GENERER_FICHIER_DOT && utiliteInst[i−>numeroDynamique]!=NOP)
{
if(utiliteInst[i−>numeroDynamique]==INUTILE)
fprintf(fichierDot,"t%d [color=".0 .0 .8",fontcolor=".0 .0 .8"];n", i−>numeroDynamiq
ue);
}
fprintf(stdout,"I.Dynamic %dt−− I.Static %dt−− File %d",i−>numeroDynamique,i−>numeroS
tatique,i−>numeroFichier);
if(utiliteInst[i−>numeroDynamique]==UTILE) fprintf(stdout,"t−− utile");
else if(utiliteInst[i−>numeroDynamique]==INUTILE) fprintf(stdout,"t−− INUTILE
");
else if(utiliteInst[i−>numeroDynamique]==NOP) fprintf(stdout,"t−− nop");
if(i−>origineOperandes[0]!=NULL)
{
fprintf(stdout,"t−− Dépend de %d",(i−>origineOperandes[0])−>numeroDynamique)
;
if(GENERER_FICHIER_DOT && utiliteInst[i−>numeroDynamique]!=NOP)
{
fprintf(fichierDot,"t%d −> %d", i−>numeroDynamique, (i−>origineOperandes
[0])−>numeroDynamique);
if(utiliteInst[i−>numeroDynamique]==INUTILE) fprintf(fichierDot," [color=".
0 .0 .8"]");
fprintf(fichierDot,";n");
}
}
for(j=1; j<MAX_NB_OPERANDES; j++)
if(i−>origineOperandes[j]!=NULL)
{
fprintf(stdout,",%d",(i−>origineOperandes[j])−>numeroDynamique);
if(GENERER_FICHIER_DOT && utiliteInst[i−>numeroDynamique]!=NOP)
{
fprintf(fichierDot,"t%d −> %d", i−>numeroDynamique, (i−>origineOperand
es[j])−>numeroDynamique);
if(utiliteInst[i−>numeroDynamique]==INUTILE) fprintf(fichierDot," [color
=".0 .0 .8"]");
fprintf(fichierDot,";n");
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument.c 16/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-76-320.jpg)
![18 jun 03 17:55 instrument.c Page 5/13
}
}
fprintf(stdout,"n");
if(utiliteInst[i−>numeroDynamique]==INUTILE)
{
/* Ecriture dans le fichier traceInstructionsInutiles du numéro des instru
ctions dynamiques inutiles */
fprintf(traceInstructionsInutiles,"%un",i−>numeroDynamique);
occurencesInutileInstStatiques[i−>numeroStatique][i−>numeroFichier]++;
}
occurencesInstStatiques[i−>numeroStatique][i−>numeroFichier]++;
switch (i−>typeInstruction)
{
case T_LOAD :
cptLoad++;
if(utiliteInst[i−>numeroDynamique]==INUTILE) cptLoadInutile++;
break;
case T_STORE :
cptStore++;
if(utiliteInst[i−>numeroDynamique]==INUTILE) cptStoreInutile++;
}
}
fclose(traceInstructionsInutiles);
if(GENERER_FICHIER_DOT)
{
fprintf(fichierDot,"}");
fclose(fichierDot);
}
/* Affichage de la table des registres fixes avec les informations qui lui son
t relatives */
fprintf(stdout,"nTable des registres fixes :n");
for(j=0; j<NB_REGISTRES; j++)
{
if(tableRegistres[j]−>numeroDynamique != 0 || tableLectureRegistres[j] != 0)
{
fprintf(stdout,"Registre numéro %dt",j);
fprintf(stdout,": Modifié par l’instruction %dt",tableRegistres[j]−>numeroDynamique)
;
fprintf(stdout,"et lu depuis par %d instruction(s)n",tableLectureRegistres[j]);
}
}
/* Affichage de la table des registres tournants avec les informations qui lui
sont relatives */
fprintf(stdout,"nTable des registres tournants (niveau actuel : %d) :n",niveauFenetreRegistre);
for(j=0; j<NB_REGISTRES_TOURNANTS; j++)
{
if(tableRegistresTournants[j]−>numeroDynamique != 0 || tableLectureRegistres
Tournants[j] != 0)
{
fprintf(stdout,"Registre tournant numéro %dt",j);
fprintf(stdout,": Modifié par l’instruction %dt",tableRegistresTournants[j]−>numeroD
ynamique);
fprintf(stdout,"et lu depuis par %d instruction(s)n",tableLectureRegistresTournants[j
Imprimé par Benjamin Vidal
18 jun 03 17:55 instrument.c Page 6/13
]);
}
}
/* Affichage de la liste chainée contenant les adresses mémoire */
fprintf(stdout,"nListe des adresses mémoires :n");
for(a=adresseInitiale; a!=NULL; a=a−>suivant)
{
fprintf(stdout,"Adresse mémoire %dt",a−>adresse);
fprintf(stdout,": Modifié par l’instruction %dt",a−>derniereEcriture−>numeroDynamique)
;
fprintf(stdout,"et lu depuis par %d instruction(s)n",a−>nbLecture);
}
/* On compte le nombre d’instructions utiles et inutiles afin de l’afficher */
for(j=0; j<instCourante−>numeroDynamique; j++)
{
switch (utiliteInst[j])
{
case UTILE : cptUtile++; break;
case INUTILE : cptInutile++; break;
case NOP : cptNop++; break;
default : fprintf(stderr,"Passage impossible : fonction afficherSdd dans instrument.cn"
);
}
if(valeursMortes[j] == 0) cptMortes++;
if(valeursMortes[j] == 0 && utiliteInst[j] != INUTILE)
{
fprintf(stderr,"Instruction %d !!!!n",j);
}
if(j%20 == 0) fprintf(fichierEvolutionQtValeursMortes,"%dt%dn",j,cptMortes)
;
}
fclose(fichierEvolutionQtValeursMortes);
nbTotalInstructions = instCourante−>numeroDynamique;
fprintf(stdout,"nCalcul prenant en compte les "nop" :n");
fprintf(stdout,"Nombre d’instructions inutiles : %d/%d soit %f %%n",
cptInutile,nbTotalInstructions,(float)(cptInutile*100)/(float)nbTotalInstructi
ons);
fprintf(stdout,"Nombre d’instructions utiles : %d/%d soit %f %%n",
cptUtile,nbTotalInstructions,(float)(cptUtile*100)/(float)nbTotalInstructions)
;
fprintf(stdout,"Nombre de nop : %d/%d soit %f %%nn",
cptNop,nbTotalInstructions,(float)(cptNop*100)/(float)nbTotalInstructions);
nbTotalInstructions = instCourante−>numeroDynamique − cptNop;
fprintf(stdout,"nCalcul ne prenant pas en compte les "nop" :n");
fprintf(stdout,"Nombre d’instructions inutiles : %d/%d soit %f %%n",
cptInutile,nbTotalInstructions,(float)(cptInutile*100)/(float)nbTotalInstructi
ons);
fprintf(stdout,"Nombre d’instructions utiles : %d/%d soit %f %%nn",
cptUtile,nbTotalInstructions,(float)(cptUtile*100)/(float)nbTotalInstructions)
;
fprintf(stdout,"Nombre d’instructions dont le résultat est mort : %d/%d soit %f %%nn",
cptMortes,nbTotalInstructions,(float)(cptMortes*100)/(float)nbTotalInstruction
s);
fprintf(stdout,"nnNombre d’ocurences d’instructions inutiles pour une instruction statique : n");
mercredi 18 juin 2003 instrument.c 17/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-77-320.jpg)
![18 jun 03 17:55 instrument.c Page 7/13
tableauInstStatiqueInutiles[0] = 0.0;
/* Lignes de la matrice */
for(k=0; k<MAX_NB_INST_STATIQUES; k++)
{
if(k==0)
for(j=1; j<NB_FICHIERS; j++)
fprintf(stdout," t%d",j);
else
{
fprintf(stdout,"n%d :t",k);
/* Colonnes de la matrice */
for(j=1; j<NB_FICHIERS; j++)
{
if(occurencesInstStatiques[k][j]!=0)
{
fprintf(stdout,"%u/%ut",occurencesInutileInstStatiques[k][j],occurence
sInstStatiques[k][j]);
cptInstStatique++;
if(occurencesInutileInstStatiques[k][j]!=0) cptInstStatiqueOccurencesI
nutile++;
insert(tableauInstStatiqueInutiles,(float)occurencesInutileInstStatiqu
es[k][j]/(float)occurencesInstStatiques[k][j]);
}
else fprintf(stdout," t");
}
}
}
for(j=0; j<cptInstStatiquesTraitees; j++)
fprintf(traceInstructionsStatiquesInutiles,"%dt%fn",cptInstStatiquesTraitee
s,tableauInstStatiqueInutiles[j]);
fclose(traceInstructionsStatiquesInutiles);
fprintf(stdout,"nNombre d’instructions statique ayant des occurences inutiles / Nombre d’instructions stati
ques utilisées : %d/%d soit %f %%n",
cptInstStatiqueOccurencesInutile, cptInstStatique, (float)(cptInstStatiqueOccu
rencesInutile*100)/(float)cptInstStatique);
fprintf(stdout,"nNombre de load inutiles / Nombre de load dynamique total : %d/%d soit %f %%n",
cptLoadInutile,cptLoad,(float)(cptLoadInutile*100)/(float)cptLoad);
fprintf(stdout,"nNombre de store inutiles / Nombre de store dynamique total : %d/%d soit %f %%n",
cptStoreInutile,cptStore,(float)(cptStoreInutile*100)/(float)cptStore);
fprintf(stdout,"Nombre de noeuds total dans le graphe : %dn",allocation);
}
/* Création de la représentation des instructions dynamiques en mémoire */
/* !!!!! Attention, cette fonction est différente selon qu’on utilise le program
me sur Sparc ou x86 (DelaySlot) */
void instrumentationInstructionDebut(int typeInstruction, int numeroInst, int nu
meroFichier)
{
int i;
instruction *tmp = malloc(sizeof(instruction));
Imprimé par Benjamin Vidal
18 jun 03 17:55 instrument.c Page 8/13
allocation++;
if(tmp == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction instrumentationInstructionDebut dans le fichier instrument.c)n");
exit(10);
}
if(instCourante−>numeroDynamique >= MAX_NB_INST_DYNAMIQUE)
{
fprintf(stderr,"Nombre maximum d’instruction dépassé, veulliez augmenter la valeur de la constante ")
;
fprintf(stderr,"MAX_NB_INST_DYNAMIQUE dans le fichier instrument.cn");
exit(1);
}
tmp−>numeroStatique = numeroInst;
tmp−>numeroFichier = numeroFichier;
tmp−>typeInstruction = typeInstruction;
/* On passe pour la première fois dans cette fonction */
if(instCourante == NULL)
{
tmp−>numeroDynamique = 1;
tmp−>precedent = instInitiale;
}
else
{
tmp−>numeroDynamique = instCourante−>numeroDynamique+1;
tmp−>precedent = instCourante;
}
for(i=0; i<MAX_NB_OPERANDES; i++) tmp−>origineOperandes[i] = NULL;
instCourante = tmp;
/*fprintf(stderr,"Début statique %d dynamique %d fichier %d >",numeroInst,tmp−
>numeroDynamique,tmp−>numeroFichier);*/
}
/* !!!!! Attention, cette fonction n’est utile que pour les machines utilisant u
n DelaySolt (Sparc) */
void instrumentationInstructionMilieu(void)
{
/* Si l’instruction est un save, on incrémente le niveau de la fenetre de regi
stres */
if(instCourante−>typeInstruction == T_SAVE) niveauFenetreRegistre++;
/* Si c’est un restore, on décrémente le niveau de la fenetre de registres */
else if(instCourante−>typeInstruction == T_RESTORE) niveauFenetreRegistre−−;
}
void instrumentationInstructionFin(void)
{
/* Si l’instruction courante est un branchement quelconque, un save ou un rest
ore, on la marque comme utile
et on marque comme utile toute les instructions dont elle dépend (appel réc
ursif à remonterArbre) */
if(instCourante−>typeInstruction == T_BRANCHEMENT ||
instCourante−>typeInstruction == T_BRANCHEMENT_ANNUL_BIT ||
mercredi 18 juin 2003 instrument.c 18/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-78-320.jpg)
![18 jun 03 17:55 instrument.c Page 9/13
instCourante−>typeInstruction == T_SAVE ||
instCourante−>typeInstruction == T_RESTORE ||
instCourante−>typeInstruction == T_APPEL_INTERNE ||
instCourante−>typeInstruction == T_APPEL_EXTERNE ||
instCourante−>typeInstruction == T_APPEL_EXTERNE_SPECIAL) remonterArbre(ins
tCourante);
if(instCourante−>typeInstruction == T_NOP) utiliteInst[instCourante−>numeroDyn
amique] = NOP;
/*fprintf(stderr,"< Fin statique %d dynamique %d fichier %dn",instCourante−>n
umeroStatique,instCourante−>numeroDynamique,instCourante−>numeroFichier);*/
}
/* !!!!! Attention, cette fonction n’est utile que pour les machines utilisant u
n DelaySolt (Sparc) */
void copierInstDelay(void)
{
instCouranteDelay = instCourante;
}
/* !!!!! Attention, cette fonction n’est utile que pour les machines utilisant u
n DelaySolt (Sparc) */
void echangerInstDelay(void)
{
instruction *tmp = instCourante;
instCourante = instCouranteDelay;
instCouranteDelay = tmp;
}
/* Traitement fait lorsqu’on rencontre une instruction qui accède à la mémoire o
u à des registres (en entrée) */
/* !!!!! Attention, cette fonction est différente selon qu’on utilise le program
me sur Sparc ou x86 (registres) */
void instrumentationEntreeRegistre(int identificateurRessource)
{
int i;
unsigned int identificateurRegistreTournant;
/* identificateurRessource numéro ID_REG_SALTO_G = trou noir (%g0) */
if(identificateurRessource != ID_REG_SALTO_G)
{
/* Si le registre accédé fait partie de la fenêtre de registres tournante */
if(identificateurRessource>=ID_REG_SALTO_O && identificateurRessource<=ID_RE
G_SALTO_I+7)
{
identificateurRegistreTournant = (72−identificateurRessource)+(niveauFenet
reRegistre*OFFSET_FENETRE);
if(identificateurRegistreTournant>=NB_REGISTRES_TOURNANTS)
{
fprintf(stderr,"Nombre maximum de registres tournants dépassé, veulliez augmenter la valeur de
");
fprintf(stderr,"la constante NB_REGISTRES_TOURNANTS dans le fichier instrument.cn");
exit(1);
}
tableLectureRegistresTournants[identificateurRegistreTournant]++;
Imprimé par Benjamin Vidal
18 jun 03 17:55 instrument.c Page 10/13
for(i=0; (instCourante−>origineOperandes)[i]!=NULL; i++)
if (i >= MAX_NB_OPERANDES)
{
fprintf(stderr,"Nombre maximum d’opérandes pour une instruction dépassé, veulliez augmente
r la valeur de ");
fprintf(stderr,"la constante MAX_NB_OPERANDES dans le fichier instrument.cn");
exit(8);
}
instCourante−>origineOperandes[i] = tableRegistresTournants[identificateur
RegistreTournant];
}
/* Sinon, on le considère comme un registre fixe */
else
{
tableLectureRegistres[identificateurRessource]++;
for(i=0; (instCourante−>origineOperandes)[i]!=NULL; i++)
if (i >= MAX_NB_OPERANDES)
{
fprintf(stderr,"Nombre maximum d’opérandes pour une instruction dépassé, veulliez augmente
r la valeur de ");
fprintf(stderr,"la constante MAX_NB_OPERANDES dans le fichier instrument.cn");
exit(8);
}
instCourante−>origineOperandes[i] = tableRegistres[identificateurRessource
];
}
}
}
/* Traitement fait lorsqu’on rencontre une instruction qui accède à la mémoire o
u à des registres (en sortie) */
/* !!!!! Attention, cette fonction est différente selon qu’on utilise le program
me sur Sparc ou x86 (registre %g0) */
void instrumentationSortieRegistre(int identificateurRessource)
{
unsigned int identificateurRegistreTournant;
/* Mise à jour du compteur de résultat : le registre identificateurRessource e
st considéré comme un résultat
de l’instruction instCourante */
valeursMortes[instCourante−>numeroDynamique]++;
/* Si le registre dans lequel on écrit est le numéro 41 (correspondant à %g0),
on n’en tient pas compte car ce
registre est un trou noir (quelque soit ce qui y est écrit, on lit toujours
la valeur 0 dans ce registre) */
if(identificateurRessource != ID_REG_SALTO_G)
{
/* Si le registre accédé fait partie de la fenêtre de registres tournante */
if(identificateurRessource>=ID_REG_SALTO_O && identificateurRessource<=ID_RE
G_SALTO_I+7)
{
identificateurRegistreTournant = (72−identificateurRessource)+(niveauFenet
reRegistre*OFFSET_FENETRE);
if(identificateurRegistreTournant>=NB_REGISTRES_TOURNANTS)
{
fprintf(stderr,"Nombre maximum de registres tournants dépassé, veulliez augmenter la valeur de
mercredi 18 juin 2003 instrument.c 19/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-79-320.jpg)
![18 jun 03 17:55 instrument.c Page 11/13
");
fprintf(stderr,"la constante NB_REGISTRES_TOURNANTS dans le fichier instrument.cn");
exit(1);
}
if(tableLectureRegistresTournants[identificateurRegistreTournant] == 0)
valeursMortes[(tableRegistresTournants[identificateurRegistreTournant])−
>numeroDynamique]−−;
tableRegistresTournants[identificateurRegistreTournant] = instCourante;
tableLectureRegistresTournants[identificateurRegistreTournant] = 0;
}
/* Sinon, on le considère comme un registre fixe */
else
{
if(tableLectureRegistres[identificateurRessource] == 0)
valeursMortes[(tableRegistres[identificateurRessource])−>numeroDynamique
]−−;
tableRegistres[identificateurRessource] = instCourante;
tableLectureRegistres[identificateurRessource] = 0;
}
}
}
void lectureMemoireOctet(int adresseMemoire)
{
int i;
elementMemoire *a;
for(a=adresseInitiale; a==NULL || adresseMemoire>a−>adresse; a=a−>suivant)
if(a==NULL)
{
/*fprintf(stderr,"Accès à l’adresse mémoire non initialisée %d par l’instr
uction %d (fichier %d)n",
adresseMemoire, instCourante−>numeroStatique, instCourante−>numeroFichier)
;*/
return;
}
if(adresseMemoire != a−>adresse)
{
/*fprintf(stderr,"Accès à l’adresse mémoire non initialisée %d par l’instruc
tion %d (fichier %d)n",
adresseMemoire, instCourante−>numeroStatique, instCourante−>numeroFichier);*
/
return;
}
for(i=0; (instCourante−>origineOperandes)[i]!=NULL; i++)
if (i >= MAX_NB_OPERANDES)
{
fprintf(stderr,"Nombre maximum d’opérandes pour une instruction dépassé, veulliez augmenter la va
leur de ");
fprintf(stderr,"la constante MAX_NB_OPERANDES dans le fichier instrument.cn");
exit(8);
}
instCourante−>origineOperandes[i] = a−>derniereEcriture;
a−>nbLecture++;
}
18 jun 03 17:55 instrument.c Page 12/13
void instrumentationEntreeMemoire(int adresseMemoire, int nbOctetsLus)
{
int offset;
for(offset=0; offset<nbOctetsLus; offset++) lectureMemoireOctet(adresseMemoire
+offset);
}
void ecritureMemoireOctet(int adresseMemoire)
{
elementMemoire *nouveau, *tmp = adresseInitiale;
/* Mise à jour du compteur de résultat : la case mémoire adresseMemoire est co
nsidéré comme un résultat
de l’instruction instCourante */
valeursMortes[instCourante−>numeroDynamique]++;
/* Cas ou la liste chainée est vide : premier accès en écriture à la mémoire *
/
if(adresseInitiale == NULL)
{
adresseInitiale = malloc(sizeof(elementMemoire));
if(adresseInitiale == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction ecritureMemoireOctet dans le fichier instrument.c)n");
exit(10);
}
adresseInitiale−>adresse = adresseMemoire;
adresseInitiale−>nbLecture = 0;
adresseInitiale−>derniereEcriture = instCourante;
adresseInitiale−>suivant = NULL;
}
else
{
/* Cas ou l’insertion de données concerne le premier élément de la liste cha
inée */
if(adresseMemoire <= adresseInitiale−>adresse)
{
if(adresseInitiale−>adresse == adresseMemoire)
{
if(adresseInitiale−>nbLecture == 0)
valeursMortes[(adresseInitiale−>derniereEcriture)−>numeroDynamique]−−;
adresseInitiale−>nbLecture = 0;
adresseInitiale−>derniereEcriture = instCourante;
}
else
{
nouveau = malloc(sizeof(elementMemoire));
if(nouveau == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction ecritureMemoireOctet dans le fichier instrument.c)n");
exit(10);
}
nouveau−>adresse = adresseMemoire;
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument.c 20/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-80-320.jpg)
![18 jun 03 17:55 instrument.c Page 13/13
nouveau−>nbLecture = 0;
nouveau−>derniereEcriture = instCourante;
nouveau−>suivant = adresseInitiale;
adresseInitiale = nouveau;
}
}
/* Cas général d’insertion d’un élément dans la liste chainée */
else
{
/* On parcours la liste chainée jusqu’a trouver l’endroit ou il faut insér
er la donnée */
while(tmp−>suivant != NULL && adresseMemoire >= tmp−>suivant−>adresse) t
mp = tmp−>suivant;
/* Si l’adresse mémoire à déjà était accédée par le passé, on modifie le p
ointeur sur
l’instruction qui a écrit dernièrement dans cette zone mémoire */
if(tmp−>adresse == adresseMemoire)
{
if(tmp−>nbLecture == 0)
valeursMortes[(tmp−>derniereEcriture)−>numeroDynamique]−−;
tmp−>nbLecture = 0;
tmp−>derniereEcriture = instCourante;
}
/* Sinon, on créé une nouvelle cellule représentant cette zone mémoire et
on l’insère dans la liste chainée */
else
{
nouveau = malloc(sizeof(elementMemoire));
if(nouveau == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction ecritureMemoireOctet dans le fichier instrument.c)n");
exit(10);
}
nouveau−>adresse = adresseMemoire;
nouveau−>nbLecture = 0;
nouveau−>derniereEcriture = instCourante;
nouveau−>suivant = tmp−>suivant;
tmp−>suivant = nouveau;
}
}
}
}
void instrumentationSortieMemoire(int adresseMemoire, int nbOctetsEcrits)
{
int offset;
for(offset=0; offset<nbOctetsEcrits; offset++) ecritureMemoireOctet(adresseMem
oire+offset);
}
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument.c 21/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-81-320.jpg)
![18 jun 03 14:19 instrument_optim.c Page 1/10
#include <stdio.h>
#include <stdlib.h>
#include "instrument.h"
#define NB_REGISTRES 115
#define NB_REGISTRES_TOURNANTS 100000
/* MAX_NB_OPERANDES doit etre égal au maximum d’opérandes que peuvent avoir les
instruction +1 ! */
#define MAX_NB_OPERANDES 1400
/* Défini les différentes valeur que peuvent prendre les variables utiliteInst[i
], i allant de 0 à MAX_NB_INST_DYNAMIQUE.*/
#define INUTILE 0
#define UTILE 1
#define NOP 2
typedef unsigned char flag;
struct donnees_instruction {
unsigned char numeroFichier;
unsigned int numeroStatique;
unsigned int numeroDynamique;
flag typeInstruction;
flag valeurMorte;
struct instru *origineOperandes[MAX_NB_OPERANDES];
};
typedef struct instru {
flag utiliteInst;
struct donnees_instruction *donnees;
struct instru *precedent;
} instruction;
typedef struct mem {
int adresse;
unsigned int nbLecture;
instruction *derniereEcriture;
struct mem *suivant;
} elementMemoire;
/* Définition des registres généraux */
instruction *tableRegistres[NB_REGISTRES];
unsigned int tableLectureRegistres[NB_REGISTRES];
/* Définition des registres tournants */
instruction *tableRegistresTournants[NB_REGISTRES_TOURNANTS];
unsigned int tableLectureRegistresTournants[NB_REGISTRES_TOURNANTS];
unsigned int niveauFenetreRegistre = 0;
/* Définition des zones mémoires (point d’entrée dans la liste chainée) */
elementMemoire *adresseInitiale = NULL;
/* Définition des instructions (point d’entrée dans la liste chainée et tableau
de flag) */
instruction *instInitiale;
instruction *instCourante = NULL;
18 jun 03 14:19 instrument_optim.c Page 2/10
instruction *instCouranteDelay = NULL;
unsigned int numeroDynamiqueCourant;
int cptUtile = 0, cptInutile = 0, cptNop = 0;
unsigned int allocation=0;
void initVariablesGlobales(void)
{
int i;
struct donnees_instruction *donnees = malloc(sizeof(struct donnees_instruction
));
allocation++;
numeroDynamiqueCourant=0;
/* Création d’une instruction initiale fictive sur laquelle vont pointer celle
s qui
utilisent des registres déjà initialisés lors du lancement du programme */
instInitiale = malloc(sizeof(instruction));
if(donnees == NULL || instInitiale == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction initVariablesGlobales dans le fichier instrument.c)n");
exit(10);
}
donnees−>numeroFichier = 0;
donnees−>numeroStatique = 0;
donnees−>numeroDynamique = numeroDynamiqueCourant; /* 0 ici */
donnees−>typeInstruction = T_AUTRE;
donnees−>valeurMorte = 0;
for(i=0; i<MAX_NB_OPERANDES; i++) donnees−>origineOperandes[i] = NULL;
instInitiale−>utiliteInst = INUTILE;
instInitiale−>donnees = donnees;
instInitiale−>precedent = NULL;
instCourante = instInitiale;
for(i=0; i<NB_REGISTRES; i++)
{
tableRegistres[i] = instInitiale;
tableLectureRegistres[i] = 0;
}
for(i=0; i<NB_REGISTRES_TOURNANTS; i++)
{
tableRegistresTournants[i] = instInitiale;
tableLectureRegistresTournants[i] = 0;
}
}
/* Fonction de debug permettant d’afficher la liste chainée des instructions,
la table des registres et enfin le pourcentage d’instructions utile et inutil
es */
void afficherSdd(void)
{
instruction *i;
elementMemoire *a;
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument_optim.c 22/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-82-320.jpg)
![18 jun 03 14:19 instrument_optim.c Page 3/10
int j,nbTotalInstructions,cptInutile2=0,cptMortes=0,cptMortes2=0;
/* Définition du fichier contenant la trace (numéro) des instructions inutiles
) */
FILE *traceInstructionsInutiles = fopen(TRACE_INSTRUCTIONS_INUTILES,"w");
FILE *fichierEvolutionQtTravailInutile = fopen(TRACE_EVOLUTION_INUTILES,"w");
FILE *fichierEvolutionQtValeursMortes = fopen(TRACE_VALEURS_MORTES,"w");
/* Affichage des dépendances entre les instructions dynamiques (stockées dans
la liste chainée d’instructions dynamiques) */
/* Version optimisée : ne sont disponible que les données sur les instructions
inutiles */
fprintf(stdout,"Liste des instructions dynamiques inutiles :n");
for(i=instCourante; i!=NULL; i=i−>precedent)
{
if(i−>utiliteInst==INUTILE)
{
struct donnees_instruction *d = i−>donnees;
fprintf(stdout,"I.Dynamic %dt−− I.Static %dt−− File %dn",d−>numeroDynamique,d−>num
eroStatique,d−>numeroFichier);
/*if(d−>origineOperandes[0]!=NULL) fprintf(stdout,"t−− Dépend de %d",(d−>
origineOperandes[0])−>donnees−>numeroDynamique);
for(j=1; j<MAX_NB_OPERANDES; j++)
if(d−>origineOperandes[j]!=NULL) fprintf(stdout,",%d",(d−>origineOperand
es[j])−>donnees−>numeroDynamique);
fprintf(stdout,"n");*/
/* Ecriture dans le fichier traceInstructionsInutiles du numéro des instru
ctions dynamiques inutiles */
fprintf(traceInstructionsInutiles,"%un",d−>numeroDynamique);
cptInutile++;
if(d−>valeurMorte == 0) cptMortes++;
}
}
fclose(traceInstructionsInutiles);
for(i=instCourante,j=numeroDynamiqueCourant; i!=NULL; i=i−>precedent,j−−)
{
if(i−>utiliteInst == INUTILE)
{
cptInutile2++;
if(i−>donnees−>valeurMorte == 0) cptMortes2++;
}
if(j%20 == 0)
{
fprintf(fichierEvolutionQtTravailInutile,"%dt%dn",j,cptInutile−cptInutile
2);
fprintf(fichierEvolutionQtValeursMortes,"%dt%dn",j,cptMortes−cptMortes2);
}
}
fclose(fichierEvolutionQtTravailInutile);
fclose(fichierEvolutionQtValeursMortes);
nbTotalInstructions = cptUtile + cptInutile + cptNop;
fprintf(stdout,"nCalcul prenant en compte les "nop" :n");
fprintf(stdout,"Nombre d’instructions inutiles : %d/%d soit %f %%n",
cptInutile,nbTotalInstructions,(float)(cptInutile*100)/(float)nbTotalInstructi
ons);
fprintf(stdout,"Nombre d’instructions utiles : %d/%d soit %f %%n",
18 jun 03 14:19 instrument_optim.c Page 4/10
cptUtile,nbTotalInstructions,(float)(cptUtile*100)/(float)nbTotalInstructions)
;
fprintf(stdout,"Nombre de nop : %d/%d soit %f %%nn",
cptNop,nbTotalInstructions,(float)(cptNop*100)/(float)nbTotalInstructions);
nbTotalInstructions = cptUtile + cptInutile;
fprintf(stdout,"nCalcul ne prenant pas en compte les "nop" :n");
fprintf(stdout,"Nombre d’instructions inutiles : %d/%d soit %f %%n",
cptInutile,nbTotalInstructions,(float)(cptInutile*100)/(float)nbTotalInstructi
ons);
fprintf(stdout,"Nombre d’instructions utiles : %d/%d soit %f %%nn",
cptUtile,nbTotalInstructions,(float)(cptUtile*100)/(float)nbTotalInstructions)
;
fprintf(stdout,"Nombre de noeuds dans le graphe : %dn",allocation);
}
void remonterArbre(instruction *inst)
{
int i;
/* Si on n’a pas encore parcouru l’arbre de dépendance de l’instuction inst,
on le parcours pour pour positionner les flag d’utilité utiliteInst[inst−>n
umeroDynamique] */
if(inst−>utiliteInst == INUTILE)
{
inst−>utiliteInst = UTILE;
cptUtile++;
for(i=0; inst−>donnees−>origineOperandes[i]!=NULL; i++) remonterArbre(inst−>
donnees−>origineOperandes[i]);
/* On libère la zone mémoire allouée au champ de donnée lorsqu’on est sur qu
e l’instruction est utile
(ce champ de donnée ne nous sert plus à rien dans ce cas la) */
free(inst−>donnees);
allocation−−;
inst−>donnees = NULL;
}
}
/* Création de la représentation des instructions dynamiques en mémoire */
/* !!!!! Attention, cette fonction est différente selon qu’on utilise le program
me sur Sparc ou x86 (DelaySlot) */
void instrumentationInstructionDebut(int typeInstruction, int numeroInst, int nu
meroFichier)
{
int i;
instruction *inst = malloc(sizeof(instruction));
struct donnees_instruction *d = malloc(sizeof(struct donnees_instruction));
allocation++;
if(inst==NULL || d==NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction instrumentationInstructionDebut dans le fichier instrument.c)n");
exit(10);
}
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument_optim.c 23/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-83-320.jpg)
![d−>numeroFichier = numeroFichier;
d−>numeroStatique = numeroInst;
d−>numeroDynamique = ++numeroDynamiqueCourant;
d−>typeInstruction = typeInstruction;
if(typeInstruction == T_NOP) cptNop++;
for(i=0; i<MAX_NB_OPERANDES; i++) d−>origineOperandes[i] = NULL;
inst−>utiliteInst = INUTILE;
inst−>donnees = d;
inst−>precedent = instCourante;
instCourante = inst;
/*fprintf(stderr,"Début inst statique %d, inst dynamique %d fichier %dn",nume
roInst,tmp−>numeroDynamique,tmp−>numeroFichier);*/
}
/* !!!!! Attention, cette fonction n’est utile que pour les machines utilisant u
n DelaySolt (Sparc) */
void instrumentationInstructionMilieu(void)
{
/* Si l’instruction est un save, on incrémente le niveau de la fenetre de regi
stres */
if(instCourante−>donnees−>typeInstruction == T_SAVE) niveauFenetreRegistre++;
/* Si c’est un restore, on décrémente le niveau de la fenetre de registres */
else if(instCourante−>donnees−>typeInstruction == T_RESTORE) niveauFenetreRegi
stre−−;
}
void instrumentationInstructionFin(void)
{
/*fprintf(stderr,"Fin inst statique numéro %d, inst dynamique numéro %dn",ins
tCourante−>numeroStatique,instCourante−>numeroDynamique);*/
/* Si l’instruction courante est un branchement quelconque, un save ou un rest
ore, on la marque comme utile
et on marque comme utile toute les instructions dont elle dépend (appel réc
ursif à remonterArbre) */
if(instCourante−>donnees−>typeInstruction == T_BRANCHEMENT ||
instCourante−>donnees−>typeInstruction == T_BRANCHEMENT_ANNUL_BIT ||
instCourante−>donnees−>typeInstruction == T_SAVE ||
instCourante−>donnees−>typeInstruction == T_RESTORE ||
instCourante−>donnees−>typeInstruction == T_APPEL_INTERNE ||
instCourante−>donnees−>typeInstruction == T_APPEL_EXTERNE ||
instCourante−>donnees−>typeInstruction == T_APPEL_EXTERNE_SPECIAL) remonter
Arbre(instCourante);
/* Si l’instruction courante est un nop, on la marque comme tel et on libère l
’espace mémoire qui avait était alloué
pour sa représentation interne dans le programme */
else if(instCourante−>donnees−>typeInstruction == T_NOP)
{
instCourante−>utiliteInst = NOP;
free(instCourante−>donnees);
allocation−−;
instCourante−>donnees = NULL;
}
}
18 jun 03 14:19 instrument_optim.c Page 5/10
18 jun 03 14:19 instrument_optim.c Page 6/10
/* !!!!! Attention, cette fonction n’est utile que pour les machines utilisant u
n DelaySolt (Sparc) */
void copierInstDelay(void)
{
instCouranteDelay = instCourante;
}
/* !!!!! Attention, cette fonction n’est utile que pour les machines utilisant u
n DelaySolt (Sparc) */
void echangerInstDelay(void)
{
instruction *tmp = instCourante;
instCourante = instCouranteDelay;
instCouranteDelay = tmp;
}
/* Traitement fait lorsqu’on rencontre une instruction qui accède à la mémoire o
u à des registres (en entrée) */
/* !!!!! Attention, cette fonction est différente selon qu’on utilise le program
me sur Sparc ou x86 (registres) */
void instrumentationEntreeRegistre(int identificateurRessource)
{
int i;
unsigned int identificateurRegistreTournant;
/* identificateurRessource numéro ID_REG_SALTO_G = trou noir (%g0) */
if(identificateurRessource != ID_REG_SALTO_G)
{
/* Si le registre accédé fait partie de la fenêtre de registres tournante */
if(identificateurRessource>=ID_REG_SALTO_O && identificateurRessource<=ID_RE
G_SALTO_I+7)
{
identificateurRegistreTournant = (72−identificateurRessource)+(niveauFenet
reRegistre*OFFSET_FENETRE);
if(identificateurRegistreTournant>=NB_REGISTRES_TOURNANTS)
{
fprintf(stderr,"Nombre maximum de registres tournants dépassé, veulliez augmenter la valeur de
");
fprintf(stderr,"la constante NB_REGISTRES_TOURNANTS dans le fichier instrument.cn");
exit(1);
}
tableLectureRegistresTournants[identificateurRegistreTournant]++;
for(i=0; (instCourante−>donnees−>origineOperandes)[i]!=NULL; i++)
if (i >= MAX_NB_OPERANDES)
{
fprintf(stderr,"Nombre maximum d’opérandes pour une instruction dépassé, veulliez augmente
r la valeur de ");
fprintf(stderr,"la constante MAX_NB_OPERANDES dans le fichier instrument.cn");
exit(8);
}
(instCourante−>donnees−>origineOperandes)[i] = tableRegistresTournants[ide
ntificateurRegistreTournant];
}
/* Sinon, on le considère comme un registre fixe */
else
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument_optim.c 24/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-84-320.jpg)
![18 jun 03 14:19 instrument_optim.c Page 7/10
{
tableLectureRegistres[identificateurRessource]++;
for(i=0; (instCourante−>donnees−>origineOperandes)[i]!=NULL; i++)
if (i >= MAX_NB_OPERANDES)
{
fprintf(stderr,"Nombre maximum d’opérandes pour une instruction dépassé, veulliez augmente
r la valeur de ");
fprintf(stderr,"la constante MAX_NB_OPERANDES dans le fichier instrument.cn");
exit(8);
}
(instCourante−>donnees−>origineOperandes)[i] = tableRegistres[identificate
urRessource];
}
}
}
/* Traitement fait lorsqu’on rencontre une instruction qui accède à la mémoire o
u à des registres (en sortie) */
/* !!!!! Attention, cette fonction est différente selon qu’on utilise le program
me sur Sparc ou x86 (registre %g0) */
void instrumentationSortieRegistre(int identificateurRessource)
{
unsigned int identificateurRegistreTournant;
/* Mise à jour du compteur de résultat : le registre identificateurRessource e
st considéré comme un résultat
de l’instruction instCourante */
instCourante−>donnees−>valeurMorte++;
/* Si le registre dans lequel on écrit est le numéro 41 (correspondant à %g0),
on n’en tient pas compte car ce
registre est un trou noir (quelque soit ce qui y est écrit, on lit toujours
la valeur 0 dans ce registre) */
if(identificateurRessource != ID_REG_SALTO_G)
{
/* Si le registre accédé fait partie de la fenêtre de registres tournante */
if(identificateurRessource>=ID_REG_SALTO_O && identificateurRessource<=ID_RE
G_SALTO_I+7)
{
identificateurRegistreTournant = (72−identificateurRessource)+(niveauFenet
reRegistre*OFFSET_FENETRE);
if(identificateurRegistreTournant>=NB_REGISTRES_TOURNANTS)
{
fprintf(stderr,"Nombre maximum de registres tournants dépassé, veulliez augmenter la valeur de
");
fprintf(stderr,"la constante NB_REGISTRES_TOURNANTS dans le fichier instrument.cn");
exit(1);
}
if(tableLectureRegistresTournants[identificateurRegistreTournant] == 0 &&
tableRegistresTournants[identificateurRegistreTournant]−>utiliteInst ==
INUTILE)
tableRegistresTournants[identificateurRegistreTournant]−>donnees−>val
eurMorte−−;
tableRegistresTournants[identificateurRegistreTournant] = instCourante;
tableLectureRegistresTournants[identificateurRegistreTournant] = 0;
}
/* Sinon, on le considère comme un registre fixe */
else
{
Imprimé par Benjamin Vidal
if(tableLectureRegistres[identificateurRessource] == 0 &&
tableRegistres[identificateurRessource]−>utiliteInst == INUTILE)
tableRegistres[identificateurRessource]−>donnees−>valeurMorte−−;
tableRegistres[identificateurRessource] = instCourante;
tableLectureRegistres[identificateurRessource] = 0;
}
}
}
void lectureMemoireOctet(int adresseMemoire)
{
int i;
elementMemoire *a;
/*static elementMemoire *lecturePrecedente = NULL;*/
/* Si l’adresse accédée est consécutive à la précédente, alors on initialise a
à lecturePrecedente−>suivant */
/* Sinon, on parcourt la liste chainée pour trouver l’élément mémoire corespon
dant */
/*if((lecturePrecedente−>adresse)+1 == adresseMemoire) a=lecturePrecedente−>su
ivant;
else*/
for(a=adresseInitiale; a==NULL || adresseMemoire>a−>adresse; a=a−>suivant)
if(a==NULL)
{
/*fprintf(stderr,"Accès à l’adresse mémoire non initialisée %d par l’ins
truction %d (fichier %d)n",
adresseMemoire, instCourante−>donnees−>numeroStatique, instCourante−>don
nees−>numeroFichier);*/
return;
}
if(adresseMemoire != a−>adresse)
{
/*fprintf(stderr,"Accès à l’adresse mémoire non initialisée %d par l’instruc
tion %d (fichier %d)n",
adresseMemoire, instCourante−>donnees−>numeroStatique, instCourante−>donnees
−>numeroFichier);*/
return;
}
for(i=0; (instCourante−>donnees−>origineOperandes)[i]!=NULL; i++)
if (i >= MAX_NB_OPERANDES)
{
fprintf(stderr,"Nombre maximum d’opérandes pour une instruction dépassé, veulliez augmenter la va
leur de ");
fprintf(stderr,"la constante MAX_NB_OPERANDES dans le fichier instrument.cn");
exit(8);
}
(instCourante−>donnees−>origineOperandes)[i] = a−>derniereEcriture;
a−>nbLecture++;
/*lecturePrecedente = a;*/
}
18 jun 03 14:19 instrument_optim.c Page 8/10
mercredi 18 juin 2003 instrument_optim.c 25/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-85-320.jpg)

![19 mai 03 17:16 instrumentation2.cc Page 1/9
#include <stdio.h>
#include <fcntl.h>
#include <errno.h>
#include <fstream>
#include <iostream>
#include <sys/types.h>
#include <regex.h>
#include <stdlib.h>
#include <string.h>
#include "salto.h"
#include "instrument.h"
#define FICHIER_SOURCE_ASSEMBLEUR ".s$"
#define REPERTOIRE_FICHIER_INSTRUMENTES "instrumente2/"
#define SAVE "save %sp,−136,%sp"
#define RESTORE "restore %g0,%g0,%g0"
#define NOP "nop"
#define OFFSET_INSTRUMENTATION "16"
#define OFFSET_INSTRUMENTATION_2 "28"
#define OFFSET_INSTRUMENTATION_DELAY_SLOT "64"
#define OFFSET_2_INSTRUMENTATION_DELAY_SLOT "44"
#define OFFSET_INSTRUMENTATION_ANNUL_BIT "76"
#define EXP_ANNUL_BIT ",a[ ]+"
#define ETIQUETTE_FONCTION_NOP "f_nop"
// Pointeur sur le fichier dans lequel sera écrit le code instrumenté
FILE *fichierSInstrumente;
// Pointeur sur le fichier contenant le code original (non instrumenté)
FILE *fichierSOriginal;
// Permet d’identifier de manière unique le fichier en cours de traitement
unsigned char numeroFichier;
// Fonction permettant de sauvagarder le contexte du programme (registres généra
ux et codes conditions) afin de ne pas
// intervenir sur les valeurs des registres et codes conditions utilisés par le
programme
void sauvegardeContexte(BB *bb, int position, unsigned int *nbInstructionsAjoute
es)
{
INST *instCCR;
char *lectureCodesConditions = "trd %ccr,%l0n";
// "Empilement" du contexte du programme (création d’un contexte intermédiaire
artificiel entre l’exécution du
// programme et l’exécution des fonctions d’instrumentation du code. Ce contex
te permet de travailler avec
// les registres %o[0−5] afin de faire passer les paramètres aux fonctions d’i
nstrumentations.
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(SAVE));
19 mai 03 17:16 instrumentation2.cc Page 2/9
(*nbInstructionsAjoutees)++;
instCCR = newAsm(NOP);
instCCR−>addAttribute(UNPARSE_ATT, lectureCodesConditions, strlen(lectureCodes
Conditions)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, instCCR);
(*nbInstructionsAjoutees)++;
// Sauvegarde en mémoire (dans la pile) des registres globaux
for(int i=1; i<=4; i++)
{
char tmp[20];
// Sauvegarde du registre (%gi) (ex : "st %g1,[%sp+92]")
sprintf(tmp,"st %%g%d,[%%sp+%d]",i,88+(4*i));
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(tmp));
(*nbInstructionsAjoutees)++;
}
}
// Fonction permettant de restaurer le contexte du programme (registres généraux
et codes conditions) afin de ne pas
// intervenir sur les valeurs des registres et codes conditions utilisés par le
programme
void restaurationContexte(BB *bb, int position, unsigned int *nbInstructionsAjou
tees)
{
INST *instCCR;
char *ecritureCodesConditions = "twr %l0,%ccrn";
// Récupération des registres globaux depuis la mémoire (depuis la pile)
for(int i=1; i<=4; i++)
{
char tmp[20];
// Restauration du registre (%gi) (ex : "ld [%sp+92],%g1")
sprintf(tmp,"ld [%%sp+%d],%%g%d",88+(4*i),i);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(tmp));
(*nbInstructionsAjoutees)++;
}
instCCR = newAsm(NOP);
instCCR−>addAttribute(UNPARSE_ATT, ecritureCodesConditions, strlen(ecritureCod
esConditions)+1);
bb−>insertAsm(*nbInstructionsAjoutees+position, instCCR);
(*nbInstructionsAjoutees)++;
// "Dépilement" du contexte du programme
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(RESTORE));
(*nbInstructionsAjoutees)++;
}
int estPresent(char *motif, char *chaine)
{
int i;
regex_t *preg = new regex_t();
size_t nmatch = 10;
regmatch_t pmatch[nmatch];
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation2.cc 27/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-87-320.jpg)
![19 mai 03 17:16 instrumentation2.cc Page 3/9
// Compilation de l’expression régulière
if (regcomp(preg, motif, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière "%s"n",motif);
exit(4);
}
// Exécution de l’expression régulière et renvoi du résultat en fonction
if (regexec(preg, chaine, nmatch, pmatch, 0) == REG_NOMATCH)
{
regfree(preg);
return 0;
}
for(i=0; i<nmatch && pmatch[i].rm_so!=−1; i++);
regfree(preg);
return i;
}
int typeInstruction(INST *inst)
{
if(inst−>isCTI())
if(estPresent(EXP_ANNUL_BIT,inst−>unparse())) return T_BRANCHEMENT_ANNUL_BIT
;
else return T_BRANCHEMENT;
return T_AUTRE;
}
void appelDeFonctionInst(INST *inst, BB *bb, int position, unsigned int *nbInstr
uctionsAjoutees, int numeroInst)
{
static unsigned char flagDelaySlot=0;
char chaine[20],tmp[100], *lecturePC = "trd %pc,%o1n";
static INST *dernierBranchement;
if(!flagDelaySlot) sauvegardeContexte(bb, position, nbInstructionsAjoutees);
// On empile un paramètre de type entier à passer à la fonction (équivaut à mo
v typeInst,%o0)
sprintf(chaine,"or %%g0,%d,%%o0",typeInstruction(inst));
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Si la constante numeroInst à ranger dans %o1 peut être codée sur 13 bits (i
.e. est entre −4096 et 4095)
if(numeroInst <= 4095)
{
// On empile un paramètre de type entier à passer à la fonction (équivaut à
mov numeroInst,%o1)
sprintf(chaine,"or %%g0,%d,%%o1",numeroInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
}
else
{
// On empile ce même paramètre mais en deux fois (les 22 premiers bits du re
Imprimé par Benjamin Vidal
19 mai 03 17:16 instrumentation2.cc Page 4/9
gistre d’abbord)
sprintf(chaine,"sethi %%hi(%d),%%o1",numeroInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Puis les 10 derniers bits ensuite
sprintf(chaine,"or %%o1,%%lo(%d),%%o1",numeroInst);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
}
// On empile un paramètre de type entier à passer à la fonction (équivaut à mo
v numeroFichier,%o2)
sprintf(chaine,"or %%g0,%d,%%o2",numeroFichier);
bb−>insertAsm(*nbInstructionsAjoutees+position, newAsm(chaine));
(*nbInstructionsAjoutees)++;
// Si le branchement est un brachement avec annul_bit (ex : bl,a ...
) alors on rempli la chaine de caractère
// chaineAnnulBit en conséquence (on y met les instructions pour tra
iter ce cas correctement)
if(flagDelaySlot && typeInstruction(dernierBranchement)==T_BRANCHEME
NT_ANNUL_BIT)
{
int i;
char *chaineAnnulBit = (char *)malloc(100*sizeof(char));
regex_t *preg = new regex_t();
size_t nmatch = 1;
regmatch_t pmatch[nmatch];
INST *inst_br_nop;
if (regcomp(preg, EXP_ANNUL_BIT, REG_EXTENDED))
{
fprintf(STDERR,"Erreur lors de la compilation de l’expression régulière ""EXP_ANNUL
_BIT""n");
exit(4);
}
if (regexec(preg, dernierBranchement−>unparse(), nmatch, pmatch, 0
) == REG_NOMATCH)
{
fprintf(STDERR,"Erreur lors de l’exécution de l’expression régulière ""EXP_ANNUL_B
IT"" :n");
fprintf(STDERR,"Impossible de trouver l’expression régulière dans l’instruction "%s"n
",dernierBranchement−>unparse());
exit(4);
}
regfree(preg);
for(i=0; i<pmatch[0].rm_eo; i++)
tmp[i] = (dernierBranchement−>unparse())[i];
tmp[i] = ’0’;
strcpy(chaineAnnulBit,"trd %pc,%o7n");
strcat(chaineAnnulBit,"tadd %o7,"OFFSET_INSTRUMENTATION_2",%o7n");
strcat(chaineAnnulBit,"twr %l0,%ccrn");
strcat(chaineAnnulBit,tmp);
strcat(chaineAnnulBit," "ETIQUETTE_FONCTION_NOP"n");
mercredi 18 juin 2003 instrumentation2.cc 28/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-88-320.jpg)


![void Salto_init_hook(int argc, char *argv[])
{
int i,j,k;
char nomFichierSortie[100];
// Récupération dans la ligne de commande entrée par l’utilisateur du nom du f
ichier original
for(i=1; i<argc && !estPresent("−i",argv[i]); i++);
if(i == argc−1)
{
fprintf(STDERR,"Erreur, votre ligne de commande ne comporte pas l’option "−i"n");
exit(6);
}
// On ouvre le fichier .s original à traiter pour pouvoir s’en servir dans sal
to_hook()
fichierSOriginal = fopen(argv[i+1],"r");
if(fichierSOriginal == NULL)
{
fprintf(STDERR,"Problème lors de l’ouverture du fichier "%s" ",argv[i+1]);
fprintf(STDERR,"(fonction Salto_init_hook dans le fichier instrumentation2.cc)n");
exit(11);
}
nomFichierSortie[0]=’0’;
strcat(nomFichierSortie,REPERTOIRE_FICHIER_INSTRUMENTES);
strcat(nomFichierSortie,argv[i+1]);
// On ouvre le fichier .s instrumenté en écriture à traiter pour pouvoir s’en
servir dans salto_hook()
fichierSInstrumente = fopen(nomFichierSortie,"w");
if(fichierSInstrumente == NULL)
{
fprintf(STDERR,"Problème lors de l’ouverture du fichier "%s" ",nomFichierSortie);
fprintf(STDERR,"(fonction Salto_init_hook dans le fichier instrumentation2.cc)n");
exit(11);
}
// Recherche de l’expression "−−" dans la ligne de commande
for(; i<argc && !estPresent("−−",argv[i]); i++);
// Si cette expression n’est pas présente, on ne numérote pas les fichiers
if(i == argc−1) numeroFichier = 0;
else numeroFichier = atoi(argv[i+1]);
}
void Salto_end_hook()
{
exit(0);
}
19 mai 03 17:16 instrumentation2.cc Page 9/9
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrumentation2.cc 31/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-91-320.jpg)
![19 mai 03 15:50 instrument2.c Page 1/3
#include <stdio.h>
#include <stdlib.h>
#include "instrument.h"
/* Constantes utiles pour inhiber l’action des instructions dynamiques inutiles
:
Si l’on doit annuler l’instruction, on renvoit la constante 68 permettant de
sauter l’instruction inutile
ainsi que son instrumentation. Si l’on ne doit pas annuler l’instruction, on
renvoit la constante 16 permettant
de faire sauter le PC à la suite du programme (instruction à ne pas annuler e
t son instrumentation) */
#define ANNUL 52
#define NON_ANNUL 0
typedef unsigned char flag;
typedef struct instru {
unsigned int numeroDynamique;
struct instru *precedent;
} instruction;
instruction *instInitiale;
instruction *instCourante = NULL;
unsigned int tailleListeInstInutile;
unsigned int *listeInstInutile;
void initVariablesGlobales(void)
{
int i;
char c;
FILE *traceInstructionsInutiles;
/* Création d’une instruction initiale fictive sur laquelle vont pointer celle
s qui
utilisent des registres déjà initialisés lors du lancement du programme */
instInitiale = malloc(sizeof(instruction));
if(instInitiale == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction initVariablesGlobales dans le fichier instrument2.c)n");
exit(10);
}
instInitiale−>numeroDynamique = 0;
instInitiale−>precedent = NULL;
instCourante = instInitiale;
tailleListeInstInutile = 0;
traceInstructionsInutiles = fopen(TRACE_INSTRUCTIONS_INUTILES,"r");
if(traceInstructionsInutiles == NULL)
{
fprintf(stderr,"Problème lors de l’ouverture du fichier ""TRACE_INSTRUCTIONS_INUTILES"" "
19 mai 03 15:50 instrument2.c Page 2/3
);
fprintf(stderr,"(fonction initVariablesGlobales dans le fichier instrument2.c)n");
exit(11);
}
/* On compte le nombre de lignes dans le fichier */
do if(fgetc(traceInstructionsInutiles)==’n’) tailleListeInstInutile++;
while(!feof(traceInstructionsInutiles));
fclose(traceInstructionsInutiles);
listeInstInutile = malloc(tailleListeInstInutile*sizeof(unsigned int));
traceInstructionsInutiles = fopen(TRACE_INSTRUCTIONS_INUTILES,"r");
if(traceInstructionsInutiles == NULL)
{
fprintf(stderr,"Problème lors de l’ouverture du fichier ""TRACE_INSTRUCTIONS_INUTILES"" "
);
fprintf(stderr,"(fonction initVariablesGlobales dans le fichier instrument2.c)n");
exit(11);
}
for(i=tailleListeInstInutile−1; i>=0; i−−) fscanf(traceInstructionsInutiles, "
%u", &listeInstInutile[i]);
}
/* Création de la représentation des instructions dynamiques en mémoire */
int instrumentationInstruction(int typeInstruction, int numeroStatique, int nume
roFichier)
{
int i;
static int indiceListeInstructions = 0;
instruction *tmp = malloc(sizeof(instruction));
if(tmp == NULL)
{
fprintf(stderr,"Taille mémoire maximale allouable dépassée !! ");
fprintf(stderr,"(fonction instrumentationInstruction dans le fichier instrument2.c)n");
exit(10);
}
if(instCourante−>numeroDynamique >= MAX_NB_INST_DYNAMIQUE)
{
fprintf(stderr,"Nombre maximum d’instruction dépassé, veulliez augmenter la valeur de la constante ")
;
fprintf(stderr,"MAX_NB_INST_DYNAMIQUE dans le fichier instrument.hn");
exit(1);
}
tmp−>numeroDynamique = instCourante−>numeroDynamique+1;
tmp−>precedent = instCourante;
instCourante = tmp;
fprintf(stderr,"I.Dynamic %dt−− I.Static %dt−− File %d",instCourante−>numeroDynamique,n
umeroStatique,numeroFichier);
if(typeInstruction == T_BRANCHEMENT)
{
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument2.c 32/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-92-320.jpg)
![fprintf(stderr,"t−− Branchn");
return NON_ANNUL;
}
if(typeInstruction == T_BRANCHEMENT_ANNUL_BIT)
{
fprintf(stderr,"t−− Branch annul bitn");
return NON_ANNUL;
}
/* Si le numéro de l’instruction dynamique en cours de traitement est le même
que le dernier numéro
testé comme étant une instruction inutile, alors on retourne la valeur ANNU
L */
if(instCourante−>numeroDynamique == listeInstInutile[indiceListeInstructions]
&&
indiceListeInstructions < tailleListeInstInutile)
{
indiceListeInstructions++;
fprintf(stderr,"t−− Non exécutéen");
return ANNUL;
}
fprintf(stderr,"n");
return NON_ANNUL;
}
19 mai 03 15:50 instrument2.c Page 3/3
Imprimé par Benjamin Vidal
mercredi 18 juin 2003 instrument2.c 33/37](https://image.slidesharecdn.com/rapportstagedea-141029183903-conversion-gate01/85/Evaluation-de-la-quantite-de-travail-in-utile-dans-l-execution-des-programmes-93-320.jpg)





Le rapport de stage de Benjamin Vidal se concentre sur l'évaluation du travail utile dans l'exécution des programmes dans le domaine de l'architecture des processeurs, face à des contraintes croissantes comme la consommation énergétique et la latence des signaux. L'objectif est de définir ce qui constitue un travail utile pour améliorer les performances des processeurs et de développer un algorithme pour quantifier les instructions utiles à partir d'exécutions de programmes. Le rapport présente également des remerciements pour l'encadrement reçu et décrit les méthodes et outils utilisés dans l'étude.

















































































