Téléchargé 28 fois









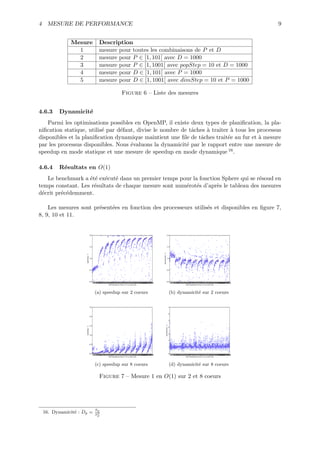
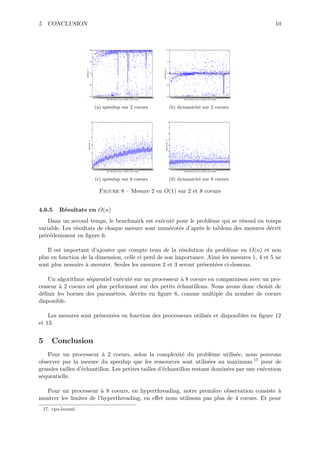
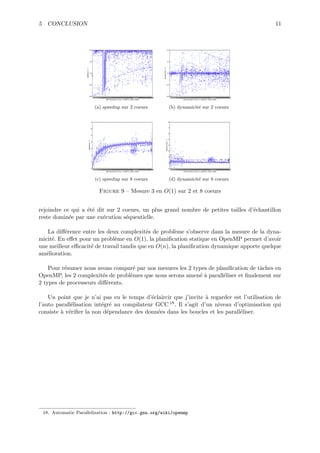
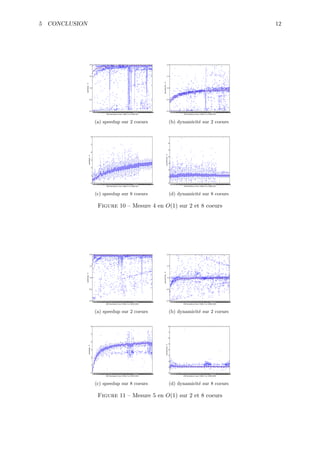

Le document aborde la parallélisation et les modèles de programmation, en se concentrant sur des algorithmes pour le produit matriciel et le tri d'un tableau binaire. Il propose des solutions détaillées avec des pseudo-codes, des implémentations en C++, et des considérations sur la performance. Le tout est structuré autour d'exemples concrets et de diagrammes illustrant le design des classes et l'utilisation d'OpenMP.
























































![[0] maitre exclave](https://cdn.slidesharecdn.com/ss_thumbnails/0maitreexclave-121125111144-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























