Télécharger en tant que PDF, PPTX





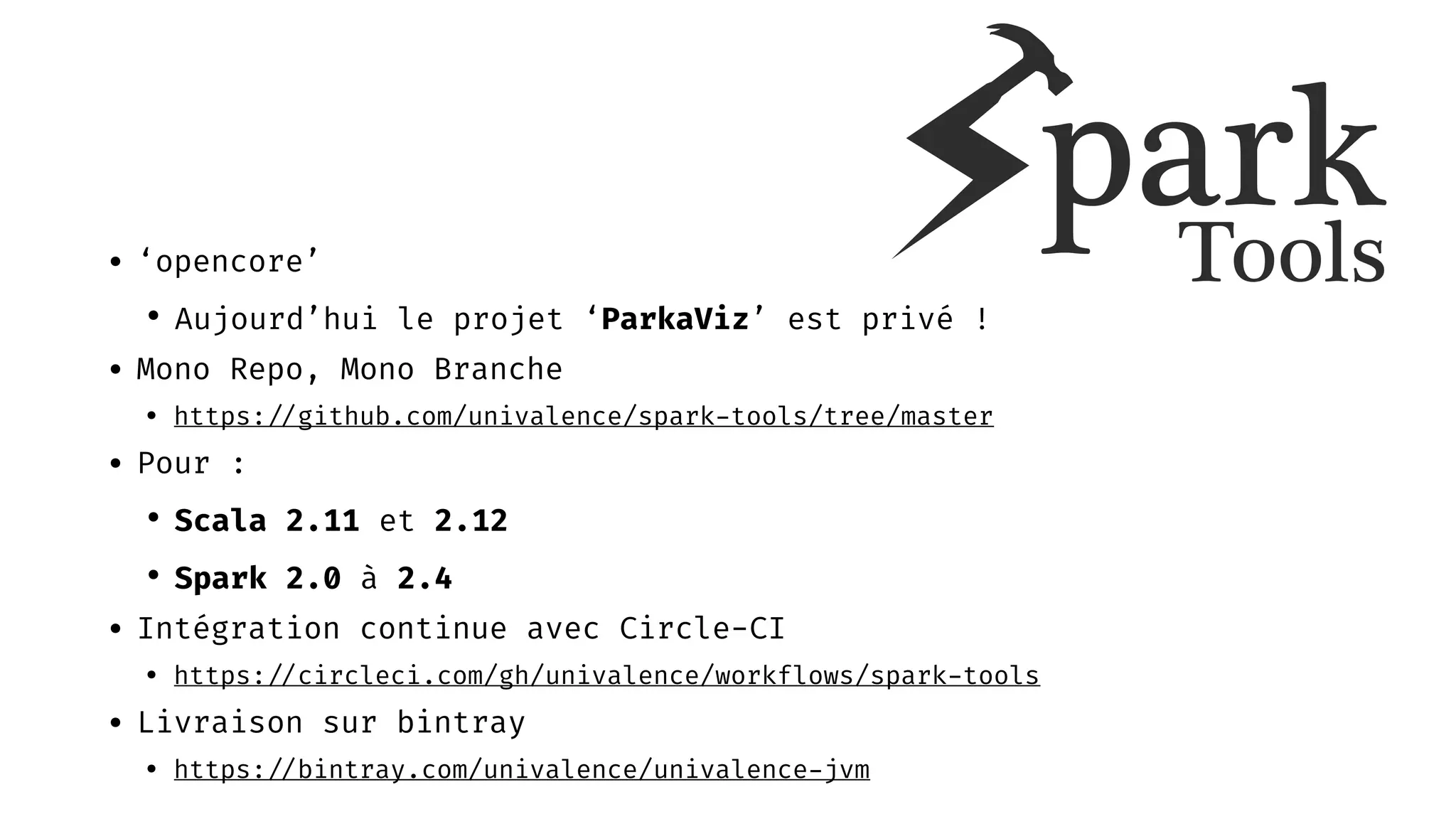









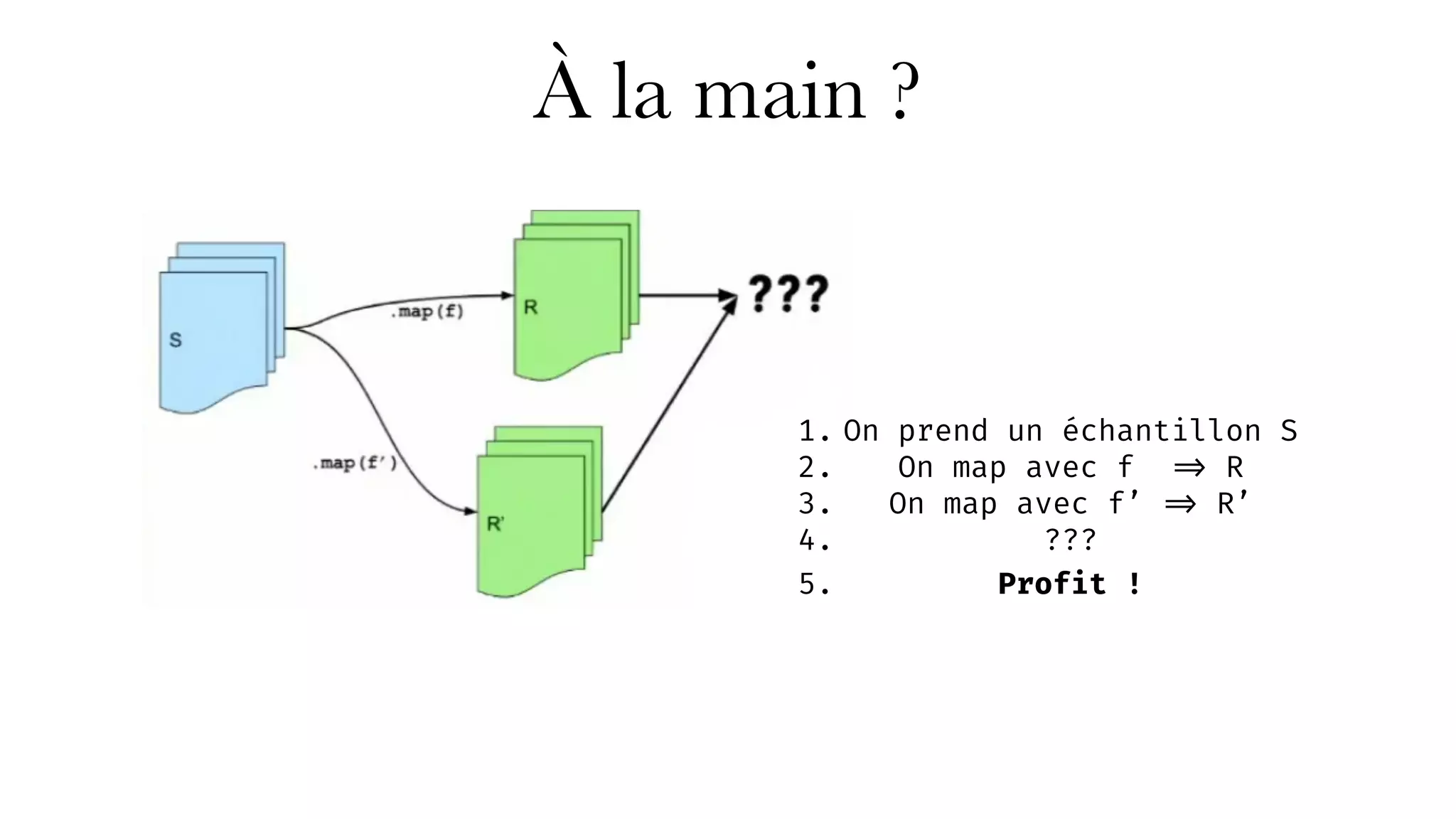
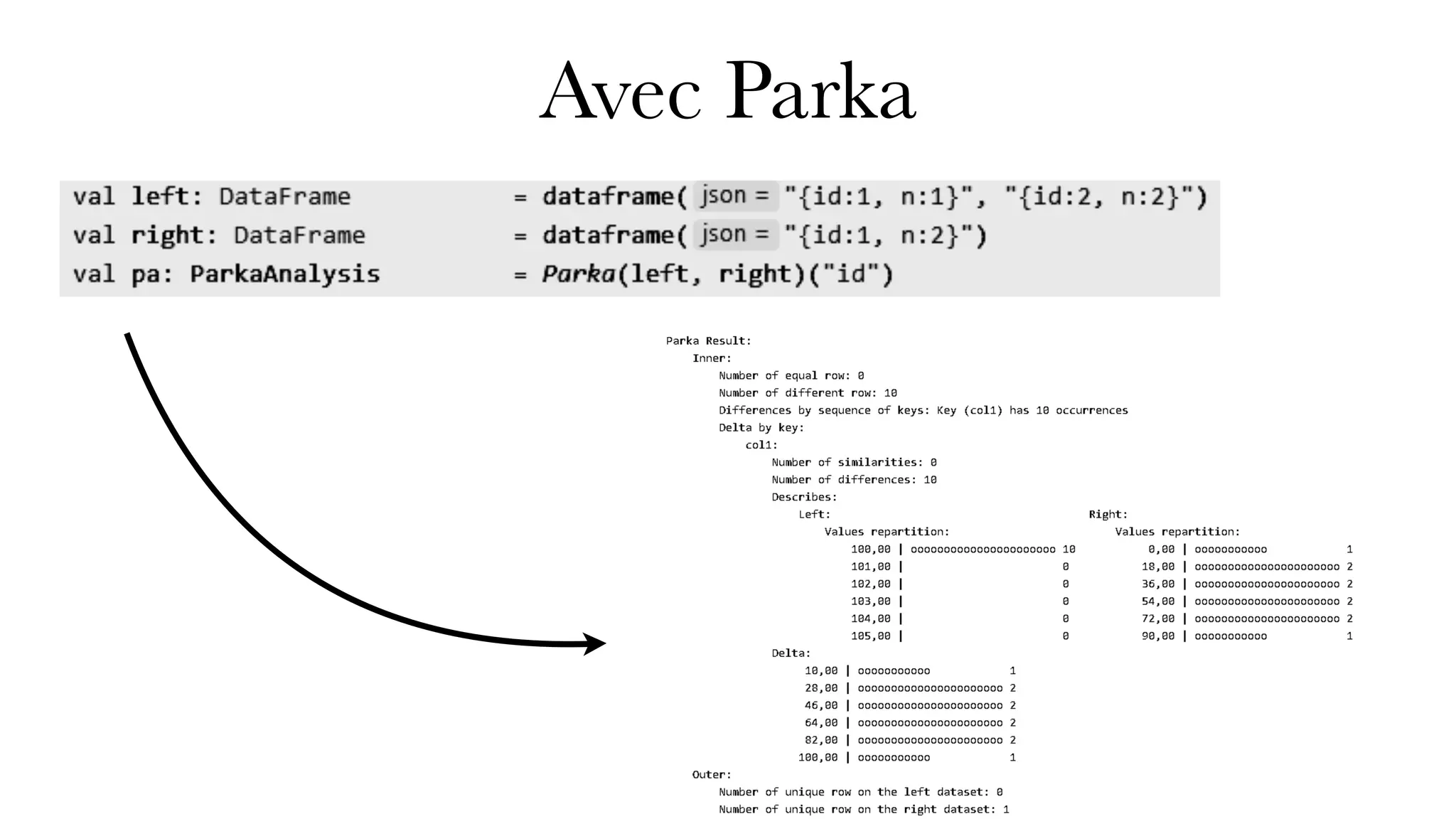



Le document présente Univalence, un cabinet d'expertise en data engineering co-organisé par Jonathan Winandy, qui se concentre sur l'amélioration des pratiques d'ingénierie des données à travers le conseil, l'audit, et des formations sur des outils comme Scala et Spark. Il détaille plusieurs projets, dont 'spark-test' pour faciliter les tests avec Spark, et 'cent centrifuge', destiné à la gestion de la qualité des données. La feuille de route inclut le développement de nouveaux outils et l'intégration de projets supplémentaires.






![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[USI] Lambda-Architecture : comment réconcilier BigData et temps-réel](https://cdn.slidesharecdn.com/ss_thumbnails/preslambdaarch-v3-slideshare-140617091602-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























