Ce document présente une analyse des données fonctionnelles à travers l'utilisation des machines à vecteurs de support (SVM) et des méthodes d'analyse fonctionnelle (FDA). Il explore les principes des SVM, y compris les noyaux pour FDA, et propose différentes approches méthodologiques comme la projection, les splines d'interpolation, et la régression inverse. Les travaux incluent également des problématiques pratiques et des apports en matière de régularisation et d'extensions des perceptrons pour le traitement de données fonctionnelles.






![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Exemples
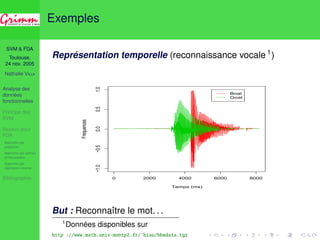
Représentation fréquentielle (reconnaissance vocale 1)
0 50 100 150 200 250
0 5 10 15 20 25
Frequences
Log−periodogramme
[aa]
[ao]
But : Reconnaître le son. . .
1TIMIT database disponible sur
http ://www-stat.stanford.edu/˜tibs/ElemStatLearn/datasets/phoneme.data](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-7-320.jpg)

![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
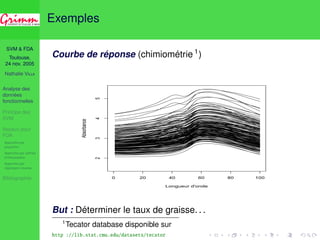
Exemple de problèmes en FDA (1)
Problèmes d’inversion d’opérateurs
X = E(X
X) − E(X)
E(X) est de Hilbert-Schmidt ) −1
X est
non borné (ce n’est pas un opérateur continu de L2
) ! !
ni
Conséquence au niveau de l’estimation
Pn
= 1
X n
=1 xi
xi − X
X est mal conditionné ) nécessité de
pénalisation ou de régularisation.
Exemple : Régression inverse fonctionnelle
[Ferré Villa, 2005]](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-10-320.jpg)









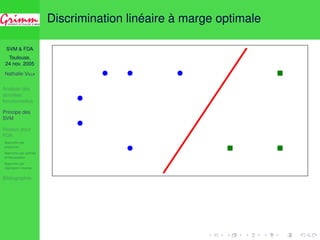
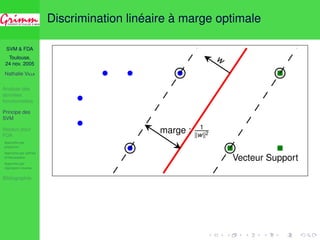
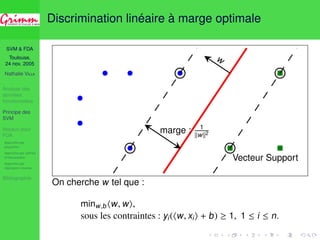
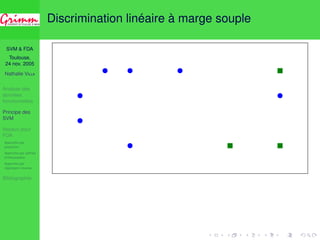


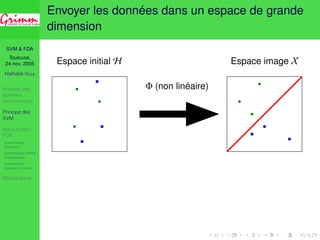
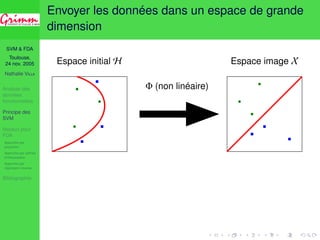










![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
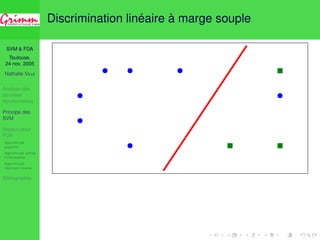
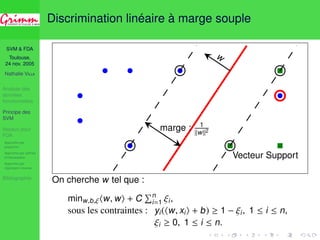
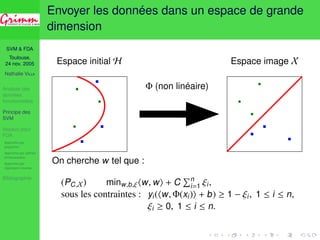
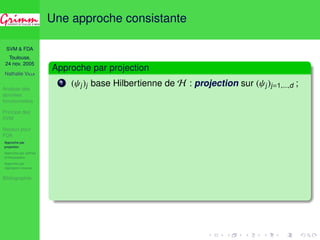
Une approche consistante
Approche par projection
1 ( j)j base Hilbertienne de H : projection sur ( j)j=1,...,d ;
2 Choix des paramètres : a d 2 N, K 2 Jd, C 2 [0; Cd]](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-44-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Une approche consistante
Approche par projection
1 ( j)j base Hilbertienne de H : projection sur ( j)j=1,...,d ;
2 Choix des paramètres : a d 2 N, K 2 Jd, C 2 [0; Cd]
partage des données : B1 = (x1, y1), . . . , (xl , yl ) et
B2 = (xl+1, yl+1), . . . , (xn, yn) ;](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-45-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Une approche consistante
Approche par projection
1 ( j)j base Hilbertienne de H : projection sur ( j)j=1,...,d ;
2 Choix des paramètres : a d 2 N, K 2 Jd, C 2 [0; Cd]
partage des données : B1 = (x1, y1), . . . , (xl , yl ) et
B2 = (xl+1, yl+1), . . . , (xn, yn) ;
construction du SVM sur B1 : fa ;](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-46-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Une approche consistante
Approche par projection
1 ( j)j base Hilbertienne de H : projection sur ( j)j=1,...,d ;
2 Choix des paramètres : a d 2 N, K 2 Jd, C 2 [0; Cd]
partage des données : B1 = (x1, y1), . . . , (xl , yl ) et
B2 = (xl+1, yl+1), . . . , (xn, yn) ;
construction du SVM sur B1 : fa ;
choix du paramètre optimal sur B2 :
a = argmina
bL
n−l fa +
d
p
n − l
avecbL
n−l fa = 1
n−l
Pni
=l+1 I{fa (xi ),yi }.](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-47-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Une approche consistante
Approche par projection
1 ( j)j base Hilbertienne de H : projection sur ( j)j=1,...,d ;
2 Choix des paramètres : a d 2 N, K 2 Jd, C 2 [0; Cd]
partage des données : B1 = (x1, y1), . . . , (xl , yl ) et
B2 = (xl+1, yl+1), . . . , (xn, yn) ;
construction du SVM sur B1 : fa ;
choix du paramètre optimal sur B2 :
a = argmina
bL
n−l fa +
d
p
n − l
avecbL
n−l fa = 1
n−l
Pni
=l+1 I{fa (xi ),yi }.
) On obtient un SVM fn.](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-48-320.jpg)






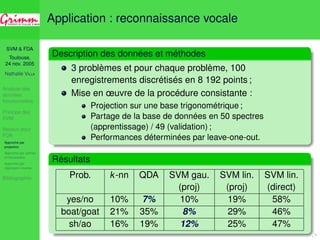




![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Approche directe pour SVM sur dérivées
X est régulière : X 2 H = Hm = {x : [0; 1] ! R :
Dmx existe et Dmx 2 L2 + conditions aux limites} ;](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-60-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Approche directe pour SVM sur dérivées
X est régulière : X 2 H = Hm = {x : [0; 1] ! R :
Dmx existe et Dmx 2 L2 + conditions aux limites} ;
Produit scalaire : H est muni du produit scalaire
hf , giH = hLf , LgiL2 =
Z
[0;1]
Lf (t)Lg(t)dt
où Lx =
Pmj
=1 ajDjx avec am , 0 et les conditions aux
limites qui impliquent Lx , 0 si x , 0.](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-61-320.jpg)


![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Exemples d’espaces de Sobolev
H1 avec L = I + D et x(0) = 0 (Lx = 0 ) x = ae−t et
x(0) = a) ;
H2 avec L = I + D2 et x(0) = Dx(0) = 0 ;
Hm (m 1) avec L = Dm et Djx(0) = 0, 8 j = 1, . . . ,m − 1.
Pour d’autres exemples, voir [Besse Ramsay, 1986] et
[Berlinet Thomas-Agnan, 2004].](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-64-320.jpg)



![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
SVM fonctionnels par interpolation spline
[Besse Ramsay, 1986]
Si H est un RKHS de noyau K alors, 8 x 2 H, connue aux
points (tk )k=1,...,d, spline d’interpolation
h = PVect{K(tk ,.),k=1,...,d}(x).](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-68-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
SVM fonctionnels par interpolation spline
[Besse Ramsay, 1986]
Si H est un RKHS de noyau K alors, 8 x 2 H, connue aux
points (tk )k=1,...,d, spline d’interpolation
h = PVect{K(tk ,.),k=1,...,d}(x).
Application aux SVM
dans L2
SVM sur (Lhn)n avec noyau G1
[0;1]
,
SVM sur (xn)n avec noyau Gd
K−1/2 dans Rd.
où xn = (xn(t1), . . . , xn(td)) et K = (K(ti , tj))i,j .](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-69-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Consistance directe
Théorème 2 Consistance universelle
Soit (tk )k=1,...,d des points de discrétisation dans [0; 1] tels que
K = (K(ti , tj))i,j=1,...,d soit inversible. Alors,](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-70-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Consistance directe
Théorème 2 Consistance universelle
Soit (tk )k=1,...,d des points de discrétisation dans [0; 1] tels que
K = (K(ti , tj))i,j=1,...,d soit inversible. Alors,
il existe une suite de points de discrétisation (D)D1 telle
que
d = (tk )k=1,...,d,
8D 1, D D+1 et KD = (K(ti , tj ))i,j=1,...,D est inversible,
Vect{K(t, .), t 2 [D1D} est dense dans H ;](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-71-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Consistance directe
Théorème 2 Consistance universelle
Soit (tk )k=1,...,d des points de discrétisation dans [0; 1] tels que
K = (K(ti , tj))i,j=1,...,d soit inversible. Alors,
il existe une suite de points de discrétisation (D)D1 telle
que
d = (tk )k=1,...,d,
8D 1, D D+1 et KD = (K(ti , tj ))i,j=1,...,D est inversible,
Vect{K(t, .), t 2 [D1D} est dense dans H ;
le SVM construit à partir de la spline d’interpolation avec
une suite de régularisation (CD
n )n = O(n1−](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-72-320.jpg)



![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Régression inverse fonctionnelle
Modèle ([Ferré Yao, 2003], [Ferré Villa, 2005])
Y = f (ha1, Xi . . . haq, Xi, ),
où y X, E() = 0, f inconnue, {a1, . . . , aq} linéairement
independants.
EDR = Vect{a1, . . . aq}](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-76-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Régression inverse fonctionnelle
Modèle ([Ferré Yao, 2003], [Ferré Villa, 2005])
Y = f (ha1, Xi . . . haq, Xi, ),
où y X, E() = 0, f inconnue, {a1, . . . , aq} linéairement
independants.
EDR = Vect{a1, . . . aq}
Caractérisation de l’espace EDR
Si, pour A = (hX, a1i, . . . , hX, aqi),
Condition de Li 8 u 2 H, 9v 2 Rq : E(hu, Xi|A) = vTA,
alors E(X|Y) 2 X(EDR).](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-77-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
Régression inverse fonctionnelle
Modèle ([Ferré Yao, 2003], [Ferré Villa, 2005])
Y = f (ha1, Xi . . . haq, Xi, ),
où y X, E() = 0, f inconnue, {a1, . . . , aq} linéairement
independants.
EDR = Vect{a1, . . . aq}
Caractérisation de l’espace EDR
Si, pour A = (hX, a1i, . . . , hX, aqi),
Condition de Li 8 u 2 H, 9v 2 Rq : E(hu, Xi|A) = vTA,
alors E(X|Y) 2 X(EDR).
) On choisit d’estimer a1, . . . , aq, vecteurs propres de
−1
X E(X|Y).](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-78-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
SVM par FIR
Estimation de EDR : [Ferré Yao, 2003],
[Ferré Villa, 2005] proposent des approches
consistantes de l’estimation de l’espace EDR,[EDR;](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-79-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
SVM par FIR
Estimation de EDR : [Ferré Yao, 2003],
[Ferré Villa, 2005] proposent des approches
consistantes de l’estimation de l’espace EDR,[EDR;
Estimation de f par SVM : SVM sur P[EDR(X) ;](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-80-320.jpg)
![SVM FDA
Toulouse,
24 nov. 2005
Nathalie VILLA
Analyse des
données
fonctionnelles
Principe des
SVM
Noyaux pour
FDA
Approche par
projection
Approche par splines
d’interpolation
Approche par
régression inverse
Bibliographie
SVM par FIR
Estimation de EDR : [Ferré Yao, 2003],
[Ferré Villa, 2005] proposent des approches
consistantes de l’estimation de l’espace EDR,[EDR;
Estimation de f par SVM : SVM sur P[EDR(X) ;
Résultat de consistance universelle pour ce SVM : ? ? ?](https://image.slidesharecdn.com/enac2005-11-24-140831081050-phpapp02/85/Discrimination-de-courbes-par-SVM-81-320.jpg)





















































