Télécharger en tant que PDF, PPTX













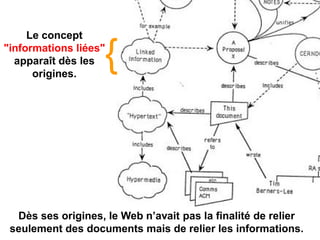
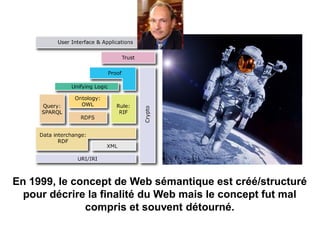

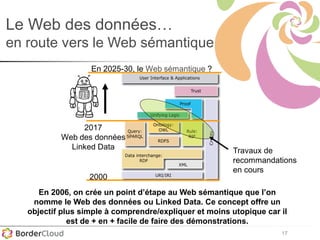









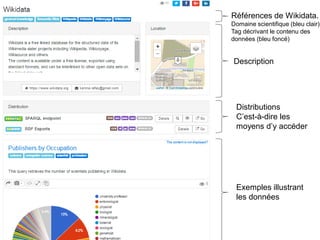
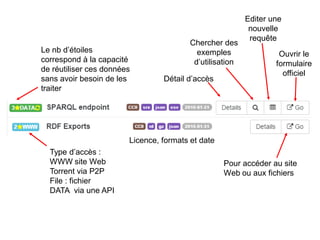
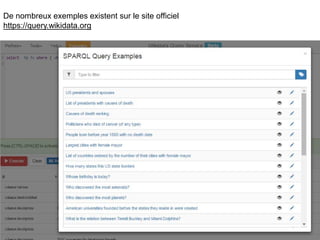
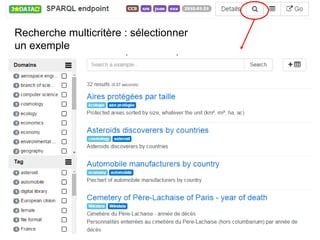
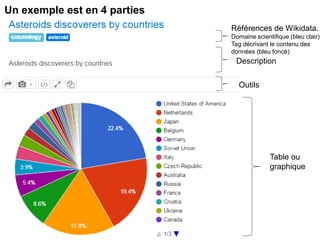
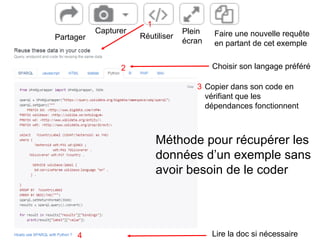
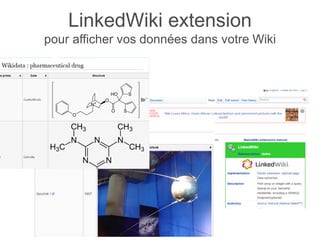
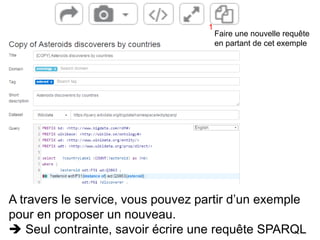



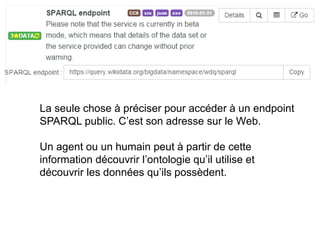
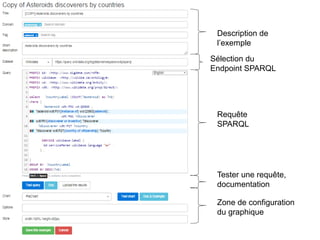

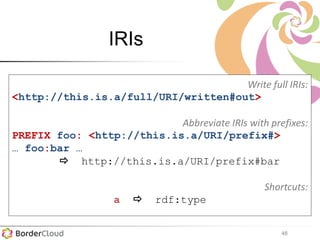
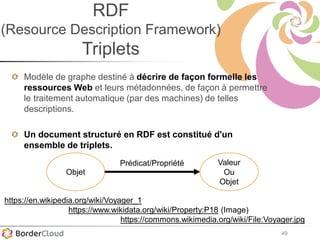

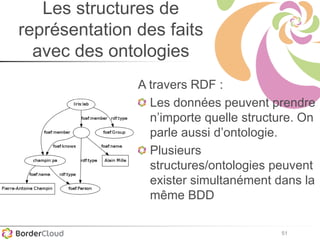
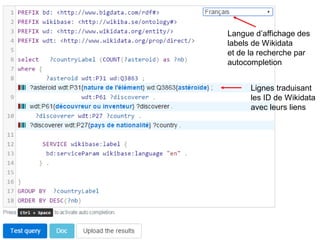
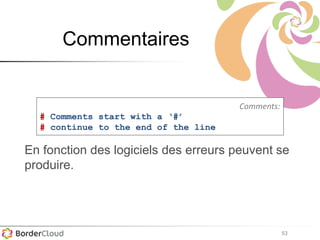
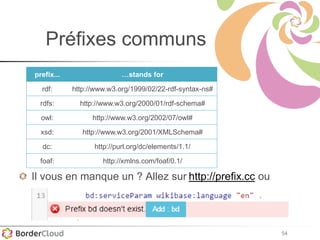
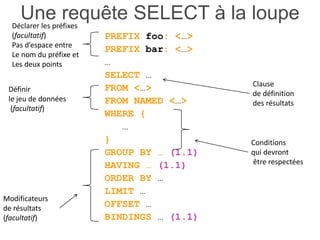











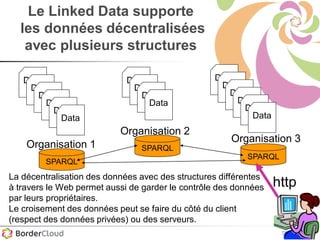





Karima Rafes présente une initiation à SPARQL et à Wikidata à travers des ateliers proposés par Bordercloud, une entreprise qu'elle a fondée. Le document décrit les services offerts par Bordercloud, notamment des formations en web sémantique et conseils, ainsi que des projets de R&D sur des plateformes liées à la gestion des données. L'atelier inclut des exercices pratiques sur l'interrogation de données avec SPARQL et la conception de nouveaux services basés sur des données ouvertes.















































