Plan
Introduction àl’informatique décisionnelle
Les entrepôts de données
Alimentation
Modélisation multidimensionnelle
Modélisation multidimensionnelle
Conception d’un DW
Démonstration
3.
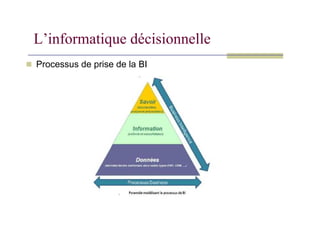
Besoin: prise dedécisions stratégiques et tactiques
Pourquoi: besoin de réactivité
Qui: les décideurs (non informaticiens, non statisticiens)
Comment: répondre aux demandes d’analyse des données,
dégager des informations qualitatives nouvelles
Le contexte
Pourquoi et
comment le chiffre
d’affaire a
baissé?
Qui sont mes
meilleurs
clients?
A combien s’élèvent
mes ventes
journalières?
Quels tunisiens
consomment
beaucoup de
poisson?
4.
Trop d’information tuel’information
La capacité de l’absorption de l’information par le cerveau humain
est limitée à 800 informations (mot, son, couleur, mouvement…) par
minute.
5.
Trop d’information tuel’information
Une étude scientifique a également
montré qu’un manager de haut
niveau réceptionne en moyenne
4000 informations par minute.
Étant donné que la mémoire de
court terme d’un être humain
normalement constitué ne lui permet
de mémoriser que ce qui a été dit durant les 50 dernières secondes. On
comprend mieux les difficultés éprouvées par les managers et leur
incapacité à traiter 100% de l’information qu’ils reçoivent.
6.
Problématique
Données opérationnelles(de production)
Bases de données (Oracle, SQL Server)
Fichiers, …
Paye, gestion des RH, gestion des commandes…
Caractéristiques de ces données:
Distribuées: systèmes éparpillés
Hétérogènes: systèmes et structures de données différents
Détaillées: organisation des données selon les processus
fonctionnels, données surabondantes pour l’analyse
Peu/pas adaptées à l’analyse : les requêtes lourdes peuvent
bloquer le système transactionnel
Volatiles: pas d’historisation systématique
7.
Problématique
Comment sélectionneret transformer les données de production en
informations fiables, homogènes, utiles et accessibles par un traitement
rapide, efficace et productif ?
8.
Solutions
Disposer d’unoutil qui permet de :
Ramener l’information à l’essentiel.
Transformer un système d’information qui avait une vocation de
production en système d’information décisionnel.
Transformer des données de production en informations
Transformer des données de production en informations
stratégiques.
La BI (informatique décisionnelle) recouvre
l’ensemble des technologies permettant de
gérer et d’exploiter les informations disponibles,
en particulier, le DW permet de stocker ces
informations stratégiques.
9.
L’informatique décisionnelle
Termeanglais: Business intelligence (BI)
Définition 1: c’est la branche de l’informatique qui permet l'exploitation
des données de l'entreprise dans le but de faciliter la prise de décision.
C'est-à-dire, la compréhension du fonctionnement actuel et l'anticipation
des actions pour un pilotage éclairé de l'entreprise.
Définition 2: désigne les moyens, les outils et les méthodes qui
Définition 2: désigne les moyens, les outils et les méthodes qui
permettent de collecter, consolider, modéliser et restituer les données,
matérielles ou immatérielles, d'une entreprise en vue d'offrir une aide à la
décision et de permettre aux responsables de la stratégie d'entreprise
d’avoir une vue d’ensemble de l’activité traitée.
Objectifs:
Vision globale de l’activité
Aide à la décision
Basée sur un entrepôt de données pour stocker des données
transverses provenant de plusieurs sources hétérogènes.
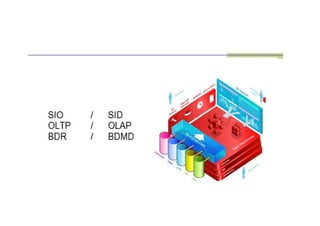
SIO/SID
SIO
système deproduction
Informatique opérationnelle
représente aujourd'hui la majeure partie du SI
focalisé sur le fonctionnement courant
procédures répétitives
transactions
transactions
données élémentaires
Utilisation des bases de données relationnelles normalisées
Limites du SIO
données détaillées surabondantes et peu lisibles, absence de synthèses
mauvaise qualité informationnelle
compartimentage, absence de sémantique commune, incohérences
manque de recul historique
contenu très riche,
faible valeur informationnelle
14.
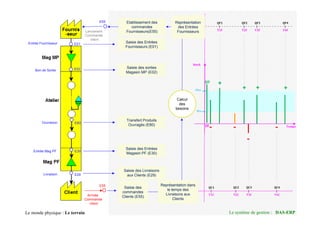
Entrée Fournisseur
Bon deSortie
E01
E02
Saisie des Entrées
Fournisseurs (E01)
Saisie des sorties
Magasin MP (E02)
Calcul
des
besoins
Etablissement des
commandes
Fournisseurs(E55)
E55
Lancement
Commande
client
Max
Min
QF1
|
T1F
QF2
|
T2F
QF3
|
T3F
QF4
|
T4F
Q0 +
+ + +
Représentation
des Entrées
Fournisseurs
Stock
Ouvraison E80
Entrée Mag PF E30
Livraison E29
Transfert Produits
Ouvragés (E80)
Saisie des Entrées
Magasin PF (E30)
Saisie des Livraisons
aux Clients (E29)
E55
Arrivée
Commande
client
Saisie des
commandes
Clients (E55)
Représentation dans
le temps des
Livraisons aux
Clients
QC1
|
T1C
QC2
|
T2C
QC3
|
T3C
QC4
|
T4C
- -
-
-
Le monde physique : Le terrain Le système de gestion : DAS-ERP
t0 Temps
15.
SIO/SID
Définition 1: UnSID est un système capable d'agréger
les données internes ou externes et de les transformer
en informations servant à une prise de décision.
Définition 2: Un SID est un ensemble de technologies destinées à permettre aux
collaborateurs d’accéder et comprendre les données de pilotage plus rapidement,
de telle sorte qu’ils prennent des décisions meilleures et plus rapides pour atteindre
les objectifs de son organisation.
16.
SIO/SID
SID
Informatique décisionnelle
destiné uniquement à produire de l'information et non à automatiser des opérations
découplé du SIO mais alimenté par le SIO
transforme les données pour améliorer leur valeur informationnelle
potentiellement concerné par tous les types de données
Modélisation dimensionnelle
Modélisation dimensionnelle
Entrepôts de données, magasin de données
Limites du SID
aller-retour SIO-SID malcommodé
besoins flous et changeants
prédominance des données internes
manque de données instantanées
Dénormalisation des bases de données
17.
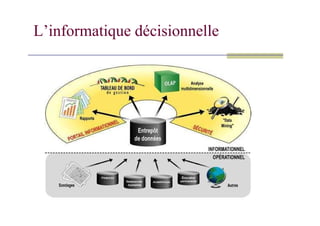
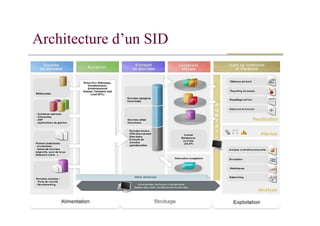
Trois couches :alimentation, stockage, restitution
ETL (Extract Transform Load)
Récupère des données hétérogènes, les transforme et les charge.
Entrepôt de données
Stockage intelligent de l’information, associé à des outils de «navigation»
Architecture d’un SID
Stockage intelligent de l’information, associé à des outils de «navigation»
dans les données.
Outils de restitution
Rapports prédéfinis, outils de requêtage, reporting de masse, tableaux de
bord dynamiques, …
Un «portail» pour fédérer l’ensemble
Point d’entrée unique pour l’ensemble des applications.
Gestion des droits d’accès en fonction du profil de l’utilisateur.
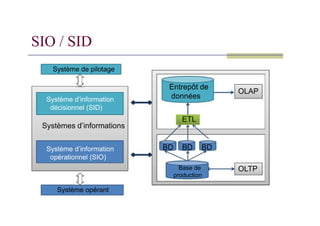
SIO / SID
Systèmede pilotage
Système d’information
décisionnel (SID)
Entrepôt de
données
OLAP
Systèmes d’informations
Système d’information
opérationnel (SIO)
Système opérant
ETL
OLTP
Base de
production
BD
BD
BD
20.
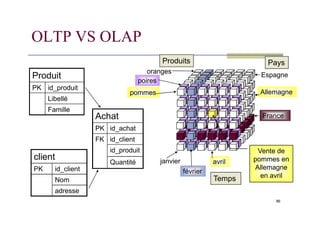
OLTP/OLAP
Les applications informatiquespeuvent être classées en deux catégories :
Applications OLTP (On-Line Transactional Processing)
Applications OLAP (On-Line Analytical Processing)
21.
OLTP/OLAP
Applications OLTP :
L'intégrité et la sécurité des données sont privilégiées.
Requêtes simples
Utilisées par des services de production : commerciaux, administratifs, production,
etc..
Nécessitent la connaissance des structures des données.
Utilisent des bases de données de production (relationnelles)
Utilisent des bases de données de production (relationnelles)
Manipulent des données homogènes.
Nombre d'utilisateurs simultanés important.
Applications critiques.
Exemples d'applications :
Gestion bancaire
Systèmes de réservation
Gestion commerciale, personnel, production, etc.
Exemple de requête :
Le 15/01/2002 à 13h12, le client X a retiré 500DT du compte Y
22.
OLTP/OLAP
Applications OLAP :
Catégorie de traitements dédiés à l’aide à la décision dont des requêtes interactives
complexes sur des gros volumes de données.
L'analyse et la manipulation des données sont privilégiées.
Requêtes complexes
Applications d'aide à l'élaboration de stratégies
Utilisées par les DG, les services marketing, financiers, contrôleurs de gestion, etc..
Utilisées par les DG, les services marketing, financiers, contrôleurs de gestion, etc..
Ne nécessitent pas la connaissance des structures des données.
Utilisent des entrepôts de données (modèle multidimensionnel)
Manipulent des données hétérogènes.
Nombre d'utilisateurs simultanés faible.
Exemples d'applications :
Analyse des tendances
Analyse des comportements
Exemple de requête :
Quel est le volume des ventes par produit et par région durant le troisième trimestre
de 2002?
23.
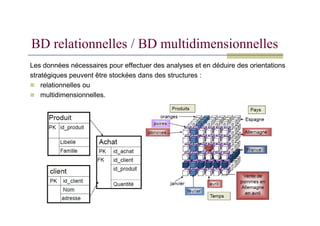
BD relationnelles /BD multidimensionnelles
Les données nécessaires pour effectuer des analyses et en déduire des orientations
stratégiques peuvent être stockées dans des structures :
relationnelles ou
multidimensionnelles.
24.
Bases de donnéesrelationnelles
Structure tabulaire.
Croisement des données à l'aide des jointures.
Pas de redondance (doublons, agrégation).
Les résultats de requêtes sont sous forme de listes.
Opérations : Sélectionner, ajouter, mettre à jour et supprimer des tuples.
BD relationnelles / BD multidimensionnelles
Structures peu adaptées aux applications de type OLAP.
Bases de données multidimensionnelles
Les données sont organisées selon des axes.
Hypercube comprend autant de dimensions que d'axes d'analyse.
Possibilité de redondance des données.
Les requêtes peuvent exploiter toutes les combinaisons d'axes.
Temps d'accès stable.
Moins de risque d'erreurs dans la formulation des requêtes.
Langage MDX = Multidimensional Expressions (de Microsoft OLE DB for OLAP)
Structures bien adaptées aux applications de type OLAP.
25.
Plan
Introduction àl’informatique décisionnelle
Les entrepôts de données
Alimentation
Modélisation multidimensionnelle
Modélisation multidimensionnelle
Conception d’un DW
Démonstration
26.
Introduction-Problématique
Une grande massede données :
Distribuée
Hétérogène
Très détaillée
À traiter :
À traiter :
Synthétiser / Résumer
Visualiser
Analyser
Pour une utilisation par :
Des experts et des analystes d'un métier
NON informaticiens
NON statisticiens
27.
Introduction-Problématique
Comment répondre auxbesoins des décideurs afin d’améliorer les
performances décisionnelles de l’entreprise?
En donnant un accès rapide et simple à l’information stratégique.
En donnant du sens aux données.
En donnant une vision transversale des données de l’entreprise (intégration
de différentes bases de données).
En extrayant, groupant, organisant, corrélant et transformant (résumé,
agrégation) les données.
28.
Introduction-Solution
Mettre enplace un SI dédié aux applications décisionnelles : un
entrepôt de données (datawarehouse).
Transformer des données de production en informations
stratégiques.
29.
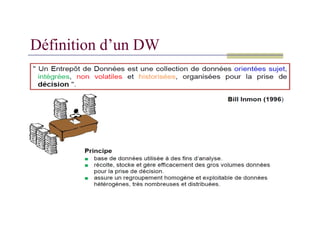
Entrepôt de Données
LeDW est un système d’information dédié aux applications décisionnelles situé en :
Aval des bases de production (bases opérationnelles)
Amont des prises de décision basées sur des indicateurs (Key Business Indicators (KBI))
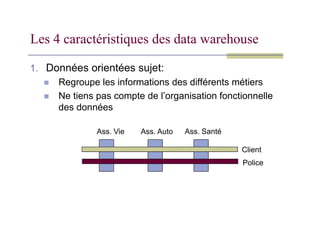
1. Données orientéessujet:
Regroupe les informations des différents métiers
Ne tiens pas compte de l’organisation fonctionnelle
des données
Les 4 caractéristiques des data warehouse
Ass. Vie Ass. Auto Ass. Santé
Client
Police
32.
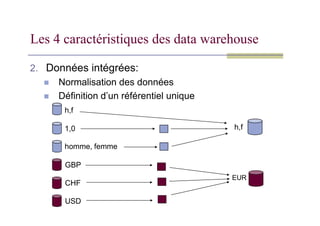
2. Données intégrées:
Normalisation des données
Définition d’un référentiel unique
h,f
Les 4 caractéristiques des data warehouse
h,f
1,0
homme, femme
h,f
GBP
CHF
USD
EUR
33.
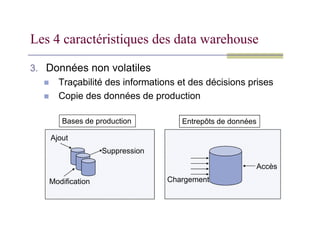
Les 4 caractéristiquesdes data warehouse
3. Données non volatiles
Traçabilité des informations et des décisions prises
Copie des données de production
Ventes
Donnée
s
clients
Ajout
Modification
Suppression
Accès
Chargement
Bases de production Entrepôts de données
34.
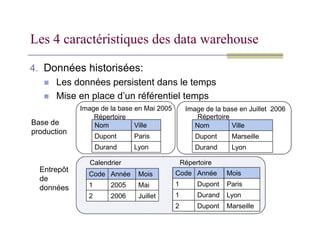
4. Données historisées:
Les données persistent dans le temps
Mise en place d’un référentiel temps
Image de la base en Mai 2005 Image de la base en Juillet 2006
Répertoire
Les 4 caractéristiques des data warehouse
Nom Ville
Dupont Paris
Durand Lyon
Nom Ville
Dupont Marseille
Durand Lyon
Code Année Mois
1 2005 Mai
Base de
production
Entrepôt
de
données
Calendrier
Code Année Mois
1 Dupont Paris
1 Durand Lyon
Répertoire
Répertoire
Répertoire
Code Année Mois
1 2005 Mai
2 2006 Juillet
Code Année Mois
1 Dupont Paris
1 Durand Lyon
2 Dupont Marseille
35.
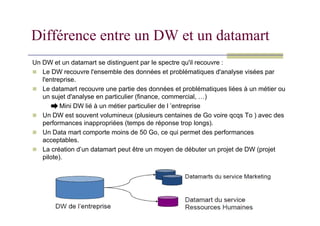
Différence entre unDW et un datamart
Un DW et un datamart se distinguent par le spectre qu'il recouvre :
Le DW recouvre l'ensemble des données et problématiques d'analyse visées par
l'entreprise.
Le datamart recouvre une partie des données et problématiques liées à un métier ou
un sujet d'analyse en particulier (finance, commercial, …)
Mini DW lié à un métier particulier de l ’entreprise
Un DW est souvent volumineux (plusieurs centaines de Go voire qcqs To ) avec des
Un DW est souvent volumineux (plusieurs centaines de Go voire qcqs To ) avec des
performances inappropriées (temps de réponse trop longs).
Un Data mart comporte moins de 50 Go, ce qui permet des performances
acceptables.
La création d’un datamart peut être un moyen de débuter un projet de DW (projet
pilote).
36.
Différence entre unDW et un datamart
Pourquoi des datamarts ?
Les datamarts sont destinés à pré-agréger des données disponibles de façon
plus détaillée dans les DW, afin de traiter plus facilement certaines questions
spécifiques, critiques, etc.
Exemple : Ticket de caisse
Si un DW enregistre un ensemble de ventes d'articles avec un grain très fin, un
datamart peut faciliter une analyse dite de ticket de caisse (co-occurrence de ventes
de produits par exemple) en adoptant un grain plus grossier (le ticket plutôt que
l'article).
37.
Catégories des donnéesstockées
Données dans un DW : données du SIO + BD externes (ETL).
Quatre catégories de données :
Les données de détail : issues des systèmes transactionnels de l’entreprise
socle de l’entreprise. Leur stockage permet d’offrir aux utilisateurs du SID les
détails des chiffres affichés, par exemple, sur un tableau de bord.
Les données agrégées : correspondent à des éléments d’analyse représentant
Les données agrégées : correspondent à des éléments d’analyse représentant
les besoins des utilisateurs. Elles constituent déjà un résultat d’analyse et une
synthèse de l’information contenue dans le système décisionnel, et doivent être
facilement accessibles et compréhensibles..
Les méta données : décrivent les caractéristiques des données stockées :
origine, date de dernière m-à-j, mode de calcul, procédure de transformation.
Elles sont utiles aussi bien aux utilisateurs (comprendre les données) qu’aux
administrateurs (fournir des moyens d’exploitation et de maintenance du DW).
Les données historisées : Couches de données dans lesquelles chaque
nouvelle insertion de données provenant du SIO ne détruit pas les anciennes
valeurs, mais créée une nouvelle occurrence de la donnée.
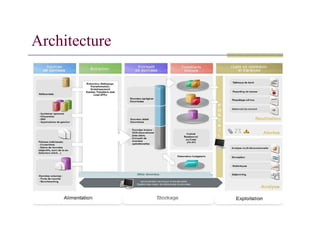
Architecture
Data Requêtes
Transformations:
Zone depréparation
Zone de
présentation
C
H
A
Zone de stockage
E
X
T
R
Data
warehouse
Requêtes
Rapports
Visualisation
Data Mining
…
Sources de
données
Transformations:
Nettoyage
Standardisation
…
Datamart
R
G
E
M
E
N
T
R
A
C
T
I
O
N
40.
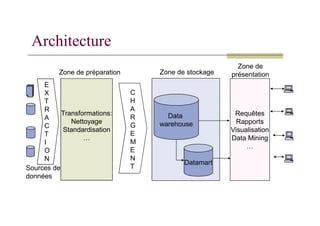
Les différentes zonesde l’architecture
Zone de préparation (Staging area)
Zone temporaire de stockage des données extraites
Réalisation des transformations avant l’insertion dans le DW:
Nettoyage
Normalisation…
Données souvent détruites après chargement dans le DW
Données souvent détruites après chargement dans le DW
Zone de stockage (DW, DM)
On y transfère les données nettoyées
Stockage permanent des données
Zone de présentation
Donne accès aux données contenues dans le DW
Peut contenir des outils d’analyse programmés:
Rapports
Requêtes…
41.
Les flux dedonnées
Flux entrant
Extraction: multi-source, hétérogène
Transformation: filtrer, trier, homogénéiser, nettoyer
Chargement: insertion des données dans l’entrepôt
Chargement: insertion des données dans l’entrepôt
Flux sortant:
Mise à disposition des données pour les utilisateurs
finaux
42.
Plan
Introduction àl’informatique décisionnelle
Les entrepôts de données
Alimentation
Modélisation multidimensionnelle
Modélisation multidimensionnelle
Conception d’un DW
Démonstration
43.
Alimentation/ mise àjour de l’entrepôt
Entrepôt mis à jour régulièrement
Besoin d’un outil permettant d’automatiser les chargements
dans l’entrepôt
Utilisation d’outils ETL (Extract, Transform, Load)
Utilisation d’outils ETL (Extract, Transform, Load)
44.
Définition d’un ETL
L’ETL est une couche logicielle responsable de l’alimentation d’une BD à
partir de sources de données.
Dans un SID, l’ETL sert à alimenter l’ED ou bien les magasins de données.
L’ETL fait partie des middlewares (intergiciels)
45.
Importance de l’ETL
Constitue 70 à 80% du temps passé dans un projet
décisionnel.
La qualité de l’ED dépend de la qualité de l’ETL :
Temps de chargement
Fréquence de chargement
Fréquence de chargement
Qualité des données
Qualité des services
46.
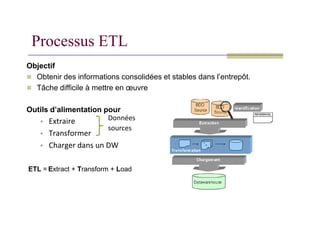
Processus ETL
Objectif
Obtenirdes informations consolidées et stables dans l’entrepôt.
Tâche difficile à mettre en œuvre
Outils d’alimentation pour
Outils d’alimentation pour
Extraire
Transformer
Charger dans un DW
Données
sources
ETL = Extract + Transform + Load
47.
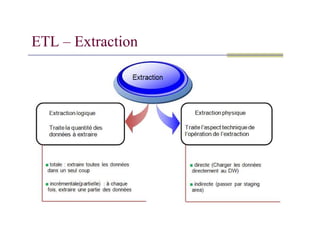
ETL – Extraction
Objectif : Identifier et localiser les données sources pertinentes (BDR,
fichiers, …) puis les collecter et les extraire des différents systèmes
opérationnels.
Fonctionnalités :
Traiter différents formats (XML, HTML, TXT, CSV, DB2, Oracle…).
Gérer les connexions aux sources (ODBC, JDBC...).
Gérer les connexions aux sources (ODBC, JDBC...).
Extraire le dictionnaire des sources (propriété des colonnes, clés…).
Extraire les données de manière performante et sans perturber les
environnements de production.
Détecter les données qui ont été modifiées dans les sources.
Ajouter des contrôles (fichier de rejets, audits…).
Stocker l’ensemble des règles d’extraction dans le référentiel.
Extraction complète:
Capturel'ensemble des données à un certain instant (snapshot de l'état opérationnel);
Normalement employée dans deux situations:
1. Chargement initial des données;
2. Rafraîchissement complet des données (ex: modification d'une source).
Peut être très coûteuse en temps (ex: plusieurs jours).
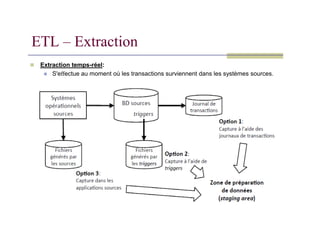
Extraction incrémentale:
ETL – Extraction
Extraction incrémentale:
Capture uniquement les données qui ont changées ou ont été ajoutées depuis la dernière
extraction;
Peut être faite de deux façons:
1. Extraction temps-réel;
2. Extraction différée (en lot).
Option 1: Captureà l'aide du journal des transactions
Utilise les logs de transactions de la BD servant à la récupération en cas de panne;
Aucune modification requise à la BD ou aux sources;
Doit être fait avant le rafraîchissement périodique du journal;
Option 2: Capture à l'aide de triggers
Des procédures déclenchées (triggers) sont définies dans la BD pour recopier les données à
ETL – Extraction
Des procédures déclenchées (triggers) sont définies dans la BD pour recopier les données à
extraire dans un fichier de sortie;
Meilleur contrôle de la capture d'évènements;
Exige de modifier les BD sources;
Option 3: Capture à l'aide des applications sources
Les applications sources sont modifiées pour écrire chaque ajout et modification de données
dans un fichier d'extraction;
Exige des modifications aux applications existantes;
Entraîne des coûts additionnels de développement et de maintenance;
52.
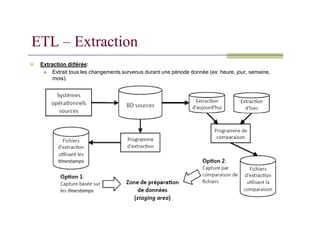
Extraction diff
ff
ff
fférée:
Extraittous les changements survenus durant une période donnée (ex: heure, jour, semaine,
mois).
ETL – Extraction
53.
Option 1: Capturebasée sur les timestamps
Une estampille (timestamp) d'écriture est ajoutée à chaque ligne des systèmes
sources;
L'extraction se fait uniquement sur les données dont le timestamp est plus récent
que la dernière extraction;
Option 2: Capture par comparaison de fichiers
ETL – Extraction
Option 2: Capture par comparaison de fichiers
Compare deux snapshots successifs des données sources;
Extrait seulement les déférences (ajouts, modifications, suppressions) entre les
deux snapshots;
Exige de conserver une copie de l'état des données sources;
Approche relativement coûteuse.
54.
Problématique
Existence deplusieurs sources
Non conformité des représentations
Découpages géographiques différents
5 à 30 % des données des BD commerciales sont erronées
Une centaine de type d’inconsistances ont été répertoriées
ETL – Transformation
Transformation : Étape importante garantissant que les données intégrées dans le DW
seront cohérentes et fiables.
Objectif:
Transformer les données sources selon les unités de mesure et les formats de l’ED.
Homogénéiser les données sources.
Nettoyer les données.
Suppression des incohérences sémantiques.
Dater les données.
Créer des clés.
55.
Types de transformation:
1.Révision de format:
Ex: Changer le type ou la longueur de champs individuels.
2. Décodage de champs:
• Consolider les données de sources multiples
Ex: ['homme', 'femme'] vs ['M', 'F'] vs [1,2].
• Traduire les valeurs cryptiques
ETL – Transformation
• Traduire les valeurs cryptiques
Ex: 'AC', 'IN', 'SU' pour les statuts actif, inactif et suspendu.
3. Pré-calcul des valeurs dérivées:
Ex: profit calculé à partir de ventes et coûts.
4. Découpage de champs complexes:
Ex: extraire les valeurs prénom, secondPrénom et nomFamille à partir d'une seule
chaîne de caractères nomComplet.
5. Fusion de plusieurs champs:
Ex: information d'un produit
- Source 1: code et description;
- Source 2: types de forfaits;
- Source 3: coût.
56.
6. Conversion dejeu de caractères:
Ex: EBCDIC (IBM) vers ASCII.
7. Conversion des unités de mesure:
Ex: impérial à métrique.
8. Conversion de dates:
Ex: '24 FEB 2011' vs '24/02/2011' vs '02/24/2011'.
ETL – Transformation
9. Pré-calcul des agrégations:
Ex: ventes par produit par semaine par région.
10. Déduplication
Ex: Plusieurs enregistrements pour un même client.
57.
Types de chargement:
1.Chargement initial:
- Se fait une seule fois lors de l'activation de l'entrepôt de données;
- Peut prendre plusieurs heures.
2. Chargement incrémental:
- Se fait une fois le chargement initial complété;
- Peut être fait en temps-réel ou en lot.
ETL – Chargement
- Peut être fait en temps-réel ou en lot.
3. Rafraîchissement complet:
- Est employé lorsque le nombre de changements rend le chargement incrémental
trop complexe;
Ex: lorsque plus de 20% des enregistrements ont changé depuis le dernier chargement.
58.
Fréquence de l’ETL
Dépend de :
la granularité de la dimension Temps
la disponibilité des données sources
la fréquence d’utilisation de l’ED
Dans certains cas, pour gagner du temps, on peut avoir une fréquence de
chargement inférieure à celle de la granularité de la dimension temps.
chargement inférieure à celle de la granularité de la dimension temps.
Exemple :
Granularité Temps = mois
Fréquence de chargement = jour
59.
Cycle de viede l’ETL
La mise en place de l’ETL passe par les étapes suivantes :
1. Conception de l’ETL :
Identification des sources de données
Correspondance des données
Définition des transformations
Définition des transformations
Structure de la zone d’attente
2. 1er chargement :
Chargement de toutes les données sources
3. Rafraichissement de l’ED :
Chargement périodique des données
Mise à jour de l’ETL lorsque les structures sources ou cibles changent
60.
La méthode pullet la méthode push
Techniques de détection des mises à jour effectuées sur la BD opérationnelle
et son envoi à l ’entrepôt pour sa mise à niveau ultérieure.
avec la méthode pull, c’est le SID qui recherche périodiquement les
données dans les BD opérationnelles. Cette méthode alimente le SID en
temps différé, cependant la quantité volumineuse de données à chaque
transfert peut être coûteuse en temps.
avec la méthode push, c’est le SIO qui au fil de l’eau de ses transactions
alimente le SID. Cette méthode alimente le SID en temps direct ce qui
oblige à revoir le code des applications opérationnelles.
61.
Plan
Introduction àl’informatique décisionnelle
Les entrepôts de données
Alimentation
Modélisation multidimensionnelle
Modélisation multidimensionnelle
Conception d’un DW
Démonstration
62.
Modélisation Entité/Association
Avantages:
Normalisation:
Éliminer les redondances
Préserver la cohérence des données
Optimisation des transactions
62
Optimisation des transactions
Réduction de l’espace de stockage
Inconvénients pour un utilisateur final:
Schéma très/trop complet:
Contient des tables/champs inutiles pour l’analyse
Pas d’interface graphique capable de rendre
utilisable le modèle E/A
Inadapté pour l’analyse
Modélisation des DW
Nouvelle méthode de conception autour des
concepts métiers
Ne pas normaliser au maximum
Introduction de nouveaux types de table:
64
Introduction de nouveaux types de table:
Table de faits
Table de dimensions
Introduction de nouveaux modèles:
Modèle en étoile
Modèle en flocon
65.
Table de faits
Table principale du modèle dimensionnel
Contient les données observables (les faits) sur le sujet
étudié selon divers axes d’analyse (les dimensions)
Table de faits des ventes
65
Table de faits des ventes
Clé date (CE)
Clé produit (CE)
Clé magasin (CE)
Quantité vendue
Coût
Montant des ventes
Clés étrangères
vers les
dimensions
Faits
66.
Table de faits(suite)
Fait:
Ce que l’on souhaite mesurer
Quantités vendues, montant des ventes…
Contient les clés étrangères des axes d’analyse
66
Contient les clés étrangères des axes d’analyse
(dimension)
Date, produit, magasin
Trois types de faits:
Additif
Semi additif
Non additif
67.
Typologie des faits
Additif: additionnable suivant toutes les dimensions
Quantités vendues, chiffre d’affaire
Peut être le résultat d’un calcul:
Bénéfice = montant vente - coût
Semi additif: additionnable suivant certaines
dimensions
67
dimensions
Solde d’un compte bancaire:
Pas de sens d’additionner sur les dates car cela
représente des instantanés d’un niveau
Σ sur les comptes: on connaît ce que nous possédons
en banque
Non additif: fait non additionnable quelque soit la
dimension
Prix unitaire: l’addition sur n’importe quelle dimension donne
un nombre dépourvu de sens
68.
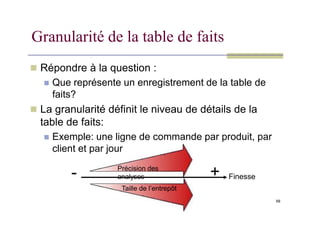
Granularité de latable de faits
Répondre à la question :
Que représente un enregistrement de la table de
faits?
La granularité définit le niveau de détails de la
68
La granularité définit le niveau de détails de la
table de faits:
Exemple: une ligne de commande par produit, par
client et par jour
Précision des
analyses
Taille de l’entrepôt
- + Finesse
69.
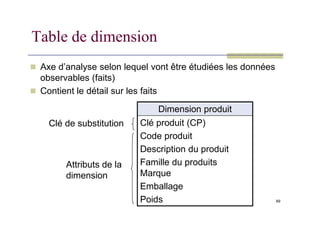
Table de dimension
Axe d’analyse selon lequel vont être étudiées les données
observables (faits)
Contient le détail sur les faits
Dimension produit
69
Dimension produit
Clé produit (CP)
Code produit
Description du produit
Famille du produits
Marque
Emballage
Poids
Clé de substitution
Attributs de la
dimension
70.
Table de dimension(suite)
Dimension = axe d’analyse
Client, produit, période de temps…
Contient souvent un grand nombre de colonnes
L’ensemble des informations descriptives des faits
70
Contient en général beaucoup moins
d’enregistrements qu’une table de faits
71.
La dimension Temps
Commune à l’ensemble du
DW
Reliée à toute table de
faits
Dimension Temps
Clé temps (CP)
Jour
Mois
71
Trimestre
Semestre
Année
Num_jour_dans_année
Num_semaine_ds_année
72.
Granularité d’une dimension
Une dimension contient des membres organisés
en hiérarchie :
Chacun des membres appartient à un niveau
hiérarchique (ou niveau de granularité) particulier
72
Granularité d’une dimension : nombre de niveaux
hiérarchiques
Temps :
année – semestre – trimestre - mois
Évolution des dimensions
Dimensions à évolution lente
Un client peut se marier, avoir des enfants…
Un produit peut changer de noms ou de
formulation:
74
formulation:
« Raider » en « Twix »
« yaourt à la vanille » en « yaourt saveur vanille »
Gestion de la situation, 3 solutions:
Écrasement de l’ancienne valeur
Versionnement
Valeur d’origine / valeur courante
Dimensions à évolution rapide
75.
Dimensions à évolutionlente (1/3)
Écrasement de l’ancienne valeur :
Correction des informations erronées
Avantage:
Facile à mettre en œuvre
Inconvénients:
75
Inconvénients:
Perte de la trace des valeurs antérieures des attributs
Perte de la cause de l’évolution dans les faits mesurés
Clé produit Description du produit Groupe de produits
12345 Intelli-Kids Logiciel
Jeux éducatifs
76.
Dimensions à évolutionlente (2/3)
Ajout d’un nouvel enregistrement:
Utilisation d’une clé de substitution
Avantages:
Permet de suivre l’évolution des attributs
Permet de segmenter la table de faits en fonction de
76
Permet de segmenter la table de faits en fonction de
l’historique
Inconvénient:
Accroit le volume de la table
Clé produit Description du produit Groupe de produits
12345 Intelli-Kids Logiciel
25963 Intelli-Kids Jeux éducatifs
77.
Dimensions à évolutionlente (3/3)
Ajout d’un nouvel attribut:
Valeur origine/valeur courante
Avantages:
Avoir deux visions simultanées des données :
Voir les données récentes avec l’ancien attribut
77
Voir les données récentes avec l’ancien attribut
Voir les données anciennes avec le nouvel attribut
Voir les données comme si le changement n’avait pas eu lieu
Inconvénient:
Inadapté pour suivre plusieurs valeurs d’attributs intermédiaires
Clé produit Description du
produit
Groupe de
produits
12345 Intelli-Kids Logiciel
Nouveau groupe
de produits
Jeux éducatifs
78.
Évolution des dimensions
Dimensions à évolution lente
Dimensions à évolution rapide
Subit des changements très fréquents (tous les
mois) dont on veut préserver l’historique
78
mois) dont on veut préserver l’historique
Solution: isoler les attributs qui changent
rapidement
79.
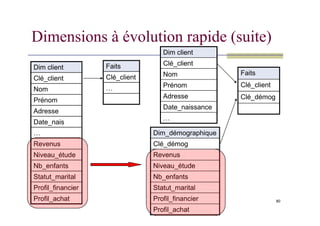
Dimensions à évolutionrapide
Changements fréquents des attributs dont on veut garder
l’historique
Clients pour une compagnie d’assurance
Isoler les attributs qui évoluent vite
79
80.
Dimensions à évolutionrapide (suite)
Dim client
Clé_client
Nom
Prénom
Adresse
Dim client
Clé_client
Nom
Prénom
Adresse
Date_naissance
Faits
Clé_client
…
Faits
Clé_client
Clé_démog
80
Dim_démographique
Clé_démog
Revenus
Niveau_étude
Nb_enfants
Statut_marital
Profil_financier
Profil_achat
Adresse
Date_nais
…
Revenus
Niveau_étude
Nb_enfants
Statut_marital
Profil_financier
Profil_achat
…
81.
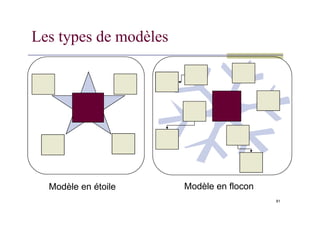
Les types demodèles
81
Modèle en étoile Modèle en flocon
82.
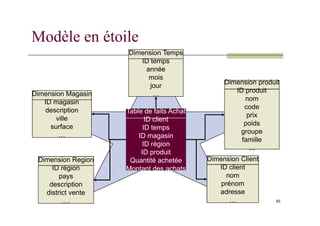
Modèle en étoile
Une table de fait centrale et des dimensions
Les dimensions n’ont pas de liaison entre elles
Avantages:
Facilité de navigation
82
Facilité de navigation
Nombre de jointures limité
Inconvénients:
Redondance dans les dimensions
Toutes les dimensions ne concernent pas les
mesures
83.
Modèle en étoile
DimensionTemps
…
Dimension Temps
ID temps
année
mois
jour
…
Dimension Magasin
Dimension Magasin
ID magasin
description
Dimension produit
Dimension produit
ID produit
nom
code
prix
Table de faits Achat
Table de faits Achat
83
…
description
ville
surface
…
Dimension Region
….
Dimension Region
ID région
pays
description
district vente
….
…
prix
poids
groupe
famille
…
Dimension Client
…
Dimension Client
ID client
nom
prénom
adresse
…
Montant des achats
Table de faits Achat
ID client
ID temps
ID magasin
ID région
ID produit
Quantité achetée
Montant des achats
84.
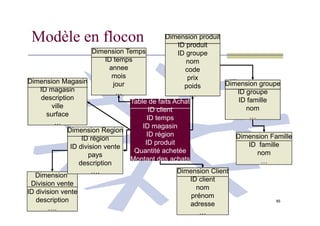
Modèle en flocon
Une table de fait et des dimensions décomposées en sous
hiérarchies
On a un seul niveau hiérarchique dans une table de
dimension
La table de dimension de niveau hiérarchique le plus bas
84
La table de dimension de niveau hiérarchique le plus bas
est reliée à la table de fait. On dit qu’elle a la granularité la
plus fine
Avantages:
Normalisation des dimensions
Économie d’espace disque
Inconvénients:
Modèle plus complexe (jointure)
Requêtes moins performantes
85.
Modèle en flocon
DimensionTemps
…
Dimension Temps
ID temps
annee
mois
jour
…
Dimension Magasin
Dimension Magasin
ID magasin
description
ville
surface
Dimension produit
…
Dimension produit
ID produit
ID groupe
nom
code
prix
poids
…
Dimension groupe
Dimension groupe
ID groupe
ID famille
nom
…
Table de faits Achat
Table de faits Achat
ID client
85
…
surface
…
Dimension Client
…
Dimension Client
ID client
nom
prénom
adresse
…
…
…
Dimension Famille
…
Dimension Famille
ID famille
nom
…
Dimension
….
Dimension
Division vente
ID division vente
description
….
Dimension Region
….
Dimension Region
ID région
ID division vente
pays
description
….
Montant des achats
ID client
ID temps
ID magasin
ID région
ID produit
Quantité achetée
Montant des achats
ROLAP
Relational OLAP
Données stockées dans une base de données
relationnelles
Un moteur OLAP permet de simuler le
87
comportement d’un SGBD multidimensionnel
Plus facile et moins cher à mettre en place
Moins performant lors des phases de calcul
Exemples de moteurs ROLAP:
Mondrian
88.
MOLAP
Multi dimensionalOLAP:
Utiliser un système multidimensionnel « pur » qui
gère les structures multidimensionnelles natives
(les cubes)
Accès direct aux données dans le cube
88
Accès direct aux données dans le cube
Plus difficile à mettre en place
Formats souvent propriétaires
Conçu exclusivement pour l’analyse
multidimensionnelle
Exemples de moteurs MOLAP:
Microsoft Analysis Services
Hyperion
89.
HOLAP
Hybride OLAP:
tables de faits et tables de dimensions stockées
dans SGBD relationnel (données de base)
données agrégées stockées dans des cubes
89
Solution hybride entre MOLAP et ROLAP
Bon compromis au niveau coût et performance
90.
Le cube
Modélisationmultidimensionnelle des données
facilitant l’analyse d’une quantité selon différentes
dimensions:
Temps
90
Localisation géographique
…
Les calculs sont réalisés lors du chargement ou
de la mise à jour du cube
91.
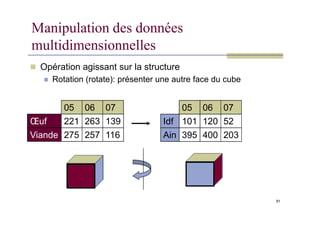
Manipulation des données
multidimensionnelles
Opération agissant sur la structure
Rotation (rotate): présenter une autre face du cube
05 06 07 05 06 07
91
Œuf 221 263 139
Viande 275 257 116
Idf 101 120 52
Ain 395 400 203
92.
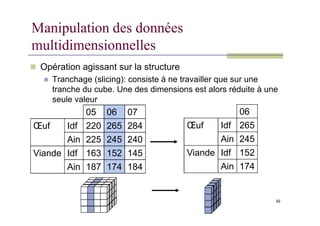
Manipulation des données
multidimensionnelles
Opération agissant sur la structure
Tranchage (slicing): consiste à ne travailler que sur une
tranche du cube. Une des dimensions est alors réduite à une
seule valeur
06
05 06 07
92
06
Œuf Idf 265
Ain 245
Viande Idf 152
Ain 174
05 06 07
Œuf Idf 220 265 284
Ain 225 245 240
Viande Idf 163 152 145
Ain 187 174 184
93.
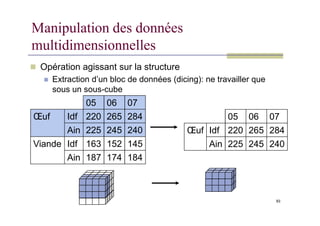
Manipulation des données
multidimensionnelles
Opération agissant sur la structure
Extraction d’un bloc de données (dicing): ne travailler que
sous un sous-cube
05 06 07
Œuf Idf 220 265 284 05 06 07
93
Œuf Idf 220 265 284
Ain 225 245 240
Viande Idf 163 152 145
Ain 187 174 184
05 06 07
Œuf Idf 220 265 284
Ain 225 245 240
94.
Manipulation des données
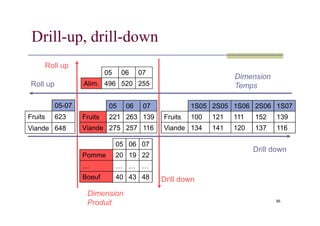
multidimensionnelles
Opération agissant sur la granularité
Forage vers le haut (roll-up): « dézoomer »
Obtenir un niveau de granularité supérieur
Utilisation de fonctions d’agrégation
Forage vers le bas (drill-down): « zoomer »
94
Forage vers le bas (drill-down): « zoomer »
Obtenir un niveau de granularité inférieur
Données plus détaillées
95.
05-07
Fruits 623
1S05 2S051S06 2S06 1S07
05 06 07
05 06 07
Alim. 496 520 255
Roll up
Dimension
Temps
Roll up
Drill-up, drill-down
95
Fruits 623
Viande 648
Fruits 100 121 111 152 139
Viande 134 141 120 137 116
Fruits 221 263 139
Viande 275 257 116
05 06 07
Pomme 20 19 22
… … … …
Boeuf 40 43 48 Drill down
Dimension
Produit
Drill down
96.
MDX (Multidimensional Expressions)
Langage permettant de définir, d'utiliser et de récupérer
des données à partir d'objets multidimensionnels
Permet d’effectuer les opérations décrites précédemment
Equivalent de SQL pour le monde OLAP
Origine: Microsoft
96
Origine: Microsoft
97.
MDX, exemple
Fournirles effectifs d’une société pendant les années 2004
et 2005 croisés par le type de paiement
SELECT {([Time].[2004]), ([Time].[2005])} ON COLUMNS,
{[Pay].[Pay Type].Members} ON ROWS
97
Dimensions,
axes d’analyse
{[Pay].[Pay Type].Members} ON ROWS
FROM RH
WHERE ([Measures].[Count])
Cube
2004 2005
Heure 3396 4015
Jour 3678 2056




































![Types de transformation:
1. Révision de format:
Ex: Changer le type ou la longueur de champs individuels.
2. Décodage de champs:
• Consolider les données de sources multiples
Ex: ['homme', 'femme'] vs ['M', 'F'] vs [1,2].
• Traduire les valeurs cryptiques
ETL – Transformation
• Traduire les valeurs cryptiques
Ex: 'AC', 'IN', 'SU' pour les statuts actif, inactif et suspendu.
3. Pré-calcul des valeurs dérivées:
Ex: profit calculé à partir de ventes et coûts.
4. Découpage de champs complexes:
Ex: extraire les valeurs prénom, secondPrénom et nomFamille à partir d'une seule
chaîne de caractères nomComplet.
5. Fusion de plusieurs champs:
Ex: information d'un produit
- Source 1: code et description;
- Source 2: types de forfaits;
- Source 3: coût.](https://image.slidesharecdn.com/lesentreptsdedonnes-cours-250411184332-544f7dfe/85/Les-entrepots-de-Donnees-cours-pdf-Datawarehouse-55-320.jpg)





























![MDX, exemple
Fournir les effectifs d’une société pendant les années 2004
et 2005 croisés par le type de paiement
SELECT {([Time].[2004]), ([Time].[2005])} ON COLUMNS,
{[Pay].[Pay Type].Members} ON ROWS
97
Dimensions,
axes d’analyse
{[Pay].[Pay Type].Members} ON ROWS
FROM RH
WHERE ([Measures].[Count])
Cube
2004 2005
Heure 3396 4015
Jour 3678 2056](https://image.slidesharecdn.com/lesentreptsdedonnes-cours-250411184332-544f7dfe/85/Les-entrepots-de-Donnees-cours-pdf-Datawarehouse-97-320.jpg)















































