Téléchargé 246 fois
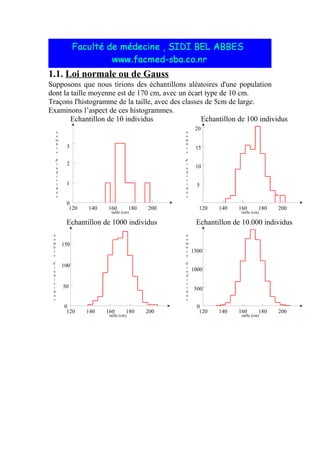
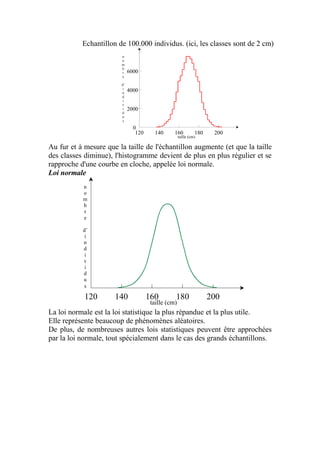
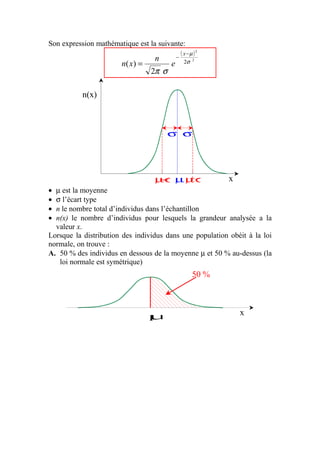
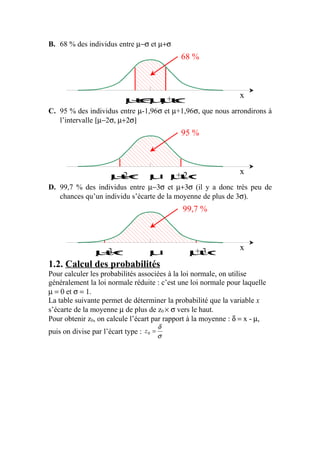

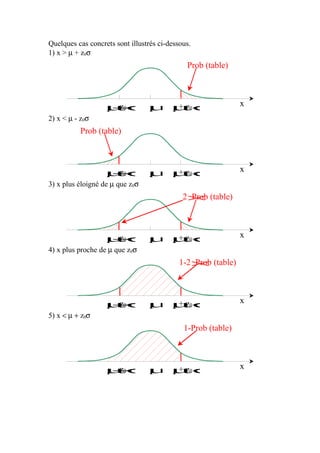



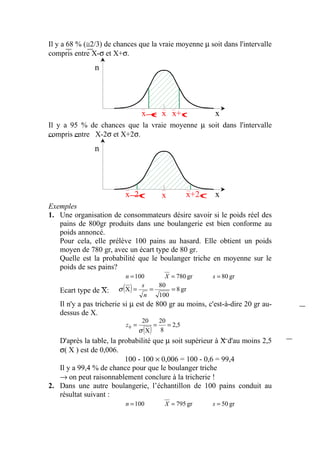

















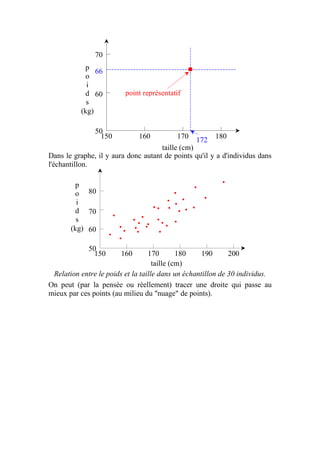
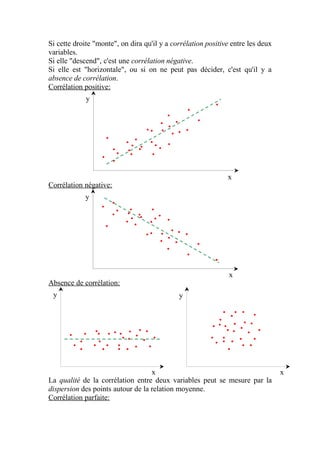



Le document explique la loi normale, un modèle statistique fondamental décrivant des phénomènes aléatoires. Il aborde la création d'histogrammes, les propriétés de la loi normale et comment utiliser des tables de probabilités associées. Enfin, il illustre des exemples pratiques d'application de la loi normale pour calculer des probabilités liées à des échantillons.
















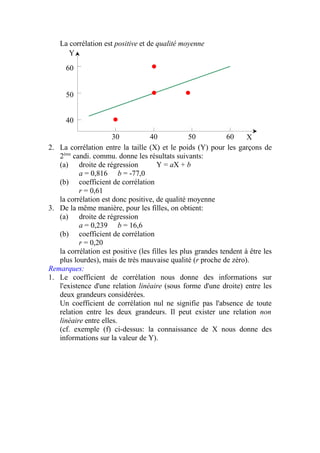
![Les systèmes de sante dans le monde [mode de compatibilité]](https://cdn.slidesharecdn.com/ss_thumbnails/lessystmesdesantedanslemondemodedecompatibilit-170813131709-thumbnail.jpg?width=640&height=640&fit=bounds)

























