Ce document traite de l'utilisation de R pour l'analyse de données dans le cadre d'une étude pratique, en abordant des sujets tels que la gestion de bases de données, la mise en forme des données, et l'application de modèles statistiques. Il présente des étapes clés, allant de la saisie des données à l'exportation des résultats, tout en mettant en évidence les défis rencontrés lors de l'intégration avec MySQL. La discussion inclut également des astuces pour optimiser l'utilisation de R dans le contexte des analyses statistiques quotidiennes.







![9
head(bddtot)
id_point cespece taillefixee_saisie taillestandard_saisie St_larvaire zoom eff convzoom
1295 337 GAR 88 84 1 1.25 5099 0.08081
1296 337 GAR 77 73 1 1.25 5099 0.08081
1297 337 GAR 94 90 1 1.60 5099 0.06316
1298 337 GAR 83 79 1 1.25 5099 0.08081
1299 337 GAR 90 86 1 1.25 5099 0.08081
1300 337 GAR 89 84 1 1.25 5099 0.08081
taillefixee taillestandard
1295 7.11 6.79
1296 6.22 5.90
1297 5.94 5.68
1298 6.71 6.38
1299 7.27 6.95
1300 7.19 6.79
write.csv(
data.frame(
sql=apply(bddtot,1,
function(x) x <-
paste("INSERT INTO bp_poisson (id_point, cespece, taille,saisie,
taillefixee,taillestandard,taille_saisie,St_larvaire,
taillestandard_saisie,taillefixee_saisie,zoom)",
" VALUES(",x[1],",'",x[2],"',","0.00,-1,",x[9],
",",x[10],",0.00,",x[5],",",x[4],",",x[3],",'",x[6],"');",
"UPDATE bp_poisson SET saisie =
WHERE saisie = -1;",sep="")
)
)
,file="requeteSQL_ss_ech.csv",quote=FALSE,row.names=FALSE)
Base de données
- saisie -
Saisieexcel](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-9-320.jpg)
![10
write.csv(
data.frame(
sql=apply(bddtot,1,
function(x) x <-
paste("INSERT INTO bp_poisson (id_point, cespece, taille,saisie,
taillefixee,taillestandard,taille_saisie,St_larvaire,
taillestandard_saisie,taillefixee_saisie,zoom)",
" VALUES(",x[1],",'",x[2],"',","0.00,-1,",x[9],
",",x[10],",0.00,",x[5],",",x[4],",",x[3],",'",x[6],"');",
"UPDATE bp_poisson SET saisie =
WHERE saisie = -1;",sep="")
)
)
,file="requeteSQL_ss_ech.csv",quote=FALSE,row.names=FALSE)
Base de données
- saisie -
sql
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.22,12.00,0.00,2, 81.0, 96.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.07,12.89,0.00,2, 87.0, 95.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,13.63,12.59,0.00,2, 85.0, 92.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,12.74,11.85,0.00,2, 80.0, 86.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.07,13.04,0.00,2, 88.0, 95.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.07,12.89,0.00,2, 87.0, 95.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.67,13.63,0.00,2, 92.0, 99.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.37,13.33,0.00,2, 90.0, 97.0,'0.7')
INSERT INTO bp_poisson (id_point, cespece, taille,saisie,taillefixee,taillestandard,taille_saisie,St_larvaire,taillestandard_saisie,taillefixee_saisie,zoom) VALUES(1021,'HOT',0.00,-1,14.67,13.33,0.00,2, 90.0, 99.0,'0.7')
• 60 000 requêtes unitaires
générées en un script
• Insertion dans la BDD via
phpmyadmin](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-10-320.jpg)

![12/06/2013 Utiliser R au quotidien 12
Mise en forme des données
- package plyr -require(plyr)
for (m in 1:nlevels(edfjuvtaille_4sp$id_secteur)){
site <-
subset(edfjuvtaille_4sp,id_secteur==levels(edfjuvtaille_4sp$id_secteur)[m]
& typeStation=="RCC")
nomsite <- levels(edfjuvtaille_4sp$id_secteur)[m]
for (k in 1:nlevels(edfjuvtaille_4sp$id_campagne)){
camp <- subset(site,id_campagne==levels(site$id_campagne)[k])
nomcamp <- levels(edfjuvtaille_4sp$id_campagne)[k]
for (i in 1:nlevels(camp$cespece)){
sp <- subset(camp,cespece==levels(camp$cespece)[i] & LS<110)
nomsp <- levels(camp$cespece)[i]
sp$LS[sp$LS>=40] <- ((sp$LS[sp$LS>=40]-40)/3)+40
hist_global <- hist(sp$LS,breaks=clas1,plot=F,warn.unused =
FALSE,freq=T)
hist_global$counts <- sqrt(hist_global$counts) #échelle rac. carrée
bmp(paste("1histo",nomsp,"_",nomsite,nomcamp,"RCC.bmp",sep=""),width=1100)
par(las=1,lwd=1,mar=c(5,5,3,1),cex.axis=1.5,cex.lab=1.5,bty='n',mgp=c(2.5,1
,0))
if(nrow(sp)!=0){
plot(1,type='n',xlim=c(0,70),ylim=c(0,round_any(max(hist_global$counts),5,c
eiling)),xlab="Taille (mm)",ylab="nb. (sqrt scale)",yaxt='n',xaxt='n')
a <- (seq(50,120,by=10)-40)/3+40
axis(1,pos=c(0,0),at=c(seq(0,40,by=5),a),labels=c(seq(0,40,by=5),seq(50,120
,by=10)))
axis(2,pos=c(0,0),at=seq(0,round_any(max(hist_global$counts),5,ceiling),by=
5),labels=seq(0,round_any(max(hist_global$counts),5,ceiling),by=5)^2)
text(35,round_any(max(hist_global$counts),5,ceiling),labels=paste("C",k,":
",datep_peage$PRCC1[k,2],sep=""),cex=2,font=2)
legend(x=1,y=round_any(max(hist_global$counts),5,ceiling),pch=22,col=colSt,
legend=paste("St",0:5),pt.bg=colSt,pt.cex = 3,xpd=TRUE,cex=1.5)
for(j in 1:nlevels(sp$St_larvaire)){
options(warn=-1)
stade <- subset(sp,St_larvaire==levels(sp$St_larvaire)[j])
hist_st <- hist(stade$LS,breaks=clas1,freq=T,plot=F)
hist_st$counts <- sqrt(hist_st$counts)
lines(hist_st,col=rgb(t(col2rgb(colSt[j],alpha=T)),maxColorValue =
255,alpha=127),freq=T)
options(warn=0)
}
}
else{
a <- (seq(50,120,by=10)-40)/3+40
plot(1,type='n',xlim=c(0,70),ylim=c(0,10),xlab="Taille
(mm)",ylab="nb.",yaxt='n',xaxt='n')
axis(1,pos=c(0,0),at=c(seq(0,40,by=5),a),labels=c(seq(0,40,by=5),seq(50,120
,by=10)))
axis(2,pos=c(0,0),at=seq(0,10,by=5),labels=seq(0,10,5))
Distribution de taille
Objectif : obtenir les distributions de
taille par espèce à chaque site et à
chaque date.
« mise en forme » est sous-jacente
(nécessaire à l’objectif)](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-12-320.jpg)
![12/06/2013 Utiliser R au quotidien 13
require(plyr)
for (m in 1:nlevels(edfjuvtaille_4sp$id_secteur)){
site <-
subset(edfjuvtaille_4sp,id_secteur==levels(edfjuvtaille_4sp$id_secteur)[m]
& typeStation=="RCC")
nomsite <- levels(edfjuvtaille_4sp$id_secteur)[m]
for (k in 1:nlevels(edfjuvtaille_4sp$id_campagne)){
camp <- subset(site,id_campagne==levels(site$id_campagne)[k])
nomcamp <- levels(edfjuvtaille_4sp$id_campagne)[k]
for (i in 1:nlevels(camp$cespece)){
sp <- subset(camp,cespece==levels(camp$cespece)[i] & LS<110)
nomsp <- levels(camp$cespece)[i]
sp$LS[sp$LS>=40] <- ((sp$LS[sp$LS>=40]-40)/3)+40
hist_global <- hist(sp$LS,breaks=clas1,plot=F,warn.unused =
FALSE,freq=T)
hist_global$counts <- sqrt(hist_global$counts) #échelle rac. carrée
bmp(paste("1histo",nomsp,"_",nomsite,nomcamp,"RCC.bmp",sep=""),width=1100)
par(las=1,lwd=1,mar=c(5,5,3,1),cex.axis=1.5,cex.lab=1.5,bty='n',mgp=c(2.5,1
,0))
if(nrow(sp)!=0){
plot(1,type='n',xlim=c(0,70),ylim=c(0,round_any(max(hist_global$counts),5,c
eiling)),xlab="Taille (mm)",ylab="nb. (sqrt scale)",yaxt='n',xaxt='n')
a <- (seq(50,120,by=10)-40)/3+40
axis(1,pos=c(0,0),at=c(seq(0,40,by=5),a),labels=c(seq(0,40,by=5),seq(50,120
,by=10)))
axis(2,pos=c(0,0),at=seq(0,round_any(max(hist_global$counts),5,ceiling),by=
5),labels=seq(0,round_any(max(hist_global$counts),5,ceiling),by=5)^2)
text(35,round_any(max(hist_global$counts),5,ceiling),labels=paste("C",k,":
",datep_peage$PRCC1[k,2],sep=""),cex=2,font=2)
legend(x=1,y=round_any(max(hist_global$counts),5,ceiling),pch=22,col=colSt,
legend=paste("St",0:5),pt.bg=colSt,pt.cex = 3,xpd=TRUE,cex=1.5)
for(j in 1:nlevels(sp$St_larvaire)){
options(warn=-1)
stade <- subset(sp,St_larvaire==levels(sp$St_larvaire)[j])
hist_st <- hist(stade$LS,breaks=clas1,freq=T,plot=F)
hist_st$counts <- sqrt(hist_st$counts)
lines(hist_st,col=rgb(t(col2rgb(colSt[j],alpha=T)),maxColorValue =
255,alpha=127),freq=T)
options(warn=0)
}
}
else{
a <- (seq(50,120,by=10)-40)/3+40
plot(1,type='n',xlim=c(0,70),ylim=c(0,10),xlab="Taille
(mm)",ylab="nb.",yaxt='n',xaxt='n')
axis(1,pos=c(0,0),at=c(seq(0,40,by=5),a),labels=c(seq(0,40,by=5),seq(50,120
,by=10)))
axis(2,pos=c(0,0),at=seq(0,10,by=5),labels=seq(0,10,5))
Mise en forme des données
- package plyr -
ddply(subset(edfjuvtaille_4sp,typeStation=="RCC"),~id_secteur+id_campagne+c
espece,
Allègement sensible
data
site
espèce
• Conserve le format global
• Ajout de colonne
• Synthèse (moyenne…)
• Toute sortie possible
• Il suffit de définir la fonction
• Plyr ≠ optimisation de temps de calcul
• Calcul parallèle possible (.parallel) avec les
packages foreach et doParallel
Mise en forme du
graphique](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-13-320.jpg)
![12/06/2013 Utiliser R au quotidien 14
Mise en forme des données
- package plyr -
Au final :
~300 graphiques générés dans un format commun
Phase suivante :
Les analyses stats
lines(hist_st,col=rgb(t(col2rgb(colSt[j],alpha=
T)),maxColorValue = 255,alpha=127),freq=T)
Transparence des couleurs : dépend du périphérique choisi
NB : pour les graphiques, toujours avoir un exemplaire de :
« Les paramètre graphiques ». Fiche tdr75 du pbil écrite par J. Lobry](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-14-320.jpg)
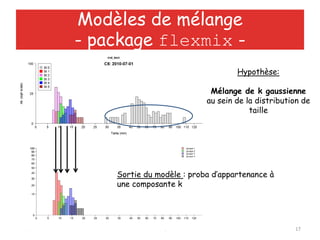
![12/06/2013 Utiliser R au quotidien 15
Modèles de mélange
- package flexmix -
ApparitiondeA
ApparitiondeB
chronique <- vector("list",4)
names(chronique) <- tps
chronique[[1]] <- rnorm(300,taillemu[1],taillesd[1])
chronique[[2]] <- rnorm(250,taillemu[2],taillesd[2])
chronique[[3]] <- rnorm(200,taillemu[3],taillesd[3])
chronique[[4]] <- rnorm(150,taillemu[4],taillesd[4])
chronique_hist <- lapply(chronique,
function(x) hist(x,plot=F,breaks=seq(0,55,by=1)))
N <- length(chronique_hist)
for(j in 2:N) {
HIST <- chronique_hist[[j]]
n <- length(HIST$counts)
for(i in 1:n){
y <- rep(tps[j],4)
x <- rep(HIST$breaks[c(i,i+1)],each=2)
z <- rep(c(0,HIST$counts[i]),2)
coord <- data.frame(x,y,z)
segments3d(coord,col='black')
y <- rep(tps[j],2)
x <- HIST$breaks[c(i,i+1)]
z <- rep(HIST$counts[i],2)
coord <- data.frame(x,y,z)
segments3d(coord)
}
}
rgl.postscript("test.eps")
Couleurs via logiciel graphique
- Possibilité via polygon()
On peut faire de la 3D sous R : exemple avec le package rgl
Théorie](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-15-320.jpg)
![12/06/2013 Utiliser R au quotidien 16
Modèles de mélange
- package flexmix -
stepflexmix(LS~1,data=ABLbaix2011[[i]][[2]],control=list(iter.max=1000,
classify="SEM"),concomitant=FLXPmultinom(~C(factor(St_larvaire,levels=1:6),
poly,1)),k=1:4)
• Mélange de différentes lois
• Chaque composante à un poids
• Prédicteurs pour
Les paramètres de chaque
composante
Le poids de chaque
composante
• Processus itératif pour tester 1
à k composantes
• Algorithme EM
• Sélection par AIC, BIC…](https://image.slidesharecdn.com/meetupjuin2013-130613114652-phpapp02/85/Meetup-juin2013-16-320.jpg)