Téléchargé 1 684 fois








![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Les méthodes descendantes sont basées essentiellement sur la technique « Run Length
Smoothing : Lissage direct en longueur » (connue aussi sous le nom de : Constrained run
length method) et la méthode des Projetions de Profiles. Le principal inconvénient des
méthodes descendantes est leur restriction sur des blocs rectangulaires donc elles ne sont pas
adéquates pour des documents contenant du texte ayant une mise en forme non régulière
(aléatoires / inclinaisons).
Les méthodes ascendantes sont des variantes typiques de la méthode des Composantes
Connexes. Les inconvénients de cette dernière se résument dans le fait qu’elle est dépendante
de la taille des caractères, elle est sensible à l’interligne et les espaces inter-caractères ainsi
qu’à sa sensibilité à la résolution. Cependant, elles ne sont pas restreintes aux blocs
rectangulaires comme les approches descendantes.
Une nouvelle méthode, différente des approches précédentes et palliant à leurs
limitations, n’ayant aucun besoin de connaissances à priori sur le document à traiter, a été
présentée par Jain et Bhattacharjee [3]. L’idée de base de cette approche est que les zones de
texte d’une image de document peuvent être considérées approximativement comme une
texture uniforme et les images forment une autre texture. Le document peut être alors
segmenté par un schéma de Segmentation de Texture.
La segmentation de texture reste toujours un sujet de base et important en traitement
d'images. Elle consiste à segmenter une image texturée en plusieurs régions ayant les mêmes
caractéristiques de texture; elle est bien et belle appliquée à l'analyse des images aériennes,
images biomédicales et des images sismiques, et récemment sur les images de documents
mais nécessitant une bonne définition et paramétrisation.
Tous comme les autres problèmes de segmentation, la segmentation de texture
nécessite l'identification des caractéristiques spécifiques propres à la texture avec un bon
pouvoir discriminant. Généralement, les méthodes d'extraction des caractéristiques peuvent
être classées en trois catégories de base : Statistique, Structurale et Spectrale.
Dans les approches statistiques, les statistiques des textures à base des moments de
l'histogramme des niveaux de gris ou à base de la matrice de co-occurrence, sont calculées
pour la discrimination entre les différentes textures. Pour les approches structurelles, 'une
primitive de texture', qui est l'élément de base de texture, est utilisée pour former un modèle de
texture plus complexe à l'aide de règles grammaticales qui spécifient et guident la génération
du modèle de texture en cours. Et enfin, les approches spectrales, l'image texturée est
transformée en domaine fréquentiel. Ensuite, l'extraction des caractéristiques de texture peut
être réalisée en analysant le pouvoir spectral.
Le schéma de segmentation de texture utilisé par Jain et Bhattacharjee [3] est
principalement le même que celui proposé par Jain et Farrokhnia ; une approche multicanaux
utilisant un banc de filtres de Gabor pré-sélectionnés en fréquences et orientations pour filtrer
une image d'entrée. Les caractéristiques extraites à partir des réponses des images filtrées, et
en se servant d'une fonction d'énergie locale et un découpage (Clustering) par un classifieur
non-supervisé, sont utilisées pour la segmentation et la classification de texture. Le filtre de
Gabor est le filtre le plus utilisé, par excellence, pour la segmentation de texture vu son
pouvoir discriminant paramétrable, cependant, l’inconvénient majeur de l’approche
gaborienne est sa complexité de calcul [2].
Laboratoire L3i – Université de La Rochelle Page 8](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-8-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Problématique / Contexte
La segmentation d’images de documents anciens en vue de les indexer est un sujet de
recherche.
Les documents anciens possèdent de nombreuses particularités qui ne permettent pas
d’appliquer les techniques classiques d’analyse de documents composites et d’OCR (Optical
Character Recognition) sur ces ouvrages. Ils sont dégradés, reposent sur les anciennes
techniques d’imprimerie et respectent donc des règles particulières de typographie et de mise
en forme [32].
Les différents problèmes posés par l’analyse des documents anciens en vue de leur
indexation sont assez proches de ceux que l’on trouve en analyse et interprétation d’images.
La chaîne de traitement comporte généralement un ensemble d’étapes visant à construire des
informations structurées à partir des informations numériques élémentaires (pixels de l'image)
et d’informations contextuelles liées à la nature du document analysé. Les objectifs sont donc
:
1) De séparer les différents composants situés sur les pages des ouvrages (texte, illustration,
lettrine,…)
2) L'objectif très ambitieux de recomposer le document, de comprendre son organisation et
même d'interpréter son contenu.
L'objet de cette étude consiste principalement à réaliser une étape primordiale dans
l'analyse de la structure physique des images de documents anciens à savoir leur
segmentation afin d'extraire les zones informatives (texte, Dessin, fond).
3) D’identifier les différents styles d’écriture (gras, italique, taille, manuscrit/imprimé…) pour
simplifier la tâche des systèmes d’OCR en créant des bases de modèles pour chacune des
familles détectées. On peut alors parler de reconnaissance adaptative.
Dans le présent travail, nous allons adopter l’outil Gabor pour définir un système de
segmentation d’images de documents anciens, qui soit alors une première tentative et un
premier pas dans la littérature des méthodes de segmentation d’images de documents anciens.
Ce mémoire se présentera comme suit :
En premier lieu, nous présenterons les propriétés des documents anciens, les méthodes
d’analyses qui existent dans la littérature et particulièrement l’analyse documentaire par
approche texture, ensuite nous donnerons une partie théorique complète du filtre de Gabor et
de son utilisation, pour finir cette partie par un descriptif de la méthode de classification non-
supervisée floue utilisée.
Ensuite, nous décrivons au détail près la conception et le fonctionnement de notre système
de segmentation d’images de documents anciens proposé que nous l’avons testé sur notre base
documentaire (contemporains et anciens), vous trouverez ainsi des résultats de nos tests.
Et enfin, nous clorons par une évaluation de notre système, et des résultats de
comparaison avec un outil de classification supervisée existant, des résultats seront présentés
et commentés ainsi que des perspectives et ouvertures de notre conception.
Laboratoire L3i – Université de La Rochelle Page 9](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-9-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
I. Au cœur des documents anciens
I.1. Introduction
Les documents anciens sont des documents d’archives rédigés à une autre époque et
obéissant donc à des règles typographiques et de composition différentes de celles appliquées
sur les documents modernes.
En effet, l’image d’un document ancien numérisée est souvent très tonale, à niveaux
de gris ou en couleur. Elle peut comprendre des annotations dans les marges, des illustrations,
des lettrines, voire même des écritures manuscrites [28].
Ces documents se caractérisent par des présentations et des écritures très variées,
variations dues à la multiplicité des styles et des techniques d’impression qui ont évolué au
cours du temps. L’usure du temps a de plus produit des altérations au document original et
l’image numérisée qui en découle contient alors des imperfections (taches, écritures
fragmentées) qui n’existent pas dans les documents plus modernes. Les documents anciens
imprimés, bien que présentant moins de variabilité, partagent un grand nombre des
caractéristiques des documents manuscrits [27].
Les techniques de traitement (ou analyse) des images de documents anciens, se situent
à différents niveaux : prétraitements, analyse et reconnaissance. Ces niveaux de traitements
utilisent ou produisent des structures de données à des niveaux de granularité de plus en plus
élevés : de l’image jusqu’à son interprétation. Si l’objectif ultime est celui de la
reconnaissance de tous les composants du document (graphiques et textuels), d’autres
objectifs concernent la visualisation de l’image pour en améliorer le déchiffrement, la
recherche de structures intermédiaires : blocs, lignes ou mots, et la séparation des couches
graphiques et symboliques. L’automatisation de la recherche des lignes de texte est
notamment une aide certaine à la création de liens texte/image dans les images de documents
anciens [27].
I.2. Traitement des images et documents anciens
La numérisation des documents anciens est un enjeu important pour les services
d’archives, les bibliothèques, les historiens et les chercheurs en sciences littéraires pour les
possibilités de manipulation, de visualisation et de recherche d’information qui en découlent.
La numérisation physique : scannérisation (ou digitalisation), consiste à créer une image du
document (un tableau de pixels), à l’aide d’une caméra numérique ou d’un scanneur. Une
haute résolution est souvent nécessaire (de300à 600dpi2) pour restituer les éléments les plus
fins de l’écriture et des graphismes. L’image obtenue est en couleur, en niveaux de gris ou
bitonale suivant les possibilités du capteur et les choix de numérisation. La question du format
de sauvegarde (ou stockage), dépend de l’application visée et de la taille du support de
conservation.
Quels sont les apports du traitement des images à la numérisation des documents anciens ?
Ils permettent de rechercher des informations directement dans les images, d’en dégager la
structure, d’en améliorer la qualité visuelle, et cela dans un mode automatique ou semi-
automatique.
Prétraitement
Les documents anciens posent en préambule un problème d’acquisition certain dû
d’une part à leur positionnement sur le scanner, créant des inclinaisons, des bombages et des
Laboratoire L3i – Université de La Rochelle Page 10](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-10-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
pliures du papier, et d’autre part à leur contenu hétérogène (texte imprimé, manuscrit…). Le
processus de vieillissement fait apparaître des taches d’humidité, la transparence de l’encre
sur les rectos, la fragmentation des contours fins, etc. Voici une liste de traitements usuels en
fonction des types de problèmes rencontrés (voir tableau 1).
Défaut Prétraitement
Faible ou forte luminosité Modification d’histogramme
*/Présence de taches */Filtrage passe haut
**/Filtrage passe-bas
**/Points parasites **/Filtrages morphologiques
Calcul de l’angle par projection
Rotation légère de l’image
Redressement par re-échantillonnage
*/Courbure de l’écriture sur un bord de */Calcul de la courbure locale
l’image */Re-échantillonnage
**/Filtrages (passe haut, passe-bas,
**/Ecriture fragmentée morphologiques)
Contours de l’écriture flous Filtrage passe haut, filtrage morphologique
Ecriture du verseau apparaissant sur le recto Combinaison des images recto et verso
TableauI.1. Liste des défauts et prétraitements appropriés, d’après L.Likfoman-Suelem[27].
I.2.1. Binarisation
L’opération de binarisation est parfois primordiale pour séparer le fond du texte si
l’image originale est en niveau de gris ou en couleur. Elle consiste à produire une image à
deux tons : clair pour le fond, et noir pour le texte. Il est nécessaire de conserver à la fois tous
les caractères et toutes les gravures sans toutefois récupérer trop de bruit [29]. Il existe
plusieurs algorithmes de binarisation (seuillage adaptatif, multi-résolution, morphologique,
classification des pixels,…). Ils apportent tous des avantages et des inconvénients en terme de
vitesse de calcul, de qualité de conservation des traits des caractères et de traits de gravures.
La plupart des méthodes conservent efficacement les caractères mais peuvent abîmer les
gravures ou inversement. Ces méthodes restent tributaires d’un ou de plusieurs seuils à
déterminer. Dans le cas des documents anciens, en général très hétérogènes, ces seuils restent
très difficiles à déterminer sans l’aide d’un expert.
Laboratoire L3i – Université de La Rochelle Page 11](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-11-320.jpg)

![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Etant réguliers et ayant une texture de caractères très homogène, le texte offre une norme pour
la classification. On utilise en général la largeur, la régularité et l’abondance des composantes
connexes pour la classification. Ainsi, dans un texte, les composantes connexes sont peu
larges, très régulières et très abondantes. Dans un graphique, les composantes connexes sont
très larges, pas régulières et peuvent être abondantes [28].
Il existe deux approches générales de segmentation :
°/La première suppose que les blocs sont homogènes (un seul média). Dans ce cas, chaque
bloc est classé dans le média le plus proche en fonction des caractéristiques textuelles
extraites de l’image du bloc.
°/ Dans la seconde approche, on suppose qu’un bloc contient un mélange texte/non texte
(mélange de graphiques et de texte). Dans ce cas, une analyse morphologique fine des
composantes connexes, aidées de connaissances a priori sur la position des éléments peut
aussi aider à localiser les différentes zones homogènes du document.
Les lignes de texte dans les documents anciens présentent très peu de régularité exploitable.
En effet, les lignes sont de différentes longueurs, contenant un enchevêtrement de
composantes connexes. La littérature fait état de trois méthodes principales pour l’extraction
de lignes dans les images binaires : les méthodes de projection ou groupement de
composantes ou de pixels le long d’une direction, les approches multi-résolution ou filtrage
différentiel, et les méthodes de groupement de points caractéristiques.
Quelque soit la méthode utilisée, trois problèmes viendront toujours restreindre les
performances de la segmentation Texte/Dessin des images de documents anciens :
Le problème de l’échelle : Comment définir une zone de texte sans définir comme
paramètre la taille minimale et maximale des blocs ? Comment considérer une lettrine ou des
titres imprimés en grande taille comme des zones de texte ?
Le problème de la quantité d’information : A partir de quel seuil de densité de traits faut-
il décider de la présence d’un bloc de texte ? C’est la raison pour laquelle il est difficile de
segmenter un seul caractère isolé car il n’y a pas assez d’information statistique par rapport à
la zone englobante. Par conséquent, de nombreux travaux utilisent au minimum la notion de
ligne, car la ligne de texte est la plus petite région élémentaire suffisamment grande dans
laquelle on peut trouver cette accumulation.
Problème de l’orientation présumée du texte : On est obligé de faire des hypothèses sur
l’orientation horizontale du texte et beaucoup de méthodes sont sensibles à l’inclinaison du
document (« skew angle).
En conclusion, il existe bien des approches pour séparer les zones graphiques des
zones textuelles. Une seule approche n’est pas toujours suffisante, et une combinaison de
méthodes est souvent nécessaire dans les cas difficiles. La segmentation Texte/Dessin a de
nombreuses applications et reste la première étape incontournable pour l’interprétation et
l’indexation des images de documents.
Laboratoire L3i – Université de La Rochelle Page 13](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-13-320.jpg)

![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
II. Analyse texturale des documents
II.1. Introduction
Les images de document peuvent être vues comme des images texturées dans lesquelles
chaque typographie correspond à une texture différente. De ce fait, la notion de texture se
présente selon deux approches :
• Une approche Analyse et Reconnaissance du Document (ARD), qui examine l’image
au niveau pixel à condition qu’elle soit déjà segmentée.
• Une approche traitement des images qui considère l’image dans sa globalité comme un
mélange de signaux de fréquences et d’orientations différentes.
Ces deux approches sont utilisées pour obtenir des mesures de texture caractéristiques et
robustes [18].
II.2. Définition de la texture
Il n’existe pas de définition universelle de ce que les chercheurs s’emploient à
caractériser comme texture. Chacun propose sa propre explication de ce qui apparaît
visuellement comme une évidence en termes de granularité, régularité… en fonction de
l’utilisation qu’il en fait (certains s’attachent à l’aspect perceptif, alors que d’autres la
définissent par le domaine d’application)
D’un point de vue formel, on admet généralement que la texture est une fonction des
variations d’intensité observées dans l’image. Une définition générale de la texture [14] la
considère comme : Une mesure de la variation de l'intensité d'une surface, mesurant des
propriétés telles que la douceur, la grossièreté et la régularité. Elle est employée souvent
comme un {descripteur de région} dans le domaine de l’analyse d’image et de la vision par
ordinateur.
Les trois principales approches employées pour décrire la texture sont statistiques,
structurales et spectrales. Les techniques statistiques caractérisent la texture par les
propriétés statistiques des niveaux de gris des points comportant/composant une surface.
Typiquement, ces propriétés sont calculées à partir de l’histogramme des niveaux de gris ou
de la matrice de cooccurrence de la surface. Les techniques structurales caractérisent la
texture comme une surface composée de primitifs simples appelés les «texels» (des éléments
de texture), ils sont régulièrement arrangés sur une surface selon quelques règles. Ces règles
sont formellement définies par {une ou plusieurs grammaires} de divers types. Les
techniques spectrales sont basées sur des propriétés du spectre de Fourier et décrivent la
périodicité globale des niveaux de gris d'une surface en identifiant des crêtes d'énergie élevée
dans le spectre.
II.3. Application de la texture à la segmentation
La texture sert généralement à la segmentation des images et sous-entend la
reconnaissance de zones homogènes au sens d’une texture donnée.
La distinction aisément faite par l’œil humain entre plusieurs textures est une tâche difficile à
réaliser en vision par ordinateur, dans la mesure où il existe un nombre infini de textures et où
chacune possède ses propres caractéristiques de luminance, orientation, fréquence….[18]
Dans ces conditions, il n’existe pas de méthode capable de caractériser complètement chaque
texture ; l’objectif de la majeure partie d’entre elles est d’analyser l’image de manière à
décrire au mieux les impressions visuelles. Pour cela, on attribue à la texture les propriétés
suivantes [14]:
La texture est une propriété de région qui ne peut pas être définie en un point, ceci fait
Laboratoire L3i – Université de La Rochelle Page 15](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-15-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
donc intervenir la notion de voisinage.
La texture est une répartition spatiale de niveaux de gris.
La texture peut être appréhendée à différents niveaux ou différentes résolutions.
Une région est considérée comme texturée lorsqu’elle présente un grand nombre de
petits objets ou un motif élémentaire répétitif.
II.4. Méthodes d’analyse de texture
a) Méthode structurelle
La texture est définie comme une organisation spatiale de niveaux de gris, c’est-à-dire
qu’elle laisse apparaître des arrangements spatiaux de motifs de base déterminés, ce qui ne
s’applique a priori que dans le cas de structures très régulières.
La plupart des méthodes d’analyse de ces textures se décomposent en deux phases : la
première sert à déterminer les éléments de base composant la texture, tandis que la deuxième
vise à en déterminer l’arrangement spatial.
Les méthodes structurelles sont généralement peu intéressantes, dans la mesure où elles
imposent de travailler sur des textures extrêmement régulières, ce qui n’est pas notre cas (les
images de documents anciens possèdent un grand nombre de paramètres) [18].
b) Méthode statistique
Ces méthodes définissent la texture en termes de distribution de niveaux de gris ; ce
sont les premières à avoir été utilisées en vision artificielle.
La méthode des matrices de co-occurrence en niveaux de gris est la plus connue et la plus
utilisée des méthodes statistiques. Le principe de cette technique est de parcourir l’image dans
quatre directions privilégiées (0,π/4,π/2,3π/4) et de repérer combien de fois des pixels de
luminosités différant de ∆z sont séparés d’une distance donnée D.
Il s’agit d’un problème à la fois facile à mettre en œuvre (même si le choix des paramètres et
la sélection des résultats les plus pertinents restent difficiles) mais largement coûteux en
termes de temps de calcul et de ressources mémoire nécessaires.
On peut aussi utiliser la fonction d’auto-corrélation, qui permet d’évaluer aussi bien le degré
de régularité de l’image, que la finesse ou la grosseur de la texture dans l’image.
D’après sa formulation mathématique, pour une image I à M lignes et N colonnes :
(II.1)
Si le tracé de la fonction d’auto-corrélation chute lentement, alors la texture est plutôt fine
(l’image est très similaire d’un pixel d’observation à son voisin), et à l’inverse si elle chute
rapidement, cela signifie que la texture est plus grossière (deux voisinages proches présentent
peu de similarités) [18] [19]
Laboratoire L3i – Université de La Rochelle Page 16](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-16-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Variabilité de la disposition de textures dans une même image
c) Méthodes issues du traitement de signal
Le but de ces méthodes est de décrire la texture comme un mélange de signaux de
fréquences, d’amplitudes et de directions différentes. Celles-ci sont particulièrement efficaces
en général dans la mesure où elles cherchent à imiter le processus de vision humaine qui
opère une décomposition fréquentielle systématique des images qui parviennent sur la rétine.
Dans le domaine spatial, l’idée est de caractériser la texture par le nombre de transitions (ou
contours) qu’elle affiche par unité de surface, plutôt que d’utiliser les fréquences ; Haralick
parle aussi de « textural edgeness ». On peut, pour cela, utiliser des techniques de détection
de contours classiques. Parmi les plus simples, l’opérateur Laplacien ou l’opérateur de
Robert [18].
Dans le domaine fréquentiel, le principe consiste à repérer les fréquences et les orientations
qui composent les textures contenues dans l’image. Ces méthodes sont particulièrement
adaptées aux cas des images contenant des textures régulières. Le principe est d’appliquer à
l’image originale la transformation de Fourier qui permet de mettre en évidence les régularités
en passant dans le domaine fréquentiel. Le problème posé par cette opération, qui agit
globalement sur l’image, est qu’elle perd une information précieuse de localisation spatiale
i.e. on connaît les caractéristiques (en fréquence et en orientation) des textures qui composent
l’image mais on ne peut pas les situer dans l’image originale [14].
La solution à cela est d’utiliser une transformation alternative appelée transformation de
Fourier à fenêtre glissante, où le principe est d’appliquer la transformation de Fourier dans
une fenêtre d’observation que l’on déplace dans l’image ; la formulation en 1 dimension de
cette opération est :
(II.2)
Où f désigne la fonction à laquelle on applique la transformée de Fourier, et w l’amplitude de
la fenêtre d’observation. Lorsque cette dernière est gaussienne, on parle de transformée de
Gabor.
II.5. Utilisation de la texture sur les images de documents anciens
L’analyse d’images de document, telle que nous l’entendons, consiste en un
découpage (ou segmentation) de l’image en régions homogènes au sens de leur fonction.
Classiquement, on considère que dans les images de documents il existe principalement trois
classes particulières à discriminer : le Texte, le Dessin et le Fond.
Laboratoire L3i – Université de La Rochelle Page 17](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-17-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Dans la plupart des cas, la notion de texture est utilisée pour la segmentation d’images de
documents imprimés où on cherche à classer les zones d’intérêt en deux ou trois catégories,
c'est-à-dire Texte/non-Texte, Texte/Dessin ou Texte/Dessin/Fond.
II.6. Segmentation des images de documents anciens
Quel que soit le type d’image, la séparation des zones textuelles des zones graphiques
s’effectue en localisant les lignes de texte. En effet, de nombreux travaux dans différents
domaines démontrent que la ligne de texte, grâce à sa texture régulière et son alignement,
reste l’élément le moins difficile à localiser quelque soit le support. On peut définir une zone
de texte comme « une région de l’image présentant une très forte densité de traits qui forment
des alignements à une échelle donnée ». Dans une image naturelle, une telle configuration est
très rare [18].
Les méthodes utilisées sont principalement celles basées sur des opérations
morphologiques par filtrage différentiels ou fréquentiels directionnels. Il s’agit d’approches
dites ascendantes (data-driven) où l’on cherche une interprétation sans connaissances a priori
à partir seulement des seules informations sur les pixels de l’image. Les approches
descendantes (model-driven) nécessitent des connaissances a priori sur la forme de la
localisation des zones de texte ce qui est difficile à obtenir sur des documents anciens [29].
Les images de documents anciens soulèvent trois types de difficultés. La première difficulté
vient de la mise en page de ces documents qui peuvent être complexes et présenter plusieurs
colonnes de taille de corps et d’interlignes différents. Le second problème concerne
l’inévitable courbure des lignes de texte produite par la reliure des livres. Enfin la dernière
difficulté provient des faibles espaces entre les lignes qui entraîne de nombreux contacts entre
les caractères appartenant à de lignes différentes [29].
Cas1 : mise en page complexe Cas2 : Courbure Cas3 : connexions entre caractères
Figure II.1. Verrous empêchant l’application de la méthode des projections pour
l’analyse d’image [29]
Laboratoire L3i – Université de La Rochelle Page 18](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-18-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
II.7. Segmentation d’image de documents anciens par analyse des projections
horizontales/ verticales
Cette méthode consiste à projeter les valeurs des pixels ou l’épaisseur du rectangle
circonscrit des caractères, dans les directions horizontales et verticales de façon à obtenir deux
histogrammes. L’histogramme des projections horizontales possède des maxima qui
représentent les centres des lignes et des minima qui délimitent les bords inférieurs et
supérieurs des lignes. L’histogramme des projections verticales donne les bords extérieurs
gauches et droits des colonnes. Cette méthode ne marche pas pour les documents multi-
colonnes (cas1) et supposent que les lignes soient correctement alignées horizontalement
(cas2). Cette approche nécessite une correction préalable de la courbure et de l’inclinaison et
ne peut traiter que des documents de structure simple. De plus, il faut binariser correctement
l’image de façon à séparer correctement les lignes. Cette méthode n’est donc pas utilisable sur
toutes les images de documents anciens. Cependant, la méthode de projection peut être
appliquées sur des morceaux de lignes de façon à réduire la sensibilité à l’inclinaison et éviter
l’imbrication multiple avec des zones graphiques [29].
Les méthodes de projection permettent toutefois d’extraire la ligne de base (« base-line »), le
corps du texte (« x_line – base-line ») qui délimitent les caractères sans hampes ni jambage.
Ces informations importantes peuvent être extraites par projection de chaque mot du texte
[18].
Motif Régulier
Motif Irrégulier
Motif Régulier
Figure II.2. Résultat de projection horizontale d’une image de document [31]
Voici un résumé de quelques travaux, portant sur la segmentation d’images de documents,
utilisant de nombreuses approches intéressantes :
Jain et Bhattacharjee [3] proposent une méthode directe de segmentation texte/dessin en
utilisant un banc de filtres de Gabor, la méthode ainsi définie ne permet que de marquer les
zones de texte des images de documents traitées.
Trygve et al. [2] reposent sur les travaux de Jain et Bhattacharjee pour mettre au point un
système de segmentation supervisé, mais plus avancé, capable de définir le texte, le dessin et
le fond des images de documents fortement bruités.
Mausumi et Malay [4] développe une méthode de segmentation d’images de documents à
l’aide du filtre de Gabor utilisé dans un environnement à base d’ondelette. Le travail ainsi
défini opte seulement pour le marquage des zones de texte présentes dans le document.
Laboratoire L3i – Université de La Rochelle Page 19](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-19-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Notre travail représente une première tentative dans l’établissement d’un système de
segmentation Texte / Dessin d’images de documents anciens par approche texture utilisant un
banc de filtres de Gabor.
Il était une fois une Ä °àt|à âÇx yÉ|á âÇx Å°v{tÇàx
méchante sorcière si áÉÜv|¢Üx á| }tÄÉâáx wx Ät uxtâà° wx
jalouse de la beauté át uxÄÄx Ñxà|àx y|ÄÄx UÄtÇv{xAâÇ
de sa belle petite }ÉâÜ xà Ät }xààt wtÇá âÇ
fille Blanche.un jour Üâ|ááxtâA fxÑàá Ñxà|àá Çt|Çá
Il était une fois une
méchante sorcière si
jalouse de la beauté
de sa belle petite
fille Blanche.un jour
Figure II.3. Les différentes zones d’un document peuvent être simulées à un agencement de textures
III. Théorie du filtre de Gabor
Un filtre de Gabor est une fonction sinusoïdale à laquelle on a rajouté une enveloppe
gaussienne. Dans le plan fréquentiel, cette fonction se transforme en gaussienne. La fonction
sinusoïdale est caractérisée par sa fréquence et par son orientation. Ainsi appliqué sur une
image, un filtre de Gabor peut être vu comme un détecteur de segments d'orientation
particulière, puisqu'il réagira aux arêtes perpendiculaires à la direction de propagation du
sinus. La fréquence du sinus, indique à quelles fréquences le filtre sera sensible et réagira. Il a
de plus été montré que les fonctions de Gabor forment un set complet, c'est à dire que
n'importe quelle fonction peut être exprimée en une somme (infinie) de fonctions de Gabor,
pour autant que le produit des densités fréquentielle et spatiale du set soit supérieur à 1[4].
Les techniques de filtrage multi-canal permettent l'extraction des caractéristiques de
texture localement, en fréquence et orientation, en d'autres termes, les calculs des
caractéristiques de texture (en fréquence et orientation) peuvent être effectués pour tout pixel
dans une région d'intérêt. Cette méthode est particulièrement intéressante vue qu'elle est
inspirée du système de vision humain qui décompose l'image projetée sur la rétine en un
nombre important d'images filtrées, chacune contenant des variations d'intensité fines de
fréquences et d'orientations.
L'idée de l'approche gaborienne est alors de concevoir un filtrage particulièrement sélectif en
fréquence et orientation dans le but de caractériser au détail près les textures. Chaque filtre est
alors appliqué à l'image d'origine, et une analyse éventuelle permettra de créer un simple
vecteur de caractéristiques (à base de calculs statistiques).
Les fonctions de Gabor présentent les avantages suivants :
• Localisation maximale dans les espaces spatial et fréquentiel;
• Flexibilité: les fonctions de Gabor peuvent être positionnées librement et continuellement
dans l'espace, des fréquences et des orientations choisies arbitrairement sans contraintes;
Laboratoire L3i – Université de La Rochelle Page 20](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-20-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Une fonction de Gabor 2D « h » est une onde plane sinusoïdale modulée par une enveloppe
gaussienne et orientée avec un angle θ à partir de l'axe X. La formulation mathématique, dans
le domaine spatial pour une fréquence fondamentale u0 tout au long de l'axe X (c.à.d. θ = 0°),
est :
1 x2 y2
h(x,y)= exp[- 2 2 2 ] cos (2πu0x) (III.1)
x y
où σx (respectivement σy) est la variance de la gaussienne selon l'axe X (respectivement Y).
Les filtres à orientation θ (θ≠0) sont obtenus en effectuant une rotation de l'équation
précédente.
La sélectivité du banc de filtre en orientation et fréquence est claire dans le domaine
fréquentiel, c'est pour cette raison qu'on applique la transformée de Fourier à l'équation (1), et
on obtient :
2 2 2 2
1 u u0 v 1 u u0 v
H(u,v)=TF(h(x,y))=A.{exp[- 2 2 2 ]+exp[- 2 2 2 ]}
u v u v
(III.2)
avec σu = 1 / 2πσx , σv = 1 / 2πσy et A = 2πσxσy .
De ce fait, dans le domaine fréquentiel, le signal est représenté par deux gaussiennes le long
de l'axe X, centrées en +u0 et -u0 comme montré sur la figureIII.1.
Impossible d’afficher l’image.
Impossible d’afficher l’image.
Figure III.1. La fonction de Gabor dans le domaine fréquentiel Figure III.2. La fonction de Gabor dans le domaine Spatial
Dans le domaine fréquentiel, la fonction de Gabor Dans le domaine spatial, la fonction de Gabor
est représentée par deux piques gaussiennes. est une fonction sinusoïdale modulée par une
gaussienne
Laboratoire L3i – Université de La Rochelle Page 21](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-21-320.jpg)


![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
D'une manière pratique plus détaillée, un filtre symétrique impair de Gabor possède la forme
générale suivante dans le domaine spatial :
2 2
1 x y
h(x,y,θ,f) = exp {- 2 [ 2 2 ]}cos(2π f xθ) (III.3)
x y
avec xθ = x cosθ + y sinθ , et yθ = -x sinθ + y cosθ .
Ce filtre consiste en une enveloppe gaussienne (de paramètres σx et σy) modulée par une
sinusoïde de fréquence f le long de la direction de l'axe xθ . L'angle θ permet la rotation de la
direction de la réponse. La fréquence f peut être vue comme l'inverse de la moyenne des
distances inter-directions.
La valeur de θ est donnée par : θk = π(k – 1)/m, k =1...m, où m représente le nombre de
d'orientations.
Pour chaque bloc d' image (fenêtre) de taille W x W, centré au point (X,Y), avec W impair, on
calcule la grandeur de la caractéristique de Gabor comme suit, pour k = 1....m :
g(X,Y,θk,f,σx,σy) = I(X+x0,Y+y0)h(x0,y0,θk,f,σx,σy) (III.4)
où I(x,y) est la valeur du niveau de gris du pixel (x,y).
Comme résultat, on obtient m caractéristiques gaboriennes pour chaque bloc de W x W de
l'image.
Dans des blocs contenant un motif aigu, les valeurs d'une ou de plusieurs valeurs
caractéristiques gaboriennes sera (seront) plus importante(s) que les autres valeurs (ces
valeurs correspondent à l'angle de rotation du filtre qui coïncide avec l'angle directionnel du
motif ou traits du bloc en cours). D'un raisonnement similaire, pour un bruit non-orienté
(aléatoire)des blocs de fond, les m valeurs caractéristiques seront similaires. De ce fait, la
variance G des m valeurs caractéristiques permet de segmenter ou de séparer le fond (arrière
plan) de l'avant-plan (domaine d'intérêt).
Si G est inférieure à un certain seuil donné, le bloc est étiqueté comme un bloc de fond
(background), sinon le bloc est étiqueté comme un bloc d'intérêt (foreground).
Cependant, cette méthode n'est pas précise sur les bords des régions d'intérêt ou des
blocs ayant un faible contraste (résolution), comme on peut perdre de l'information
miniaturisée en arrière plan si les paramètres ne sont pas bien ajustés.
Les filtres de Gabor bidimensionnels permettent l’extraction directe de caractéristiques
de textures localisées en fréquence et en orientation, c'est-à-dire que pour chaque pixel, ils
permettent le calcul de caractéristiques dans un voisinage l’englobant. Cette technique,
précisément inspirée du mécanisme de la vision humaine qui opère une décomposition
fréquentielle systématique des images qui parviennent sur la rétine, se révèle particulièrement
Laboratoire L3i – Université de La Rochelle Page 24](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-24-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
efficace.
Le principe des filtres de Gabor est donc de bâtir un banc de filtres très sélectifs en
fréquence et en orientation, et de filtrer l’image à analyser avec chacun d’eux ; le calcul a
posteriori de paramètres sur les images résultats, permet de caractériser les textures
contenues dans l’image à analyser.
Il est à noter que lorsque la fréquence fondamentale u0 augmente, la bande passante du
filtre en fréquence augmente elle aussi : le filtre devient moins sélectif ; ce phénomène
apparaît clairement sur la représentation d’un banc de filtres de Gabor à 6 fréquences (u0=1√2,
2√2, 3√2, …) et 4 orientations (θ=0°, 45°, 90° et 135°). Par ailleurs, le banc de filtres de
Gabor permet de couvrir la quasi-totalité de l’espace des fréquences et, dans la mesure où il
n’y a que peu de recouvrement entre eux, la décomposition d’une texture dans ce plan est
unique et caractéristique.
III.1. Paramétrisation / Calcul efficace des paramètres de Gabor
Dans ce qui suit, on présentera les méthodes de sélection et de calcul des paramètres
du filtre de Gabor.
Un filtre de Gabor 2-D est un produit d’une gaussienne elliptique dans toute rotation et un
exponentiel complexe représentant une onde plane sinusoïdale.
La sensibilité du filtre est commandée principalement par ses écarts types, associés au grand
et petit axes σx et σy respectivement. Deux autres paramètres décrivent un filtre de Gabor qui
sont f0 (fréquence centrale) et θ (angle d’orientation).
L’allongement de la gaussienne est donné par : λ = σx / σy.
Une caractéristique gaborienne consiste en le calcul de la réponse des différents filtres pour
des valeurs différentes d’orientations et de fréquences : réponse du banc de filtres.
Un banc de filtres est composé de plusieurs filtres et utilisé dans le processus de
reconnaissance d’objets à base de la relation existante entre les différentes réponses des
filtres.
a) La répartition angulaire
Dans la littérature, la sélection d’angles d’orientation θl a été démontrée [3][21] ; un résultat
clé annonce l’espacement uniforme des différentes orientations.
θl = 2πl/n , l={0,1,2,….,n-1} (III.5)
où θl est la lème orientation et « n » et le nombre total d’orientations envisagées.
Le calcul peut être réduit à moitié vu que les réponses aux angles [π,2π] sont des complexes
conjugués aux réponses sur [0, π] dans le cas des valeurs d’entrée réelles.
Laboratoire L3i – Université de La Rochelle Page 25](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-25-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
b) La répartition fréquentielle
Pour les valeurs de la fréquence, elles vérifient l’expression suivante :
fl = k-1fmax , l={0,1,,2,…..m-1} (III.6)
k =2 pour une octave d’espacement ou bien k=√2 pour un espacement d’un demi d’octave.
c) Les Vecteurs caractéristiques
En utilisant ces schémas de sélection pour couvrir les fréquences d’intérêt f0,….,fm-1 et les
orientations pour la discrimination angulaire désirée, on construit un ensemble de
caractéristiques pour tout pixel (x0,y0) de notre image, soit G cette matrice. G peut s’écrire
sous la forme suivante :
r(x0,y0 ;f0,θ0)………………. r(x0,y0 ;f0,θn-1)
r(x0,y0 ;f1,θ1)………………. r(x0,y0 ;f1,θn-1)
. . . . . . .
G= . . . . . . .
. . . . . . .
. . . . . . .
r(x0,y0 ;fm-1,θ0)………………. r(x0,y0 ;fm-1,θn-1)
Cette matrice caractéristique peut être utilisée comme un vecteur d’entrée dans un processus
de classification.
Seule la détermination des valeurs de f, θ et σ n’est pas suffisante pour travailler efficacement
avec le filtrage gaborien, il faudrait trouver leurs valeurs optimales. Il existe plusieurs
méthodes d’optimisation, cependant, le caractère d’interdépendance des paramètres gaboriens
et l’hétérogénéité de leurs domaines de définition compliquent cette tâche et la rendent des
fois impraticable.
III.2. Les fréquences du filtre de Gabor
Dans la littérature [3][4][21], il existe une multitude d’approches pour la détermination
des valeurs des fréquences utilisées pour le filtrage. Principalement, l’adoption d’une
approche spécifique est commandée par le domaine d’application et la nature des images
utilisées.
Les fréquences des filtres dans un banc de filtres sont : f0=fmax, f1=fmax/k, f2=fmax/k2 , ……
fn=fmax/km-1. Les valeurs sélectionnées de k et σx sont interdépendantes. Elles doivent être
choisies de telle sorte que le banc de filtres capture toutes les fréquences utiles et descriptives
pour l’application envisagée.
Laboratoire L3i – Université de La Rochelle Page 26](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-26-320.jpg)




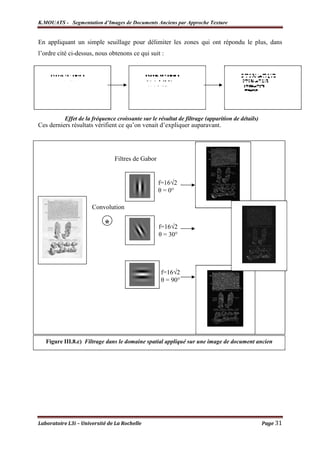




![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
IV. Implantation
Suite aux résultats encourageants de la segmentation de textures et celle du
texte/dessin, utilisant le filtre de Gabor [2] [6], nous avons implémenté ce filtre et nous
l’avons testé sur les images de notre base de documents anciens (contenant 80 images).
Le but est d’appliquer ce filtre sur les images de documents anciens et définir ainsi un outil de
segmentation par approche texture pour ce type d’images.
L’idée qui soutient cette approche, est que les zones de texte peuvent être considérées
comme des textures spécifiques. Il en est de même pour les zones graphiques qui sont
considérées comme des textures mais avec des propriétés différentes de celles des zones de
texte.
Les zones de texte sont des zones riches en transitions, de ce fait, elles sont riches en
hautes fréquences, contrairement aux zones graphiques, qui sont des zones relativement
homogènes, et par conséquent caractérisées par des basses fréquences.
En se basant sur ce constat, le filtre de Gabor est trop "sensible" (réponse importante
du filtre) aux zones de texte pour les hautes fréquences, et il est relativement plus sensible aux
zones graphiques pour des fréquences basses ; notez que si les zones graphiques comportent
des zones riches en transitions, le choix de la fréquence adéquate pour le filtrage demeure une
tache relativement complexe et non évidente.
Nous constatons, d’après les tableaux IV.1 et IV.2 que le filtre de Gabor est sensible
aux valeurs d’entrée de ses paramètres, et le résultat de filtrage dépend étroitement de celles-
ci. Les résultats sont obtenus après un seuillage des images résultantes après le filtrage. Le but
de ce seuillage est principalement pour des fins de visualisation, afin de montrer la variation
des réponses des différents pixels pour un seul filtre. L’opération de seuillage est appliquée
comme suit :
♦ Si Ndg [p(i,j)] > Seuil p(i,j) ε Classe Active (réponse
importante du filtre de Gabor)
♦ Si Ndg [p(i,j)] < Seuil p(i,j) ε Classe Passive (réponse
négligeable du filtre de Gabor)
Nous avons constaté aussi que la sensibilité du filtre de Gabor, pour la détection de
segments et de discontinuités, l’empêche d’être très efficace pour la segmentation texte/dessin
à cause de la présence d’éléments fins détectables, par le filtre de Gabor, dans les zones
graphiques, et cela pour des basses fréquences. La même constatation pour des hautes
fréquences, dans le traitement des zones de texte contenant des zones homogènes et uniformes
(gros textes), le filtre de Gabor est alors incapable de détecter de tels composants.
Pour remédier à cette insuffisance du filtre de Gabor, on définit des Banc de filtres
dont le but consiste à définir une combinaison de plusieurs fréquences et orientations qui
servent à extraire les différentes composantes de l’image ; chaque instance de fréquence et
d’orientation définit un Canal, qui sert à conduire, filtrer et ressortir les éléments de l’image
dont les caractéristiques correspondent à ces valeurs. On parle alors dans ce cas de Filtrage
Multicanaux.
Laboratoire L3i – Université de La Rochelle Page 36](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-36-320.jpg)





![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Et pour les basses fréquences :
Pixels de texte
étiquetés en tant que
pixels graphiques.
IV.2. Discussion
Il est à noter, dans tous les cas de figure, qu’il existe des éléments appartenant soit à
une zone graphique et que même avec un seuillage on n’arrive pas à les étiqueter ainsi, ou
qu’ils soient des éléments de texte, et que suite au filtrage et au seuillage, on les retrouve
faisant partie de la zone graphique.
L’apport de l’orientation est moins important, comparé à celui de la fréquence, et ceci
à cause de la richesse des images de traits en composants orientés dans de multitudes
directions, ce qui fait que pour tout pixel de l’image à filtrer, ce même pixel peut appartenir en
même moment à une composante texturée orientée horizontalement, verticalement, ou
oblique. On en déduit que le résultat du filtrage gaborien dépend essentiellement de la valeur
de la fréquence du filtre, qui représente sa sensibilité, et de son écart type qui reflète la
réceptivité de celui-ci.
Pour capturer les différentes composantes d’une image, dans le but d’une
segmentation Texte/Dessin, il nous convient de définir plusieurs fréquences de filtrage, et
plusieurs orientations (plusieurs canaux) ; l’ensemble des filtres ainsi définis fournissement ce
qu’on appelle dans la littérature du filtrage par un « Banc de Filtres ».
IV.3. Définition du Banc de Filtres pour le filtrage des images de documents anciens
Même si on dispose de quelques outils formels pour la définition d’un banc de filtres
de Gabor, on s’est servi principalement des travaux de Jain & Bhattacharjee [3] et Trygve &
Husϕy [2] pour le paramétrage de notre Banc de filtres.
On utilise 12 orientations pour couvrir tout le plan, avec un point d’espacement angulaire de
p2=30 : 0°,30°,60°,90°,120°,150°,180°,210°,240°,270°,300° et330° (voir l’équation : 2.5). Vu
la propriété de symétrie du filtre de Gabor, on ne garde, de ce fait, que les orientations
appartenant à l’intervalle [0, 180°] : 0°,30°,60°,90°,120°,150° et 180°. On élimine la direction
180° vu que son support correspond à celui de 0°.
Laboratoire L3i – Université de La Rochelle Page 43](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-43-320.jpg)
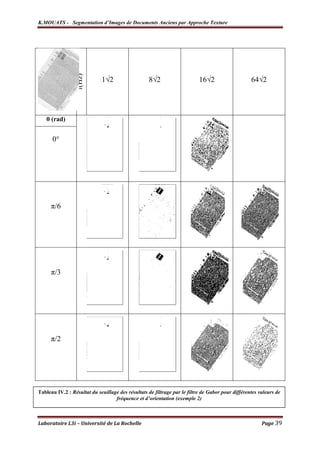
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Selon [21] et [3], pour avoir un bon résultat de filtrage, le nombre d’orientations ne
doit pas être inférieur à 4, et vu l’importance des directions du premier quart du plan et afin de
ne pas encombrer les calculs, on va préserver les 5 orientations suivantes :
{0°,30°,60°,90°,120°}.
En appliquant la formule (2.13), on trouve σy ≅ 1.35.
On a choisi k=√2.
D’une manière analogue, fmin=1, fmax = 512 pour une image 800x600 (plus grande
valeur 2n < largeur de l’image).
Pour trouver le nombre de fréquences utilisées, on applique la formule (2.10), on trouve
alors : m=19. Les fréquences d’intérêt sont alors, en appliquant la formule (2.6) : 512, 512/√2,
256,256/√2,128, 128/√2,64, 64/√2, 32, 32/√2,16, 16/√2, 8, 8/√2, 4, 4/√2, 2, 2/√2 et 1.
De ce fait, p1=1/√2=0.7071 et appliquant (2.7), on trouve σx≅1.1.
On peut conserver les deux valeurs différentes de σx et σy, et donc avoir des filtres elliptiques ;
une méthode pour avoir des filtres circulaires [1][4]consiste à calculer la moyenne des deux
écarts types : σ = (σx+σy)/2 ≅ 1.23.
La méthode formelle qui a servi à calculer les différents paramètres de nos filtres est
parmi d’autres méthodes heuristiques qui existent dans la littérature [1] [2] [3] [4], et font
toutes preuve d’efficacité mais pour des classes d’images spécifiques.
Parmi toutes les valeurs des fréquences définies (fréquences d’intérêts), on ne va conserver
que quelques unes, soient 6 fréquences : 3 basses (1,2√2 et 4) et 3 hautes (32√2, 64√2 et
128√2) (la largeur des images utilisées ≅ 600pixels la plus grande fréquence en puissance
de 2 est égale à 512 = 2 . Donc la plus grande fréquence utilisée = 29-2√2 =128√2Hz, et
9
évidemment, la plus petite fréquence est égale à 1Hz. Le choix du nombre de fréquences
utilisées a été jugé suite aux jeux de tests réalisés).
De ce fait, on aura 5x6 = 30 filtres qui composent notre Banc de Filtres.
On filtre nos images de documents anciens à l’aide des filtres, précédemment définis, et on
applique un processus de classification, suite auquel on obtient le résultat de segmentation de
nos images à l’aide du filtre de Gabor.
IV.4. Réalisation
On définit 2 Sous-Banc de filtres, le premier est destiné à localiser les pixels
appartenants aux zones graphiques et cela on manipulant des basses fréquences (les zones
graphiques sont des zones presque homogènes détectables pour des basses fréquences), et le
deuxième est destiné, à localiser les pixels appartenants aux zones textes et ceci en manipulant
des hautes fréquences (les zones de texte sont des zones riches en transitions et par
conséquent en hautes fréquences).
Par conséquent, chacun des Sous - Banc de Filtres est composé de 3x5=15 filtres, et
pour chaque pixel de toute image filtrée, on définit un Vecteur Caractéristique VC de 15
composantes, et dont chacune représente la réponse du filtre sur l’image en question pour une
fréquence f et une orientation θ données. VC peut s’écrire sous la forme suivante :
VC = {r(fi,θj),i=1..3,j=1..5}
Laboratoire L3i – Université de La Rochelle Page 44](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-44-320.jpg)

![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
V. Classification floue d’image
V.1. Introduction
La segmentation a pour but de déterminer les régions d’une image cohérentes à la fois
spatialement et du point de vue de leur contenu. Une catégorie de méthodes de segmentation
d’images s’appuie sur une classification : les points de l’image sont des individus que l’on
souhaite regrouper en classes.
Très tôt après l’introduction par Zedah [33] du concept d’ensemble flou, on s’est
aperçu que la notion de classe utilisée en reconnaissance des formes trouvait là son cadre
d’expression tout naturel. En effet, on peut définir une classe comme un groupe d’individus
présentant des similitudes communes. Ces similitudes peuvent être plus ou moins fortes entre
les individus d’une même classe, et d’autre part, un même individu peut présenter des
similitudes avec des individus d’autres classes, si bien que son appartenance n’est pas
localisée à une classe déterminée mais se trouve distribuée sur plusieurs classes, sans qu’il
soit toujours possible de trancher d’une façon nette à quelle (unique) classe appartient
l’individu en question. Mais nous avons là le concept même d’ensemble flou qui est défini,
car dans ce formalisme, un élément peut appartenir plus ou moins fortement à plusieurs
ensembles flous [20].
Pour remédier à ce type de problème, de nouvelles approches de classification ont été
proposées, parmi lesquelles, on peut noter l’approche par la logique floue, avec l’introduction
du concept de degré d’appartenance qui détermine la « force » avec laquelle un individu
(pixel d’image dans notre cas) appartient aux différentes classes. Cela repose sur le fait que le
concept de la logique floue ne cherche pas un point de rupture x qui décide de l’appartenance
d’un individu à une classe, mais qu’elle raisonne plutôt sur la base d’un intervalle de valeurs.
Comme évoqué ci-dessus, l’idée qui soutient l’approche par la logique floue est la possibilité
d’appartenance à la fois à plusieurs classes (texte, dessin, fond) pour un pixel donné.
Toutes les méthodes de classification « dure » (parmi lesquelles, la méthode C-
moyennes) contraignant les pixels à être membre d’une, et une seule classe, se trouvent ainsi
exclues.
Bien que la probabilité d’appartenance des objets à plusieurs classes ne soit pas une
exclusivité des techniques floues, nous avons choisi de retenir ces dernières car elles
fournissent une matrice des degrés d’appartenance de chaque pixel à chaque classe.
L’approche par la logique floue en segmentation d’image, se justifie donc grâce à sa capacité
d’engendrer une matrice des degrés d’appartenance [15].
V.2. Degré d’appartenance
«Très souvent, les classes d’objets rencontrées dans le monde physique ne possèdent pas de
critères d’appartenance bien définies ». Ce constat montre le fossé qui sépare les
représentations mentales de la réalité et les modèles mathématiques usuels à base de variables
booléennes vrai/faux. En effet, il est difficile de proposer un seuil en deçà (#au-delà) duquel
l’observation sera affectée entièrement à telle ou telle classe.
Nous avons adopté l’idée de J.C. Bezdek pour réaliser une classification floue des
pixels résultants de l’opération de filtrage. Le résultat de cette classification floue sera utilisé
pour calculer les probabilités a posteriori. L’idée était qu’au lieu de chercher à tout prix un
Laboratoire L3i – Université de La Rochelle Page 46](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-46-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
seuil unique S décidant l’appartenance à un ensemble dans un contexte donné, il semble plus
réaliste de considérer deux seuils S1<S2, avec une fonction d’appartenance donnant à chaque
pixel un degré d’appartenance (compris entre 0 et 1) selon lequel le pixel en question
appartient à une classe donnée. En deçà de S1, le pixel appartient complètement à une classe
(degré d’appartenance maximal égal à 1) ; au-delà de S2, il n’appartient plus à cette classe
(degré d’appartenance minimal, par convention égal à 0). Entre S1 et S2, les degrés
d’appartenance seront intermédiaires (entre 0 et 1). (Voir plus loin la formalisation floue)
Le concept de sous-ensemble flou et le degré d’appartenance ont été introduits pour
éviter les passages brusques d’une classe à une autre et autoriser les éléments à n’appartenir
complètement ni à l’une ni à l’autre ou encore appartenir partiellement à chacune. Ces notions
permettent de traiter : des catégories aux limites mal définies, des situations intermédiaires
entre le « tout » et le « rien », le passage progressif d’une propriété à une autre, ou encore des
valeurs approximatives exprimées en langage naturel [9][10].
Parmi les techniques de la logique floue en classification, l’algorithme C-Moyennes
Floues (CMF) a été choisi pour son autonomie due à l’usage d’un classificateur non
supervisé. Les autres méthodes, comme les k-plus proches voisins flous ou celle fondée sur
les relations floues sont tous des algorithmes de classification supervisée réclamant un
échantillon d’apprentissage.
On va présenter dans ce qui suit le principe de cet algorithme de classification très
populaire, basé sur la logique floue, connu pour son efficacité et sa robustesse.
V.3. L’algorithme des C-Moyennes Floues (CMF)
L’algorithme des C-Moyennes (CM) est l’une des méthodes les plus connues parmi les
techniques de classification non supervisée et qui est fréquemment utilisée pour la
quantification vectorielle. La version C-Moyennes Floues est une extension directe de cet
algorithme, où l’on introduit la notion d’ensemble flou dans la définition des classes. Comme
leurs homologues « Durs », cet algorithme utilise un critère de minimisation des distances
intra-classes et de maximisation des distances inter-classes, mais en tenant compte des degrés
d’appartenance des pixels [10].
L’algorithme CMF est un algorithme de classification floue fondé sur l’optimisation
d’un critère quadratique de classification où chaque classe est représentée par son centre de
gravité [10]. L’algorithme nécessite de connaître le nombre de classes au préalable et génère
les classes par un processus itératif en minimisant une fonction objectif. Ainsi, il permet
d’obtenir une partition floue de l’image en donnant à chaque pixel un degré d’appartenance à
une région donnée.
Les principales étapes de l’algorithme des c-moyennes floues sont [9]:
/°1. La fixation arbitraire d’une matrice d’appartenance [Uij-k] où uij-k est le degré
d’appartenance du pixel (i,j) à la classe k.
/2°. Le calcul des centroïdes des classes.
/3°. Le réajustement de la matrice d’appartenance suivant la position des centroïdes.
/4°. Le calcul du critère d’évaluation de la qualité de la solution, la non convergence de ce
critère impliquant le retour à l’étape 2.
Laboratoire L3i – Université de La Rochelle Page 47](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-47-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Contrairement aux méthodes de classification dure, la valeur d’appartenance d’un
pixel à une classe ne prend pas simplement la valeur 0 ou 1, mais toutes les valeurs possibles
dans l’intervalle [0,1].
Pour avoir une bonne partition, on impose aux éléments de la matrice [Uij-k], les
contraintes suivantes qui doivent être vérifiées :
/° uij-k ε [0,1]
/° ∑ k u ij − k = 1; ceci∀(i, j )
L’algorithme du CMF fait évoluer la partition (Matrice U) en minimisant la fonction objectif
suivante :
N ,M C 2
J m (U , C ) = ∑∑ (u
i , j =1 k =1
ij − k ) U ij − k − C k
m
Où :
• m>1 est un paramètre contrôlant le degré de flou (généralement m=2) ;
• Ck : le centre de la classe k et c le nombre de classes;
−1
c
(
)
1
● U ij −k = ∑ d 2 ((i, j ), C k ) / d 2 ((i, j ), C n ) m−1
n=1
Algorithme CMF
°1/ Choisir le nombre de classes : C // information a priori, algorithme supervisé.
°2/ Initialiser la matrice de partition U, ainsi que les centres Ck.
°3/Faire évoluer la matrice de partition et les centres suivant les deux équations :
E1 : // Mise à jour des degrés d’appartenance où :
E2 : // Mise à jour des centres
E3- Test d’arrêt : |Jt+1 – Jt| < seuil avec
m : degré de flou, généralement m=2.
Le résultat direct fourni par l’algorithme CMF est la matrice des degrés
d’appartenance de chaque pixel à chaque classe. Cette matrice donne une image graduée de
l’appartenance des pixels aux classes définies.
Laboratoire L3i – Université de La Rochelle Page 48](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-48-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
VI. Classification des résultats de filtrage dans chaque Sous - Banc de Filtres
Seules les réponses brutes du filtre de Gabor ne sont pas efficaces pour fournir un
résultat final parfait d’une image segmentée. Un post-traitement est nécessaire et se résume
dans un processus de Classification des données résultantes des différents filtres.
Le principal verrou se résume dans le choix d’un seuil pour séparer les réponses des
pixels textes et dessins dans les différentes images filtrées. L’intensité à classer (après
normalisation) de chaque pixel représente la réponse de ce dernier pour un filtre particulier
défini par une fréquence et une orientation déterminées. De ce fait, et selon la réponse du
filtre, l’intensité d’un pixel le qualifie en tant qu’un pixel d’une zone de texte si sa réponse
dépasse un certain seuil, cependant, si cette intensité est inférieure à une certaine borne, ce
pixel ne peut être qu’un pixel d’une zone graphique.
Images caractéristiques : Ik
(résultat de filtrage par un
Banc filtres spécifique)
(NxM pixels)
Normalisation uij-k=[255-Ikk(i,j)]/255
0<=uij-k<=1
(Pseudos Degrés d’Appartenance)
i=1...N, j=1…M
k=1..15 par Sous Banc de filtres
VC(i,j)={Uij-k,k=1..15}
1 D
deg(i, j ) = ∑ u ij −l , D = 15
D I(i,j)εClasse1
l =1
°/ Si deg(i,j)<S1
°/ Si deg(i,j)>S2 I(i,j)εClasse1
°/ Si S1<=deg(i,j)<=S2 lancer une
Figure VI.1. Phase de Calcul des degrés procédure de post-traitement pour le
d’appartenance et affectation des pixels calcul de nouvelles valeurs des degij-k.
aux classes correspondantes dans chaque
sous – banc de filtres
°/ Pour le Sous Banc de Filtres 1 (hautes fréquence) :
Classe1 = Texte
Classe1 = Dessin/fond
°/ Pour le Sous Banc de Filtres 2 (basses fréquences) :
Classe1 = Dessin
Laboratoire L3i – Université de La Rochelle
Classe1 = Texte/fond Page 49](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-49-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Des exemples précédents, on a pu constater qu’on ne peut en aucun cas trouver un seul
seuil pour toutes les classes de documents anciens en notre possession, de plus on est jamais
certain du choix du seuil utilisé ; il est alors plus adéquat de définir deux seuils S1 et S2
suffisamment séparés pour définir les valeurs d’intensités correspondantes aux zones de texte
et de dessin sans risque d’affectation. Les pixels ayant des valeurs d’intensités comprises
entre S1 et S2 subiront à leur tour des traitements pour définir la classe la plus appropriée à
leur appartenance.
Cette conception du module de classification et d’affectation correspond à une
Classification Floue. De ce fait, sur les vecteurs caractéristiques, définis sur l’ensemble des
pixels, on applique une classification de type floue non supervisée dont le principe consiste à
trouver une partition de l’image, caractérisée par un vecteur des degrés d’appartenance d’un
pixel (i,j) à une classe Cl, résultats du filtrage dans chaque Sous – Banc de filtres.
Notez que pour chaque Sous – Banc de filtres, on définit 2 classes : pour les basses
fréquences, Classe1 : pixels des zones graphiques et Classe2 : le complément de Classe1
(pixels textes ou de fond), et pour les hautes fréquences, 2 autres classes, Classe1 : pixels des
zones de texte, et Classe2 : complément de Classe1 (pixels graphiques ou de fond). La
classification est appliquée sur le résultat de chaque Sous – Banc de Filtres.
L’idée qui soutient l’approche par la logique floue est l’impossibilité de décider sur
l’appartenance d’un pixel ou une région donnée de l’image suite au choix difficile d’un seuil
pour différencier le texte et le dessin et la présence de situation d’homogénéité des réponses
des zones de texte de celles des zones de dessin pour le filtre de Gabor. Pour remédier à ce
problème, on définit deux bornes (seuils) S1 et S2 tels que, en dehors de l’intervalle [S1,S2],
on est certain de la classe d’appartenance des pixels, et dans le cas contraire, on doit procéder
à un traitement qui permet de modifier les degrés d’appartenance, en analysant le contexte des
pixels et leurs réponses, afin de leur attribuer, si c’est possible, la classe la plus convenable.
Les degrés d’appartenance de chaque pixel se calculent par normalisation des résultats
de réponse de chaque filtre.
Laboratoire L3i – Université de La Rochelle Page 50](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-50-320.jpg)

![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Le processus de classification continue à s’exécuter jusqu’à stabilité de la solution
(résultat inchangé, ou presque, entre deux itérations successives)
VI.1. Matrice de confiance associée à la classification floue
La robustesse d’un algorithme de classification floue doit être accompagnée d’une
mesure de confiance.
Dans notre cas et pour chaque Sous – Banc de Filtres, on définit un Vecteur de
Confiance pour chaque pixel dont chacune de ses valeurs correspond à un pseudo degré
d’appartenance de ce même pixel résultant d’une opération de filtrage par un filtre de Gabor
spécifique du banc.
Le kème pseudo degré d’appartenance d’un pixel (i,j) est la valeur normalisée du
résultat du filtrage par le kème filtre de Gabor pour ce même pixel.
Pour chaque pseudo degré d’appartenance, la mesure de confiance est considérée dans
un voisinage de 9x9 (décidé d’une manière heuristique).
Pour tout pixel (i,j) VC =[v1,v2,v3,v4,v5,v6,v7,v8,v9,v10,v11,v12,v13,v14,v15]
Conf = [conf1, conf2, conf3,……, conf15] // vecteur de Confiance.
La mesure de confiance, pour tout pixel d’une image filtrée par un filtre spécifique, se
calcule comme suit :
- confk(i,j) : kème degré de confiance associé au kème pseudo
degré d’appartenance du pixel (i,j).
- N : nombre de voisins du pixel (i,j)
Cette quantité est une variance, elle permet de quantifier l’homogénéité et la
correspondance du pixel en question avec ses voisins. Si confk(i,j) est faible, alors le pixel (i,j)
est homogène avec ses voisin, sinon, si confk(i,j) est importante, ceci implique que le pixel
(i,j) diffère de ses voisins et cette conclusion influencera la prise de décision concernant la
classe d’appartenance de ce pixel : Cette mesure de confiance intervient durant le processus
de classification, et précisément dans la phase d’initialisation des classes et la mise à jour des
degrés d’appartenance, sous hypothèse d’homogénéisation des pixels du voisinage.
Le degré d’appartenance pour tout pixel (i,j) se calcule comme suit :
M : nombre de filtres de Gabor utilisés.
VI.2. Analyse du seuillage
La détermination de seuils est une étape primordiale pour notre processus de
classification floue adoptée. Un seuil doit vérifier la généralité et l’efficacité de calcul.
Du point de vue implantation, nous avons exploré deux méthodes sur trois pour fixer les
seuils utilisés.
Laboratoire L3i – Université de La Rochelle Page 52](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-52-320.jpg)




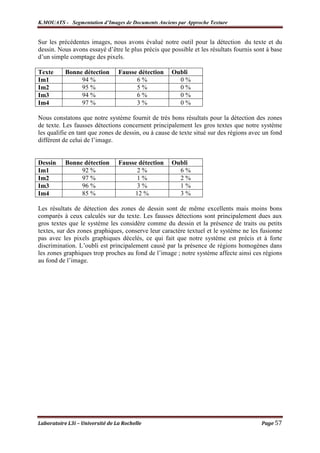

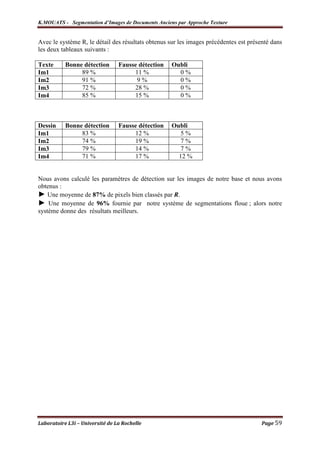


![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Discussion
Les résultats obtenus sont encourageants, cependant, les taux calculés sur les exemples
précédents ne sont pas de la même qualité pour d’autres types d’images de documents anciens
(images de documents avec bordures texturées, des images avec de grands portraits finement
texturées, images avec des zones ombrées,…), qui deviennent alors peu satisfaisants.
Les résultats de la segmentation sont de mieux en mieux que les zones graphiques soient
de plus en plus homogènes, cependant, si les zones graphiques contiennent des textures fines
(similaires à des lignes, hachurées), alors le système décident du comportent textuel de ces
zones.
La structure des ombres, qui est principalement linéaire, fait que ces zones seront classées
en tant que zones de texte.
La taille de la police peut basculer la décision du système sur l’appartenance des pixels de
ces zones, c-à-d que tant que la taille grandisse, le système change sa classe d’appartenance de
texte en dessin, ceci étant logique vu qu’un caractère de grande taille est qualifié en zone
homogène et se localise en basse fréquence.
L’analyse multirésolution semble être l’approche idéale pour palier à cet handicape. On utilise
une transformée en ondelette (la transformée de Haar par exemple) pour extraire les
informations à chaque échelle sur les alignements horizontaux, verticaux et obliques. La
détection des lignes de texte par rapport aux zones graphiques peut être réalisée avec une
complexité de calcul très faible. La transformé de Haar divise récursivement l’image en trois
parties par changement de résolution et applique des filtres différentiels directionnels (le filtre
de Gabor) (horizontal, vertical et oblique) du premier ordre dans chacune des parties. Il existe
donc une échelle pour laquelle les lignes apparaissent puis les blocs de lignes ainsi que les
zones graphiques [29].
Image originale transformée de Haar Orientations et résolutions
Figures VI.4. L’analyse multirésolution pour la détection des éléments d’une image de document [29]
Laboratoire L3i – Université de La Rochelle Page 62](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-62-320.jpg)



![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
représentant une classe particulière afin d'arriver à mettre en oeuvre un Système Générale
d'Analyse d’Images de Documents Anciens.
Les applications à prévoir comme complément de notre travail peuvent être résumées dans ce
qui suit :
► Intégration des mesures de texture de Tamura dans notre système et le valider sur une base
d’images de documents anciens ;
Tamura et al. [36] définissent six caractéristiques texturales {Coarseness, Contraste,
Direction, Similariré-ligne, Régularité et Rugosité}. Les trois premières caractéristiques sont
trop efficaces et fréquemment utilisées pour la description de la texture.
La Coarseness possède une relation directe avec l’échelle et le taux de répétition. Tamura et
al. la considèrent comme la propriété de texture la plus importante. Une image contient des
textures à différentes échelles et la Coarseness permet d’identifier la taille de la plus grande
texture existante.
Le Contraste vise à capturer la gamme dynamique des niveaux de gris dans une image avec la
polarisation de la distribution du noir et blanc.
La Direction est une propriété globale d’une région. Cette caractéristique texturale ne calcule
pas la différence entre les orientations et les motifs, mais elle mesure le degré total de la
direction.
La notion d’une Image de Tamura correspond au calcul d’une valeur de chacun des
paramètres précédents pour tout pixel d’une image ; on obtient alors une sorte de distribution
spatiale des caractéristiques texturales de l’image.
Le choix de cette solution pour l’intégrer à la signature définie par les sorties du Banc
de filtres de Gabor semble logique et bénéfique.
La Coarseness permet de donner un indice sur le type de la texture (Texte (fines) et
Dessin (Grosse)) ; le Contraste avec la polarisation du niveau de gris permet de décrire la
distribution de la zone/texture en question : une zone homogène pour une zone de texte et
aléatoire pour une zone de dessin. Et enfin, la Direction permet de spécifier l’orientation de la
texture en question : « direction définie » pour une zone de texte ou « pas de direction /
direction aléatoire » pour une zone graphique.
On en déduit que en plus des paramètres quantitatifs produits par le filtre de Gabor, les
indices de Tamura permettent de quantifier les propriétés qualitatives de nos images de
documents anciens, ce qui permet alors de définir un système complet (descripteurs multiples)
de segmentation d’images de documents anciens.
Les mesures de Tamura permettent de corriger ou de renforcer toute décision
d’affectation de pixel d’une image par notre système de segmentation utilisant le filtre de
Gabor.
► Détermination des propriétés typographiques des documents (types du texte / tailles des
fonte,…) ;
► Définir des primitives optimales et efficaces pour la quantification et la classification
(segments, régions,...) / afin d’éviter le parcours exhaustif et répétitif de tous les pixels ;
► Utiliser l'outil Gabor pour l'indexation et la consultation des bases de données d'Images de
Documents Anciens.
Laboratoire L3i – Université de La Rochelle Page 66](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-66-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
Références bibliographiques
[1]S. Raju S, P. Basa Pati, and A G Ramakrishnan, "Gabor Filter Based Block Energy for Text
Extraction from Digital Document Images", Proc. First International Workshop on Document Image
Analysis for Libraries (DIAL’04) – 2004 IEEE
[2]T. Randen, J. Håkon Husǿy, ''Segmentation of Text/Image Documents Using Texture Approaches''
Proc. Norway, Juin 1994.
[3]A. K. Jain and S. Bhattacharjee, ''Text Segmentation Using Gabor Filters for Automatic Document
Processing'', Machine Vision and Applications (1992) 5 : 169-184.
[4]M. Acharyya and M. K. Kundu, ''Document Image Segmentation Using Wavelet Scale-Space
Features'', IEEE Transactions on Circuits and Systems for Video Technology, Vol. 12, n° 12,
December 2002.
[5]N. Journet, R. Mullot, J.Y. Ramel, V. Eglin, "Ancient Printed Documents indexation :a new
approach", International Conference on Advances in Pattern Recognition, August 2005.
[6]K. Hammouda, ''Texture Segmentation Using Gabor Filters'', SYDE 775, Image Processing,
Department of Systems Design Engineering, University of Waterloo, Canada, December 2000.
[7]B. Allier, H. Emptoz, ''Font Type Extraction and Character Prototyping Using Gabor Filters'',
Proceeding of the Seventh International Conference on Document Analysis and Recognition (ICDAR
2003) - IEEE 2003.
[8]F. Alonso-Fernandez, J. Fierrez-Aguilar, J. Ortega-Garcia, ''An Enhanced Gabor Filter-Based
Segmentation Algorithm for Fingerprint Recognition Systems'', Proceedings of the 4th International
Symposium on Image and Signal Processing and Analysis «Proc. ISPA05» - 2005.
[9]Y. Smara, N. Ouarab, "Techniques de fusion et de classification floue d’images satellitaires
multisources pour la caractérisation et le suivi de l’extension du tissu urbain de la région d’Alger
(Algérie)", 2nd FIG Regional Conference – Marrakech, Morocco, December 2-5, 2003.
[10]L. Lazli et M.T. Laskri, "Nouvelle méthode de fusion de données pour l’apprentissage des
systèmes hybrides MMC/RNA", Revue ARIMA – CARI’04, Novembre 2005.
[11]A. Martin, "Fusion de classifieurs pour la classification d’images sonar", Revue des Nouvelles
Technologies de l’Information RNTI-1, 2004
[12]H. Ma and D. Doerman, "Font Identification Using Grating Cell Texture Operator",
[13]Y. Zhu, T. Tan and Y. Wang, "Font Recognition Based on Global Texture Analysis", IEEE
Transactions on Pattern Analysis and Machine Intelligence, Vol.23, N°10, October 2001.
[14]A.K. Jain, R.W. Durin, and J. Mao, "Statistical Pattern Recognition: A Review", IEEE
Transactions on Pattern Analysis and Machine Intelligence, Vol.22, N°1, January 2000.
[15]H. Hetzheim, "Separation of Different Textures in Images using Fuzzy Measures and Fuzzy
Functions and their Fusion by Fuzzy Integrals",
[16]N. Papamarkos, "A Technique for Fuzzy Document Binarization", DocEng’OI, November 9-10,
2001, Atlanta, Georgia, USA.
Laboratoire L3i – Université de La Rochelle Page 67](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-67-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
[17]G. Rellier, X. Descombes, F. Falzon, J. Zerubia, "Analyse de Texture Hyperspectrale par
Modélisation Markovienne", Projet ARIANA (projet commun I3S/INRIA), rapport de recherche
I3S/RR-2002-47-FR, Septembre 2002
[18]B. Allier, "Contribution à la Numérisation des Collections : Apports des Contours Actifs", Thèse
en Informatique, Institut National Des Sciences Appliquées de Lyon, 2003.
[19]B.S. Manjunath and W.Y. Ma, "Texture Features for Browsing and Retrieval of Image Data",
IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.18, N°8, August 1996.
[20]M. Grabisch and M. Nicolas, "Classification by Fuzzy Integrals – Performance and tests", Fuzzy
Sets & Systems, Special Issue on Pattern Recognition, 65: 255-271, 1994.
[21]J. Ilonen, J.K. Kämäräinen and H. Kälviäinen, "Efficient Computation of Gabor Features",
Department of Information Technology, BP 20, Finland, rapport de recherché, 2005.
[22]H. Ma and D. Doerman, "Gabor Filter Based Multi-Class Classifier for Scanned Document
Images", Proceedings of the Seventh International Conference on Document Analysis and
Recognition, 2003.
[23]T.P. Weldon, W.E. Higgins, "Design of Multiple Gabor Filters for Texture Segmentation",
Proceedings of ICASSP- May 7-10, Atlanta, Georgia, USA, 1996.
[24]V. Levesque, "Texture Segmentation using Gabor Filters", Centre for Intelligent Machines,
McGill University, December 6, 2000.
[25]P. Kruizinga, N. Petkov and S.E. Grigorescu, "Comparison of Textures Based on Gabor
Filters", Proceedings of the 10th International Conference on Image Analysis and Processing,
Venice, Italy, September 27-29, 1999, pp. 142-147.
[26]C.H. Wei, C.T. Li, and R. Wilson, "A General Framework for Content-Based Medical
Image Retrieval with its Application to Mammograms",
[27]L. Likforman-Sulem, "Apport du traitement des images à la numérisation des documents
manuscrits anciens", 2003
[28]A. Belaïd, H. Emptoz, G. Vignaux, "Document et contenu : création, indexation,
navigation", CNRS, Février 2004
[29]F. Le Bourgeois, H. Emptoz, E. Trinh, F. Muge, C. Pinto et I. Granado, "Wp4.3-4
Numérisation, Traitement et Interprétation des Images de Documents Anciens ", Project
DEBORA Telematics Applications Programme n° 5608 -
[30]I. Quidu, J.P. Malkasse, P. Vilbe, G. Burel, "Fusion Multi-Attribut d’Images Sonar",
GRETSI - Toulouse, 10-13 Septembre 2001.
[31]S. Khedekar, V. Ramanaprasad, S. Setlur, "Text-Image Separation in Devanagari
Documents", Proceedings of the Seventh International Conference on Document Analysis and
Recognition (ICDAR 2003).
Laboratoire L3i – Université de La Rochelle Page 68](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-68-320.jpg)
![K.MOUATS - Segmentation d’Images de Documents Anciens par Approche Texture
[32]”Sauvegarde du Patrimoine Culturel de Civilisation Ancienne”, Projet SAPCCA –
Laboratoire LRI – Université Badji Mokhtar – Annaba – Algérie.
[33] J.C.Bezdek, "Pattern Recognition with Fuzzy Objective Function Algorithms", Plenum
Press, New York, 1981.
[34]W. Pedrycz, "Knowledge-Based Clustering: Clustering and Fuzzy Clustering", ISBN 0-
471-46966-1 Cpyright © 2005 John Wiley & Sons, Inc.
[35]T. Gadi, R. Bnslimane, "Segmentation hiérarchique floue", Traitement du Signal 2000,
Volume 17-n°1.
[36]P. Howarth, S. Rüger, "Robust Texture Features for Still-Image Retrieval", IEE Proc.Vis.
Image Signal Process, Vol. 152, n° 6, December 2005
Laboratoire L3i – Université de La Rochelle Page 69](https://image.slidesharecdn.com/mouatsmaster2006-130224123134-phpapp01/85/Segmentation-d-images-de-documents-anciens-par-approche-texture-Mo-69-320.jpg)




Ce document présente une recherche sur la segmentation d'images de documents anciens utilisant une approche texture, en se concentrant sur l'application du filtre de Gabor. L'étude aborde les particularités des documents anciens qui compliquent l'application des techniques classiques d'analyse, et propose un système de segmentation innovant pour extraire des zones informatives. Le travail inclut également une discussion sur les méthodes existantes et des résultats expérimentaux de la méthode proposée.













































