Téléchargé 37 fois



![1 Le Monde Des Systèmes Temps Réel 111
PARTIE 1:Système Temps Réel «Concepts & Conception»:
Objectif:
Ce chapitre a pour but d’introduire les systèmes temps réel. Il illustre certaines des
difficultés que l’on rencontre lorsque l’on implémente ce genre de système. Un système
temps réel est correct en fonction de ses résultats et du moment auwquel il les produit.
Les contraintes de temps et de ressources sont déterminantes pour le fonctionnement de
ces systèmes..
I- Introduction:
Au fur et à mesure que le prix sur le matériel diminue, on intègre des ordinateurs
dans de plus en plus de systèmes. Ces logiciels interagissent directement avec des
périphériques matériels, et leurs logiciels doivent pouvoir réagir suffisamment vite aux
événements dont le système assure le suivi et le contrôle. Du fait de ce besoin, pour le
logiciel, de répondre à des événements «temps réel», le système logiciel de contrôle a
été qualifié de système «temps réel». Un système temps réel consiste en un ensemble
d’entités contrôlées et un sous-système de contrôle. Ce dernier est formé d’un ensemble de
systèmes d’ordinateurs, tandis que les entités contrôlées peuvent être un large éventail de
systèmes à comportement mécanique ou tout dispositif, du simple mélangeur au robot
[Stankovic91]. Typiquement, le sous-système de contrôle exécute des programmes de
contrôle pour recevoir des données de l’environnement et/ou pour émettre des commandes
aux entités contrôlées [Chung95].
Un système temps réel (STR) est un système dédié à des applications spécifiques, en
particulier, les systèmes de contrôle. Des capteurs recueillent de l’information qu’ils
fournissent au calculateur(ordinateur). Ce dernier s’occupe de réaliser le contrôle désiré et
donne les résultats pour d’éventuelles interventions.
Les systèmes embarqués constituent un sous-ensemble de systèmes temps réel,
caractérisés par leur contrôle de systèmes mécaniques tels que les systèmes de contrôle
de bateaux, de véhicules, de machines à laver, etc.
Comme on a besoin de répondre à des événements qui arrivent à n’importe quel
moment, on doit organiser l’architecture d’un système temps réel de manière à pouvoir
transférer le contrôle au composant approprié dès la réception d’un événement. C’est
pourquoi, on conçoit le système comme un ensemble de processus parallèles, et qui
coopèrent entre eux. Une partie du système temps réel (quelquefois appelée exécutif
temps réel) est dédiée à la gestion de ces processus.
II-Définition d’un système temps réel:
Avant d’aller plus loin, il est utile d’essayer de définir la phrase: «Système Temps Réel»
(STR) avec plus de précision. Il y a une multitude d’interprétations de la nature exacte d’un
STR; cependant, elles ont tous en commun la notion du «temps de réponse (le temps
nécessaire pour qu’un système puisse générer des sorties à partir d’entrées associées). Le
«Oxford Dictionary of Computing» donne la définition suivante pour un STR: «C’est
n’importe quel système dans lequel le temps, au bout duquel la sortie est produite, est
significatif. C’est généralement dû au fait que l’entrée correspond à certains flux dans le
monde physique, et la sortie doit appartenir aux même flux. La différence entre le temps de
l’entrée et celui de la sortie doit être suffisamment petite pour avoir un temps de réponse
acceptable.»
Ici, le mot «temps de réponse» est pris dans le contexte du système total. Par exemple, dans
un système de contrôle de missiles téléguidées, la sortie est exigée dans quelques
1
1](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-3-320.jpg)
![1 Le Monde Des Systèmes Temps Réel 222
millisecondes, cependant, dans les systèmes de contrôle d’assemblage de voitures, la réponse
peut être exigée seulement dans une seconde.
Young[1982] définit un STR comme suit: «C’est tout système ou activité de traitement
d’information qui doit répondre à une entrée stimulée, extérieurement générée, dans une
période finie et bien spécifique.»
Dans le sens le plus général, ces deux définitions couvrent une catégorie plus large d’activités
d’ordinateur. Par exemple, un système d’exploitation comme UNIX peut être considéré
comme un STR dans le cas où un utilisateur introduit une commande et il va attendre pour
(recevoir) une réponse dans quelques secondes. Heureusement, il n’est pas généralement
désastreux si la réponse n’est pas rapide.
Ces types de systèmes peuvent être distingués de ceux où la panne dans la réponse peut être
considérée aussi mauvaise qu’une réponse fausse. Bien entendu, c’est cet aspect qui distingue
un STR de ceux où le temps de réponse est important mais n’est pas crucial.
Par conséquent, la correction d’un STR ne dépend pas seulement de la logique des résultats
d’un calcul, mais de plus, du temps dans lequel les résultats sont produits.
Les praticiens dans le domaine de la conception des systèmes d’ordinateur à temps réel
distinguent généralement entre les STR hards(stricts) et les STR soft(relatifs).
Les STR hards sont ceux où il est absolument impératif que les réponses se produisent dans
un échéance spécifié.
Les STR softs sont ceux où les temps de réponse sont importants mais le système restera
fonctionner correctement si les échéances sont occasionnellement perdus.
Les systèmes softs peuvent être distingués par eux même des systèmes interactifs dans
lesquels il n’y a pas des échéances explicites.
Dans un STR soft ou hard, l’ordinateur a généralement une interface directe avec quelques
équipements physiques et il est orienté à contrôler ou à couvrir l’opération de ces
équipements.
Une caractéristique clé de toutes ces applications est le rôle de l’ordinateur comme un
composant de traitement d’information dans un système d’ingénierie large. Il est pour cette
raison que de telles applications sont reconnues comme des Systèmes Temps Réel.
III-Exemples de systèmes temps réel:
III-1-Contôle de processus:
La première utilisation d’un ordinateur comme un composant dans un système
d’ingénierie s’est faite à la fin de 1960 dans le contrôle des processus industriels.
Considérons l’exemple montré dans la figure I-1, où l’ordinateur effectue une seule activité:
c’est d’assurer le passage d’un flux de liquide donné dans un pipe par le biais d’une vanne. Si
on détecte une augmentation dans le flux, l’ordinateur doit répondre en alternant l’angle de la
vanne; cette réponse doit se produire dans un temps fini si le dispositif de réception en fin du
pipe ne se surchargera pas.
III-2-La production:
L’utilisation des ordinateurs dans la production est devenue essentielle de telle manière
qu’on puisse garder les coûts de la production minimaux avec amélioration de la productivité.
L’ordinateur coordonne entre une variété d’engins tels que des manipulateurs, machines à
outils, …etc.
III-3-Communication, commande et contrôle:
On peut citer comme exemple, la réservation de places sur avion, les centres médicaux
pour le suivi automatique des malades et la gestion des comptes bancaires.
2
2](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-4-320.jpg)

![1 Le Monde Des Systèmes Temps Réel 444
général, qui sera utilisé pour la programmation effective des STR, doit supporter, et
facilement ces caractéristiques.
IV-1-Taille et complexité:
Il est souvent constaté que la plupart des problèmes associés au développement des
logiciels sont ceux relatifs à la taille et la complexité. Ecrire de petits programmes présente un
problème non significatif, comme il peut être conçu, codé, maintenu et compris par une seule
personne. Si cette personne quitte la compagnie ou cette institution qui utilise ce logiciel, une
autre personne peut apprendre et comprendre ce programme en une durée relativement petite.
Malheureusement, tous les logiciels ne présentent cette caractéristique qu’on veut bien
l’atteindre et l’avoir.
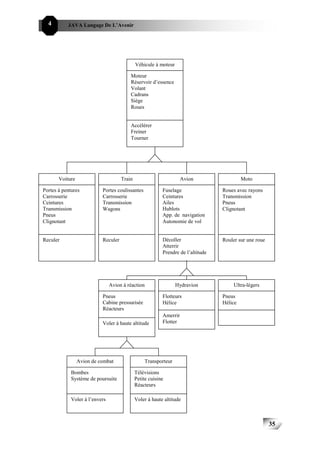
Horloge Algorithmes pour Système
le contrôle digital interface d’ingénierie
Temps réel
Insertion de données Système de
(enrichissement) contrôle distant
Base de
données
Extraction de données Dispositifs
et affichage d’affichage
Console d’un
opérateur Interface opérateur
Real Time computer
Fig I-2:STR typique
Lehman et Belady[1985], dans une tentative de caractérisation des systèmes répandus,
rejettent la notion simple et intuitive, que la taille est simplement proportionnelle au nombre
d’instructions, lignes de code ou modules.
Par définition, les STR doivent répondre aux événements du monde réel. La variété
associée à ces événements doit être traitée attentivement.
Le coût de la reconception ou la réécriture du logiciel répondant aux exigences du
changement continu du monde réel est extrêmement important. De ce fait, les STR doivent
être extensibles pour faciliter leur maintenance et améliorer leur performance.
4
4](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-6-320.jpg)

![1 Le Monde Des Systèmes Temps Réel 666
s’assurer que le comportement, au pire des cas, ne produise aucun retard défavorable durant
les périodes critiques du fonctionnement du système.
En fournissant une puissance de traitement adéquate, en exigeant le support d’exécution, on
permettra au programmeur de :
Spécifier les temps dans lesquels les actions doivent être accomplies.
Spécifier les temps dans lesquels les actions doivent se terminer.
Répondre à des situations où les exigences temporelles se changent de manière
dynamique.
IV-6-Interaction avec les interfaces du matériel:
La nature des STR exige que les composants de l’ordinateur doivent interagir avec le
monde extérieur. Ils ont besoin de capteurs et actionneurs pour une large gamme de dispositifs
du monde réel. Ces dispositifs interagissent avec l’ordinateur via des registres
d’entrées/sorties. Les dispositifs peuvent générer des interruptions afin de signaler au
processeur que certaines opérations sont accomplies ou qu’il y avait des erreurs qui se sont
produites.
De nos jours, vu la variété des dispositifs et la nature du temps critique de leurs interactions
associées, leur contrôle doit être direct et non pas à travers les fonctions du système
d’exploitation.
IV-7-Implémentation efficiente:
Vu la nécessité du traitement du temps critique dans les STR, l’implémentation
efficiente (de haute qualité, efficace …) de ces systèmes devient de plus en plus nécessaire et
importante. Il est intéressant que l’un des bénéfices majeurs de l’utilisation d’un langage de
haut niveau est qu’il permet au programmeur de réaliser une implémentation abstraite loin de
tout détail, en se concentrant sur la résolution du problème. Le programmeur doit toujours être
concerné par le coût de l’utilisation de caractéristiques particulières d’un langage. Par
exemple, si la réponse à quelques entrées doit apparaître au bout d’une micro-seconde, ce
n’est plus la peine d’aller utiliser un langage dont l’exécution prend une milli-seconde.
V-Spécification des besoins:
Tout projet informatique doit impérativement commencer par une description
informelle des objectifs à atteindre. Cela devra être suivi par une analyse des besoins. C’est à
ce stade que la fonctionnalité du système est définie. Dans le terme de «facteurs spécifiques
temps réels», le comportement temporel du système doit être explicite, tout comme les
besoins en fiabilité et comportementaux du logiciel en cas où une panne d’un composant
survienne. De plus, cette phase définit quels sont les tests d’acceptante à appliquer au logiciel.
Il est de plus nécessaire de construire un modèle de l’environnement de l’application. C’est
une caractéristique des STR qu’ils ont des interactions importantes avec leur environnement.
Après la phase d’analyse vient celle de la concrétisation de la spécification des besoins. C’est
à partir de cette étape qu’apparaît la conception. C’est une phase critique dans le cycle de vie
d’un logiciel passant à un niveau plus élevé dans la mise au point du STR.
VI-Motivations de conception:
Dans cette section, nous synthétisons les différentes étapes de conception de
systèmes temps réel. Ces étapes se basent sur des paramètres de qualité de service
[IEEE97] et elles doivent prendre en compte les besoins d’évolution et donc de la
maintenance.
Dans un système intégré à grande échelle, l’une des étapes du processus de
conception consiste à concevoir les systèmes, et à partager les fonctions entre matériel et
6
6](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-8-320.jpg)
![1 Le Monde Des Systèmes Temps Réel 777
logiciel. On peut considérer que le processus de conception des systèmes intégrés suit
une série d’étapes:
(1) Identifier les événements que le système doit traiter et les réactions associées.
(2) Identifier les contraintes de temps à appliquer à chaque événement, ainsi qu’à la
réponse qui lui est associée.
(3) Regrouper le traitement des événements et des réactions dans différents processus
parallèles. Un bon modèle d’architecture consiste à associer un processus à chaque
classe d’événement et à chaque classe de réaction, comme dans la figure I-2. Pour
chaque événement et chaque réaction, concevoir les algorithmes qui effectueront le
traitement nécessaire. On doit développer la conception des algorithmes à ce stade
afin d’avoir une idée du temps de traitement nécessaire.
(4) Concevoir un système d’ordonnancement qui permettra de démarrer chaque
processus au moment opportun afin qu’il puisse effectuer son traitement dans des
contraintes de temps données.
(5) Intégrer le système avec un exécutif temps réel.
Naturellement, c’est un processus itératif [William96, gestion des itérations
Computer97]. Une fois qu’il a établi l’architecture (découpage en processus) et choisi la
stratégie d’ordonnancement, le concepteur doit effectuer des estimations et des
simulations complètes du système pour vérifier qu’il respectera ses contraintes de temps.
Contrôleur du
Capteur Capteur
Réponse
Traitement des
Données
Actionneur Contrôle de
l’Actionneur
Fig.I.3 Architecture d’un système de contrôle
Dans beaucoup de cas, ces simulations vont révéler des défauts de comportement
du système. L’architecture, ou l’ordonnancement, ou l’exécutif, ou les trois à la fois
devront être reconçus afin de pouvoir «tenir» les contraintes de temps. Il est difficile
d’estimer le temps d’exécution d’un système temps réel. Du fait de la nature
imprévisible des événements apériodiques, les concepteurs doivent faire des hypothèses
sur la probabilité pour qu’ils apparaissent (et donc demandent un service) à un instant
donné. Ces hypothèses peuvent s’avérer incorrectes et les performances du système
délivré ne seront pas suffisantes. Dasarathy [DAS85] traite de la validation des temps
d’exécution.
Du fait que les processus d’un système temps réel doivent coopérer, le concepteur doit
coordonner les communications entre processus. Les mécanismes de coordination des
7
7](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-9-320.jpg)
![1 Le Monde Des Systèmes Temps Réel 888
processus assurent l’exclusion mutuelle lors de l’accès à des ressources partagées. Lorsqu’un
processus est en train de modifier une ressource partagée, les autres processus ne peuvent pas
en faire de même. Parmi les mécanismes d’exclusion mutuelle on trouve les sémaphores, les
moniteurs et les régions critiques.
Le langage choisi pour l’implémentation de systèmes temps réel peut avoir lui aussi une
influence sur la conception. Ada [Taft92] a été conçu à l’origine, pour implémenter des
systèmes intégrés, et il dispose de caractéristiques comme la gestion des tâches, les exceptions
et les clauses de représentation. La notion de rendez-vous représente un bon mécanisme pour
la synchronisation des tâches. Malheureusement, ce mécanisme n’est pas adapté à
l’implémentation de systèmes temps réel durs.
Les systèmes temps réel durs sont souvent écrits en assembleur pour pouvoir tenir les
contraintes de temps. Parmi les autres langages, on trouve des langages de niveau système
comme C. Ils nécessitent un noyau d’exécution supplémentaire pour gérer le parallélisme.
Afin de pouvoir gérer le développement des STR complexes, deux approches
complémentaires sont souvent utilisées: décomposition et abstraction. Toutes les deux
forment des concepts de base des méthodes de génie logiciel.
La décomposition, comme son nom l’indique, implique le partitionnement systématique d’un
système complexe en parties plus fines jusqu’à ce qu’on puisse isoler ses composants, afin de
pouvoir les gérer de manière décentralisée. A chaque niveau de décomposition, on fait
correspondre un autre niveau de description et une méthode de documentation de cette
description.
L’abstraction permet de considérer les détails et les particularités concernant
l’implémentation. Cela permet de simplifier la vision en vers le système et les objectifs à
atteindre en gardant ses propriétés et caractéristiques.
VI-1-Encapsulation:
La conception hiérarchique d’un logiciel permet la spécification et le développement
des sous-composants d’un programme. Le besoin à l’abstraction implique que ces sous-
composants doivent être bien définis en terme de rôle, clairs et avoir des interconnexions et
interfaces non-ambigües. Si la spécification entière du système logiciel peut être vérifiée
seulement en terme de spécification des sous-composants immédiats, alors la décomposition
est dite compositionnelle. C’est une propriété importante quand on veut analyser
formellement les programmes.
Les programmes séquentiels sont particulièrement amenés à des méthodes compositionnelles
et un nombre de techniques sont utilisées pour encapsuler et représenter les sous-composants.
VI-2-Cohésion et couplage:
Les deux formes d’encapsulation discutées dans la section précédante nous amène à
l’utilisation de modules avec des interfaces bien définies (et abstraites). Mais comment un
grand système peut être décomposé en modules? La réponse est liée aux méthodes de
décomposition des logiciels. Cependant, avant de discuter ces méthodes, il est approprié de
considérer des principes plus généraux nous permettant une bonne encapsulation.
Cohésion et couplage sont deux parmi les métriques décrivant les relations entre les modules.
La cohésion est liée à la bonne concordance entre les modules.
Allworth & Zobel[1987] donnent six mesures de cohésion:
1. Coïncidence: les éléments du module ne sont pas liés autre que dans un contexte très
superficiel.
2. Logique: les éléments du module appartiennent à la même famille, en terme de vision
globale du système, mais non pas en ce qui concerne l’application (logiciel) en cours.
8
8](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-10-320.jpg)
![1 Le Monde Des Systèmes Temps Réel 999
3. Temporel: les éléments du module sont exécutés à des temps similaires.
4. Procédural: les éléments du module sont utilisés ensembles dans la même section du
programme.
5. Communication: les éléments du module travaillent sur la même structure de données.
6. Fonctionnel: les éléments du module travaillent en collaboration afin de contribuer à la
performance d’une seule fonction du système.
Le couplage, par comparaison, est une mesure d’interdépendance des modules du
programmes. Deux modules ont un couplage fort s’ils échangent entre eux des informations
de contrôle. Par contre, ils perdent le couplage si les modules ne communiquent que des
données. Une autre façon de voir le couplage est de considérer la facilité de changer un
module (d’un système complet ) et le remplacer par un autre.
Dans toutes les méthodes de conception, la meilleure, et celle ayant une bonne décomposition,
vérifie une forte cohésion et un couplage minimum.
Ce principe est également vrai dans les domaines de la programmation séquentielle et
concurrente.
VI-3-Approches formelles:
Elle consiste à modéliser le comportement des systèmes concurrents par l’utilisation des
réseaux Petri [Brauer 1980]. Vue la variété des représentations obtenues, on introduit, dans le
processus de modélisation, le concept des réseaux de transition prédicatives.
La notion CSP (Communicating Sequential Processes) est développée, permettant la
spécification et l’analyse des systèmes concurrents.
Une logique temporelle (extension de la logique des prédicats et propositionnelle) a été
introduite avec de nouveaux opérateurs afin de pouvoir exprimer les propriétés temporelles.
VII-Méthodes de conception:
L’industrie du temps réel utilise des méthodes structurées et les approches du génie
logiciel pour la mise en œuvre des STR, vu que ces techniques sont applicables à tous les
systèmes de traitement d’information. Ces méthodes ne fournissent pas un support spécifique
au domaine du temps réel, et ils manquent en richesse voulue quand on épuise toutes les
potentialités des langages d’implémentation utilisés.
Typiquement, une méthode de conception structurée utilise un diagramme, dans lequel des
arcs orientés schématisent le flux de données à travers le système, et les nœuds désignés
représentent les sites dans lesquels les données sont transformées et donc traitées.
Dans la littérature, on trouve les méthodes JSD (Jackson’s System Development), Mascot3 et
PAMELA.
Dans la méthode JSD, on utilise une notation pour la spécification et l’implémentation
(conception détaillée). Bien entendu, l’implémentation n’est pas seulement une description
détaillée de la spécification, mais de plus, elle est le résultat de l’application de
transformations à cette dernière afin d’améliorer l’efficience.
La méthode est basée sur un graphe comportant des processus et un réseau de connexions.
Les processus sont de trois catégories:
1. Processus d’entrée: détectant les actions dans l’environnement en les faisant passer au
système.
2. Processus de sorti : passant les réponses du système à l’environnement.
3. Processus internes.
Les processus peuvent être liés de deux manières différentes:
1. Par des connexions asynchrones de blocs de données qui sont sauvegardées.
2. Par des connexions de vecteurs d’état (ou inspection).
9
9](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-11-320.jpg)

![1 Le Monde Des Systèmes Temps Réel 111111
VIII-Implémentation:
Le langage de programmation est une interface importante et primordiale entre la
spécification des besoins et l’exécution du code machine. La conception d’un langage reste un
domaine de recherche actif. Malgré le passage naturel de la conception des systèmes vers
l’implémentation, les possibilités expressives des langages récents ne sont pas liées aux
méthodologies de conception adoptées. Cette adoption poursuit logiquement l’étape de
compréhension prévisible de l’étape d’implémentation.
Il est possible d’identifier trois classes de langages de programmation qui sont utilisées dans
le développement des systèmes temps réels. Ces langages sont: le langage d’assemblage, les
langages d’implémentation séquentielle des systèmes et les langages concurrents de haut
niveau.
IX-Critères da base d’un langage de conception:
Un langage de programmation des STR peut être conçu seulement pour répondre aux
besoins du système. Cependant, il est rarement limité à cette fin.
La plupart des langages temps réel sont aussi utilisés comme des langages d’implémentation
des systèmes à objectifs généraux, pour des applications spéciales telles que les compilateurs
et les systèmes d’exploitation.
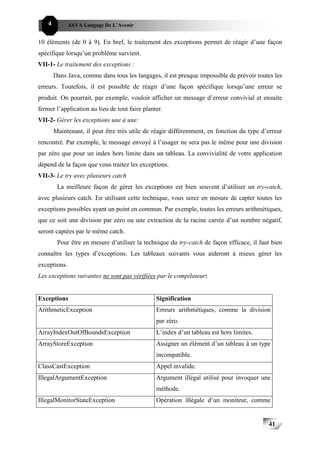
Young[1982] liste les six critères de base d’un langage de conception temps réel:
1. La sécurité: la sécurité, dans la conception d’un langage, mesure la possibilité de détecter
des erreurs de programmation, d’une manière automatique, par le compilateur ou par le
support d’exécution. Evidemment, il y a une limite pour les types et nombres d’erreurs
que le système du langage peut détecter.
L a sécurité implique la possibilité de:
Détecter facilement des erreurs et très tôt durant le développement du programme, et
par conséquent, une réduction dans le coût de la correction et la maintenance.
Avoir une compilation facile ne provoquant aucune extension au temps, donc le
programme peut être exécuté autant de fois qu’on le compile.
L’inconvénient de la sécurité est la complication dans sa mise au point, dans le cas d’un
langage complexe, ce qui implique un surcoût dans le temps de la compilation et
l’exécution.
2. La lisibilité: la lisibilité d’un langage dépend d’une multitude de facteurs concernant le
choix des mots clés appropriés, la possibilité de définir des types et la facilité de
modulariser un programme. De ce fait, on offre un langage avec une clarté suffisante,
permettant d’assimiler les principaux concepts d’opérations d’un programme particulier
par une simple lecture du texte du programme.
Une meilleure lisibilité implique:
La réduction des coûts de la documentation.
Une meilleure sécurité.
Une bonne et parfaite maintenabilité.
3. La flexibilité: un langage doit être suffisamment flexible, permettant au programmeur
d’exprimer toutes les opérations demandées d’une manière cohérente et graphique.
4. La simplicité: la simplicité possède les avantages suivants:
Minimisation de l’effort exigé pour produire les compilateurs.
Réduction du coût associé à l’apprentissage du programmeur.
Diminution de la possibilité de commettre des erreurs de programmation.
5. La portabilité: un programme doit être indépendant du matériel de l’exécution. pour un
STR, cela est difficile à réaliser, car c’est comme si on va remplacer une partie du
programme par une autre, ce qui implique des manipulations de ressources matérielles.
11
11](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-13-320.jpg)

![1 Le Monde Des Systèmes Temps Réel 131313
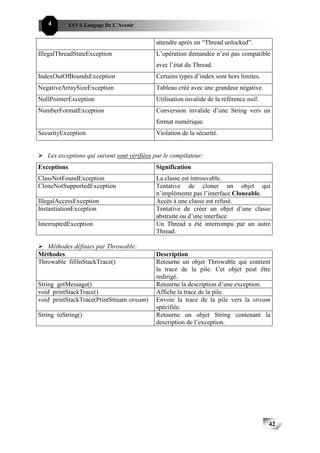
XI- Analyse des Contraintes de Tâches:
Un modèle de tâches temps réel permet de spécifier l’architecture fonctionnelle
d’un système temps réel. Chaque tâche est définie par un ensemble d’attributs décrivant
les contraintes auxquelles elle est soumise.
Traditionnellement, les applications temps réel étaient souvent décrites par le
modèle des tâches périodiques [Liu73]. Ce modèle décrit une application temps réel par
un ensemble fini (appelé aussi configuration) de tâches périodiques. Une variante de ce
modèle consiste à prendre en compte les tâches apériodiques. Dans ce modèle, toutes les
tâches doivent s’exécuter jusqu’à leurs fins. Cependant, pour des besoins nouveaux des
systèmes temps réel, certaines tâches n’ont pas la contrainte de terminer nécessairement
leur exécution. Ce qui a donné naissance à deux nouveaux types de modèles: le modèle
des tâches incrémentales et le modèle des tâches à résultats imprécis.
Diverses variantes de ces modèles ont été développées. Certaines d’entre elles sont
le résultat d’intégration des modèles existants. D’autres traitent des contraintes de type
ressources ou synchronisation.
XI-1-Contraintes de temps:
La plupart des contraintes de temps sont celles introduites par les modèles de
tâches périodiques et apériodiques. Ces deux types de modèles sont souvent utilisés en
temps réel. En effet, un système temps réel est souvent concerné par le contrôle d’un
comportement continu (procédé) qui nécessite des actions répétitives (tâches
périodiques) ou aléatoires (apériodiques).
Il existe trois types de tâches temps réel qui sont conçues pour superviser et
contrôler les différentes fonctions: Les tâches périodiques, sporadiques et apériodiques
[Klein94].
Les tâches périodiques sont les plus souvent trouvées dans les systèmes temps réel.
Afin de superviser un système physique ou un processus, le système d’ordinateur doit
capter régulièrement des informations sur le processus et réagir quand des résultats
appropriés sont obtenus ou des informations spécifiques sont lues. Cet échantillonnage
régulier d’informations est effectué par la tâche périodique par une série continue
d’invocations régulières, commençant par une invocation initiale à un certain temps I.
Les invocations se produisent périodiquement toutes les T unités de temps. Chacune de
ces invocation possède un temps d’exécution de C unités qui peut être déterministe ou
stochastique. C indique souvent la borne maximale (ou le pire des cas) du temps
d’exécution.
Chaque invocation de tâche aura une contrainte de temps explicite, appelé
l’échéance qui signifie que l’invocation doit se terminer avant un certain temps D après
son passage à l’état prêt. Ainsi, la première invocation doit se terminer dans le temps
I+D, la deuxième dans I+T+D, etc.
Les tâches périodiques sont habituellement invoquées par les temporisateurs
internes avec une périodicité choisie telle qu’elle assure une latence suffisamment courte
pour réagir aux événements de changement dans l’environnement en question.
Les tâches sporadiques et apériodiques sont invoquées à des intervalles irréguliers.
La tâche sporadique possède une échéance stricte (hard) et une borne sur l’intervalle
séparant deux invocations. La tâche apériodique peut s’effectuer avec un intervalle
aléatoire qui sépare deux invocations.
Par ailleurs, un processus est une séquence d’opérations qui doivent être exécutées
dans un ordre prescrit [Xu93]. Les processus peuvent être divisés en deux catégories: les
tâches de la première catégorie ont une échéance «stricte» (hard), c’est-à-dire que la
satisfaction de ses échéances est critique pour le fonctionnement du système, celles de la
13
13](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-15-320.jpg)
![1 Le Monde Des Systèmes Temps Réel 141414
deuxième catégorie ont des échéances «relatives» (soft), en ce sens que bien qu’un court
temps de réponse est souhaitable, un dépassement occasionnel de l’échéance peut être
toléré.
XI-2-Contraintes d’importance:
Les tâches d’une application temps réel ne sont pas toutes aussi importantes les unes que
les autres. En effet, du point de vue du concepteur d’une application, une tâche peut être
plus importante qu’une autre. Cette caractéristique de la tâche est déterminée par des
paramètres (poids, degré d’urgence, priorité externe, tâche critique, etc.). L’échec d’une
tâche critique peut entraîner l’arrêt d’exécution du système, situation qui peut être
catastrophique. Par exemple, dans un système de contrôle de vol, le concepteur de
l’application peut associer un poids fort à la tâche qui contrôle la stabilité de l’avion,
afin de refléter sa nature critique. Si cette tâche échoue dans le respect de son échéance,
l’avion peut s’écraser. Par contre, il accorde un faible poids à la tâche qui contrôle
l’enregistreur de vol.
XI-3-Contrainte d’interruption
Cette contrainte permet d’exprimer si une tâche est interruptible ou non. Par
exemple, dans un système temps réel réparti, une tâche qui ne fait que du calcul interne,
peut être interrompue. Par contre, la tâche chargée de l’émission d’une trame ne peut
être interrompue et elle doit se terminer. Si son émission est interrompue, elle doit la
recommencer complètement. Une tâche interruptible peut être interrompue par une autre
tâche prioritaire. Son exécution peut être reprise ultérieurement. Lorsqu’une tâche est
interrompue, elle peut être forcée de libérer temporairement les ressources qu’elle a
acquises.
XI-4-Contrainte de terminaison
Dans des conditions de surcharge, certaines applications temps réel se contentent
d’exécuter quelques tâches partiellement. De telles applications peuvent se contenter de
résultats acceptables. La contrainte de terminaison ont été prises en compte dans les
modèles de tâches incrémentales et les modèles de tâches à résultats imprécis.
XI-5-Contraintes événementielles:
Un événement peut démarrer certaines tâches et/ou terminer d’autres. Les
conditions d’activation/terminaison de tâches peuvent être décrites par une combinaison
d’opérateurs de la logique temporelle (avant, après, etc.) [Chung95, Sahraoui85] avec
des arguments qui sont (une date, un changement d’état, une expiration d’un délai, etc.).
Activation/terminaison d’une tâche peut être utilisé aussi bien pour décrire des
contraintes temporelles que des contraintes décrivant son interaction avec d’autres
tâches.
Comme ces contraintes peuvent exprimer d’autres situations (autres que les contraintes
de temps), cela justifie de les considérer indépendamment et dans la partie des
contraintes intrinsèques à une tâche.
XI-6-Les contraintes extrinsèques:
Les contraintes extrinsèques à une tâche décrivant les contraintes résultant de son
interaction avec d’autres tâches. Au cours de leur exécution, les tâches ne sont pas
indépendantes les unes des autres (relations de coopérations, relations de compétition,
etc.). Les relations de coopération indiquent l’existence d’un ordre d’exécution, de
14
14](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-16-320.jpg)
![1 Le Monde Des Systèmes Temps Réel 151515
synchronisation, de communication, etc. Les relations de compétition indiquent la
manière avec laquelle les tâches utilisent des ressources partagées.
Généralement, dans les applications informatiques, la mise en œuvre des
contraintes de coopération et de compétition est réalisée par des mécanismes de
synchronisation (rendez-vous, moniteur,…), d’exclusion mutuelle (sémaphores,…), de
communication (boites aux lettres,…), et bien d’autres.
XI-7-Contraintes d’accès aux ressources:
Les tâches utilisent des ressources disponibles en nombre limité pour lesquelles
elles entrent en compétition. La bonne utilisation des ressources partagées se traduit par
l’existence de contraintes de ressources. Parmi les contraintes de ressources on peut
distinguer les contraintes liées à leur utilisation et celles liées à leur fonctionnement.
Une ressource est dite non préemptible (telle qu’une imprimante) si elle ne peut
être retirée à une tâche Ti au profit d’une autre tâche sans qu’il y ait avortement de la
tâche Ti; une ressource est dite consommable (telle qu’un missile dans une application
militaire) si après son utilisation par une tâche, elle est consommée et donc n’existe
plus, etc.
Parmi les exemples des contraintes liées au fonctionnement des ressources, on peut
citer [Liu94]: la durée d’acquisition d’une ressource, la durée de restitution d’une
ressource et la durée de commutation de contexte. La durée d’acquisition de ressources
est la durée maximale qui peut être prise en compte par une tâche afin d’acquérir une
ressource oisive due aux propriétés de la ressource elle même. La durée de restitution
d’une ressource est la durée maximale séparant l’instant où une tâche libère la ressource
et l’instant où la ressource n’est plus dans le contexte de la tâche et donc disponible pour
d’autres tâches. La durée de commutation de contexte est la durée nécessaire pour
commuter une ressource d’une tâche à une autre, généralement suite à une interruption
de la première tâche par la seconde. Dans plusieurs cas, la durée de commutation de
contexte d’une tâche est égale à la somme de durée d’acquisition et de la durée de
restitution de ressource. Cependant, ceci n’est pas toujours le cas. En effet, dans le cas
par exemple d’un seul processeur, les informations de gestion de ce dernier telles que les
contenus de registres, nécessitant d’être sauvegardées et restaurées durant une
commutation de contexte et pas pendant l’acquisition ou la restitution.
Les contraintes d’accès de ressources associées à une tâche, indiquent, d’une part,
le type de ressources indispensables à son exécution, et d’autres part, le mode d’accès
(exclusif, partagé, etc.) qu’exige la tâche sur les ressources. Pour ce dernier cas,
l’expression de telles contraintes est nécessaire pour décrire les situations où la tâche
désire un accès en exclusion mutuelle sur une ressource à n points d’accès. En
environnement temps réel, la connaissance des contraintes de ressources par
l’algorithme d’ordonnancement est nécessaire pour qu’il puisse effectuer
l’ordonnancement des tâches qui les utilisent et réaliser leur gestion dans le cas où la
gestion de ressources est une fonction de l’ordonnanceur.
XI-8-Contraintes de placement:
Le besoin d’expression de contraintes de placement est spécifique aux systèmes
centralisés multiprocesseurs ou répartis. En effet, une tâche peut exiger que son
exécution se fasse sur un certain processeur (pour des raisons de compatibilité du code
exécutable par exemple) ou sur un site donné (parce qu’elle fait des entrées/sorties sur
un dispositif particulier, par exemple).
15
15](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-17-320.jpg)

![1 Le Monde Des Systèmes Temps Réel 171717
mouvement sans heurts avec des déviations minimales par rapport au chemin spécifié.
La validité de ce chemin incombe au planificateur de mouvement.
Les contraintes de temps du planificateur de mouvement sont quelque peu moins
sévères, et plus négociables que celles du contrôleur de mouvement. Dans ce type de
système, chaque niveau travaille sur un sous problème spécifié par un niveau supérieur.
Dans ce sens, le contrôle est centralisé au sommet de la hiérarchie.
XII-2 Architecture répartie:
Les fonctions de l’application peuvent être prises en compte par n’importe quelle
unité de traitement, grâce aux possibilités de communication du médium. Les capteurs
émettent sur le réseau les données (mesures ou événements) qui sont traitées dans un ou
plusieurs sites.
En environnements répartis, de nouveaux problèmes se posent et auxquels il faut
faire face: le placement des tâches, la mise à jour des copies multiples de données, la
synchronisation de tâches, etc.
Les inconvénients des systèmes répartis sont: difficulté de la gestion répartie des
ressources, incohérences des horloges locales, prise en compte des pannes, absence de
contexte global, etc. Par contre, c’est le schéma qui semble le plus souple par ses
capacités d’évolution, par ses possibilités de tolérance aux pannes et de répartition de la
charge ou capacités de réponses aux surcharges.
XIII- Conclusion
Les systèmes temps réel sont souvent distribués et possèdent différentes
contraintes de temps, de sécurité, de fiabilité, et de robustesse, imposées par
l’environnement de l’application. Comprendre et contrôler le comportement temporel
constituent un aspect critique pour assurer la sécurité et la fiabilité.
La vitesse (vitesses de processeurs par exemple) seule, n’est pas suffisante pour la
satisfaction des contraintes de temps. Des techniques rigoureuses de gestion de
ressources doivent aussi être utilisées, afin de prévenir des situations dans lesquelles des
tâches longues et à priorités réduites bloquent d’autres tâches à priorités plus élevées et
temps d’exécution réduits.
Le principal guide de gestion des ressources des systèmes temps réel est la
capacité de déterminer si le système peut satisfaire toutes ses contraintes de temps. Ce
besoin de prévisibilité nécessitent le développement et l’utilisation de modèles
d’ordonnancement et des techniques analytiques. Leurs applications nécessitent
l’intégration de certaines qualités de services, particulièrement en matière de
prévisibilité des temps d’exécution des tâches, de tolérance aux fautes, de disponibilité
et de performances. Ils doivent présenter des interfaces utilisateurs conviviales. La
prévisibilité dans le contexte temps réel «hard» requiert une importance capitale. Ces
systèmes peuvent comprendre des ressources hétérogènes telles que les CPUs, les
réseaux, et les périphériques d’entrée/sortie qui doivent être ordonnancées de façon à
être prévisibles, flexibles, et faciles à analyser mathématiquement.
La prévisibilité nécessite le développement de modèles d’ordonnancement et de
techniques analytiques afin de déterminer si le système temps réel peut ou non satisfaire
les contraintes de temps.
Les difficultés de spécifications, analyse, et ordonnancements de processus dans
les systèmes temps réel à contraintes de temps strictes (hard) sont augmentées par le fait
que le système physique contrôlé consiste souvent en plusieurs sous-systèmes
indépendants produisant des signaux asynchrones de capteurs et valeurs de contrôle
[Kramer93]. De tels systèmes peuvent avoir besoin de logiciels de contrôle distribué
17
17](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-19-320.jpg)

![2 Ordonnancement Des Tâches
I- Types de tâches temps réel:
Nous utilisons une classification de ces tâches en fonction des propriétés de la liste de leurs
dates d'occurrences. Trois types de tâches ont été identifiées :
périodiques : Une tâche périodique est définie comme une tâche qui doit être prête à être
exécutée à des intervalles de temps fixés (ou périodes) et dont l'exécution doit être terminée
avant le début de la période suivante [Bestravos93]. Une autre définition dit qu'une tâche
périodique demande une allocation du temps processeur à des intervalles réguliers, ces temps
processeur devant être alloués de façon à ce que l'exécution de la tâche ne dépasse pas ses dates
limites [Howell94] [Gupta94].
apériodiques: [Burns90] L'activation d'une tâche apériodique est essentiellement due à un
événement aléatoire et est déclenchée généralement par une action externe au système. Sa date
limite est fixée par l'environnement extérieur. Les tâches apériodiques ont également des
contraintes de temps qui leurs sont associées, par exemple le démarrage de leur exécution à
l'intérieur d'une période de temps prédéfinie. Souvent les tâches apériodiques sont déclenchées
par les événements critiques de l'environnement externe du système, c'est pour cela que leurs
dates limites sont souvent contraintes.
sporadiques: Une tâche sporadique est comme pour une tâche apériodique souvent déclenchée
par un événement extérieur au système, mais on constate l'existence d'une durée minimum entre
deux événements apériodiques (issus de la même source). La tâche sera alors dite sporadique
[Howell94] [Burns90].
II- Ordonnancement des applications temps réel:
Dans les systèmes temps réel, un problème d’ordonnancement consiste, à partir d’une
architecture matérielle (une ou plusieurs machines mono ou multiprocesseurs, un ou
plusieurs réseaux,…), d’une architecture fonctionnelle, et d’un ensemble d’objectifs
souhaités, à trouver un planning d’exécution des tâches de façon à garantir le respect des
contraintes de temps.
L’ordonnancement joue un rôle important puisque c’est lui qui définit le planning
d’exécution de tâches de façon à ce que les contraintes de tâches soient vérifiées. Dans la
plupart de ces systèmes, le respect de ces contraintes de temps reste le principal critère à
satisfaire.
19](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-21-320.jpg)
![2 Ordonnancement Des Tâches
Un problème d’ordonnancement dans un système temps réel est défini par le modèle
du système, les tâches et leurs natures, ainsi que les objectifs que l’algorithme
d’ordonnancement doit réaliser.
Le modèle de système décrit l’architecture matérielle du système disponible
(machine(s), réseau(x), etc.), qu’on appellera services, et les contraintes associées.
Les tâches et leurs natures sont décrites au niveau de la spécification fonctionnelle de
l’application et des contraintes associées. Comme exemple de ces contraintes, on peut citer
[Cardeira94]: les contraintes de temps, les contraintes de ressources, de précédence, etc.
Le challenge de l’ordonnancement est de garantir que toutes les contraintes du
problème sont satisfaites, particulièrement les contraintes de temps. L’ordonnanceur
produit un planning d’exécution de tâches, qui assure le respect des contraintes. Un
ordonnancement (planning) valide est un ordonnancement qui vérifie, sur une durée infinie,
que toutes les contraintes sont satisfaites.
L’intervention du temps fait des systèmes réactifs des systèmes temps réel. Le temps
est alors un facteur déterminant puisqu’il intervient aussi bien dans la définition des
critères de performances (par exemple, appliquer en une millisecondes une commande
externe à chaque fois qu’un capteur détecte une mesure excédant une certaine valeur) que
dans le séquencement interne d’un logiciel (par exemple, lancer une tâche de surveillance
séquentiellement toutes les 100 millisecondes).
Les méthodes du génie logiciel concernant les systèmes informatiques usuels font
appel à des modèles fonctionnels. En effet, la dynamique de ces systèmes étant pauvre, une
décomposition fonctionnelle structurée et l’identification des informations circulant entre
fonctions sont suffisantes pour spécifier la plupart des problèmes [Vallotton91].
Les approches fonctionnelles ne sont pas satisfaisantes pour traiter la spécification
des systèmes réactifs, car les aspects émergeant de ces derniers sont essentiellement
dynamiques. Un système réactif n’évolue pas seulement en fonction de ces entrées, mais
aussi des états internes. Un exemple trivial l’illustre: un logiciel qui doit exécuter une
routine d’interruption sauf si elle survient alors qu’il est déjà en cours de traitement. Une
composante de son état est «être en cours de traitement de l’interruption», sa connaissance
est nécessaire pour prévoir le comportement du système.
Dès que l’on a affaire à un système temps réel d’une certaine complexité, le point de
vue du comportement réactif devient primordial. Il doit donc intervenir dans sa
20](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-22-320.jpg)
![2 Ordonnancement Des Tâches
modélisation. Les méthodes spécifiques du temps réel introduisent généralement le
contrôle, mais davantage pour assurer la cohérence des modèles fonctionnels que pour
introduire de réels moyens de modéliser le comportement.
Dans la pratique, les portions temps critique des systèmes temps réel durs continuent
d’être implémentées par des langages de programmation de bas niveau. Elles sont
manuellement réglées afin de satisfaire toutes les contraintes. Les développeurs rencontrent
de grandes difficultés dans l’élaboration et l’analyse de codes complexes et ce, en
l’absence d’un langage, supportant des outils appropriés de spécification des contraintes de
temps [Chung95, Gerber97].
La spécification des contraintes de temps de granularité très fine dans le contexte
d’un langage de programmation de haut niveau n’est pas encore possible. On établit
manuellement des portions de code en langage assembleur pour exprimer des contraintes
strictes de temps. Ce qui rend ces programmes très difficiles à écrire et à maintenir, et un
ordonnancement automatisé devient presque impossible. Les langages tels que Ada
[Taft92] ne permettent de spécifier les contraintes de temps qu’entre les tâches,
lexicographiquement adjacentes dans le code source, et ne permettent pas de les spécifier
entre les instructions. Cette adjacence est aussi artificielle qu’insuffisamment expressive.
III- Etude formelle
Dans les STR, garantir que les tâches s’exécutent en respectant leurs échéances prescrites
est un point critique pour assurer l’intégrité de ces systèmes (systèmes en robotique) et la réussite
de ses missions.
Capteur1 Actionneur1
Capteur2 Actionneur2
Flux d’Information
Echantillonnage
Intervention
Système
Réaction
Capteurs
de Actionneur k
et
Contrôle
Temps Actionneur m
Réel
Capteur n Actionneur n
Fig I-4:Modélisation du fonctionnement d’un système temps réel
21](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-23-320.jpg)

![2 Ordonnancement Des Tâches
comportement temporel dans le contexte des tâches composées d’une série de sous-tâches qui
s’exécutent avec des priorités multiples (dynamique).
La notion d'ordonnanceur de tâches prend toute sa signification lorsqu'on souhaite faire
exécuter les tâches par une architecture matérielle. Il faut être capable en cours d'exécution du
système, d'allouer du temps CPU d'une ressource de l'architecture matérielle à toute tâche qui
ferait son apparition, et ce avant sa date limite d'exécution. Un algorithme qui alloue les temps
processeurs pour chaque tâche dans un système de tâches est un algorithme d'ordonnancement
[Burns90] [Howell94]. Ces algorithmes peuvent avoir diverses propriétés. On peut les qualifier :
• d'algorithme optimal : [Krithi94] [Di Natal] [Atanas94] [Howell94] Un
algorithme d'ordonnancement est optimal s'il peut correctement ordonnancer un système
de tâches chaque fois que ce système est ordonnançable ;
• d'algorithme NP-complet : [Di Natal] NP est la classe de tous les problèmes de
décision pouvant être résolus dans un temps polynomial par une machine non-
déterministe. Si un problème R appartient à la classe NP et que tous les problèmes de la
classe NP sont polynomialement transformables en R alors le problème R est reconnu
NP-complet. L'algorithme gérant ces problèmes décisions est alors NP-complet ;
• d'algorithme NP-hard : [Di Natal] NP est la classe de tous les problèmes de
décision pouvant être résolus dans un temps polynomial par une machine non-
déterministe. Si tous les problèmes de la classe NP sont polynomialement transformables
en un problème R mais qu'on ne peut pas prouver que ce problème R appartient lui-même
à la classe NP, alors le problème R est dit NP-hard. L'algorithme gérant ce problème de
décision est dit NP-hard.
III- Ordonnancement "à base de priorités":
Nous allons regarder le cas particulier de deux algorithmes (ces deux algorithmes sont très
étudiés au niveau de la recherche sur l'ordonnancement temps réel) : le Rate Monotonic et le
Earliest Deadline.
III-1- L'algorithme Rate Monotonic:
La notion d'ordonnancement Rate Monotonic a été introduite en premier par Liu et
Layland [Liu73] en 1973. L'ordonnancement Rate Monotonic est un ordonnancement statique et
ne s'applique que pour des tâches périodiques. Il s'agit d'un algorithme d'ordonnancement à
priorités fixes. L'avantage d'une allocation fixe des priorités est que les priorités, allouées une
23](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-25-320.jpg)
![2 Ordonnancement Des Tâches
fois pour toutes, ne sont pas réévaluées au cours du temps. Le terme Rate Monotonic dérive de la
façon dont sont allouées les priorités aux différentes tâches, elles sont allouées selon une
fonction "Monotonic" du "Rate" (de la période) de la tâche. Plus la tâche a une période courte,
plus la priorité allouée sera importante. De nombreux travaux ont étendu l'application du Rate
Monotonic aux tâches synchronisées, à données partagées, aux systèmes avec des tâches
apériodiques...
III-2- L'algorithme Earliest Deadline:
Tout comme pour le Rate Monotonic, la notion d'algorithme Earliest Deadline a été
introduite en premier par Liu et Layland [Liu73] en 1973. l'ordonnancement Earliest Deadline est
un ordonnancement dynamique. Il peut s'appliquer pour l'ordonnancement de tâches périodiques
ainsi qu'apériodiques car il s'agit d'un algorithme d'ordonnancement à priorités dynamiques. Le
terme Earliest Deadline vient de la façon dont les priorités sont allouées aux tâches. La tâche
dont la date limite qui arrive le plus tôt aura une priorité élevée. Les priorités sont constamment
réévaluées au cours du temps (par exemple dans le cas où une nouvelle tâche arrive et que sa
date limite est la plus proche).
II-3- Critère d'ordonnançabilité pour chacun de ces algorithmes:
Dans le cas de systèmes où seules des tâches périodiques doivent être ordonnancées, des
travaux ont été réalisés pour déterminer, connaissant l'ensemble des tâches, à partir de quel
pourcentage d'utilisation CPU les dates limites de ces tâches seront sûres d'être respectées
[Liu73].
Le taux d'utilisation CPU pour une tâche i est le rapport entre le temps d'exécution de cette
tâche et sa période . Le taux d'utilisation CPU pour un groupe de tâches est la somme de ces
rapports.
Pour l'algorithme d'ordonnancement Rate Monotonic le pourcentage d'utilisation CPU doit
respecter la relation suivante si on veut être sûr que toutes les dates limites des différentes tâches
soient garanties :
(1) Lorsque n devient important, on remarque que pour être sûre de respecter les dates
limites des différentes tâches en utilisant l'algorithme Rate Monotonic pour ordonnancer les
tâches, le processeur doit être utilisé à moins de 69 %. Dans le cas particulier où les périodes des
24](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-26-320.jpg)
![2 Ordonnancement Des Tâches
différentes tâches sont harmoniques, une étude a montré que quelque soit le taux d'utilisation
CPU si l'ordonnancement est réalisable alors il pourra être réalisé.
Pour l'algorithme d'ordonnancement Earliest Deadline le pourcentage d'utilisation CPU
doit respecter la relation suivante si on veut être sûr que toutes les dates limites des différentes
tâches soient garanties :
(2) Même lorsque n devient important, on remarque que quelque soit le taux d'utilisation
CPU, si l'ordonnancement est réalisable, il pourra être réalisé.
III-4- Les limites des deux algorithmes:
Ces algorithmes ne posent pas de problèmes d'application tant que l'on reste dans une
utilisation avec des tâches périodiques (dans le cas du Rate Monotonic seulement, le Earliest
Deadline pouvant prendre en compte les tâches apériodiques), pas de protocoles (partage de
données entre tâches, ...), pas de surcharges.
Des études ont permis l'amélioration de ces algorithmes pour prendre en compte les
différents cas cités ci-dessus.
IV- Modes d'ordonnancement:
L'ordonnancement est une fonction centrale dans un système temps réel. En fonction de
l'apparition des entrées en provenance du système contrôlé (entraînant la demande d'exécution
d'une tâche), il doit réorganiser l'affectation des ressources processeur en vue du respect des
dates limites de chaque tâche.
L'ordonnancement peut se faire de deux façons. La première façon d'ordonnancer est
l'ordonnancement «offline» pour lequel l'ordonnancement est planifié dès la conception, des
tables d'ordonnancement sont créées et vont être utilisées en fonctionnement. Durant le
fonctionnement, le système se contente de lancer les tâches aux dates prévues. La deuxième
façon est l'ordonnancement online pour lequel l'ordonnancement est réalisé à chaque instant du
fonctionnement du système. Si les ordonnancements réalisés offline donnent des systèmes très
rapides à l'exécution, et d'une grande fiabilité, ils ne peuvent s'appliquer qu'aux systèmes dont on
connaît entièrement a priori le système contrôlé. Dans le cas contraire, un ordonnancement
online est nécessaire pour replannifier les tâches à l'apparition d'un nouvel événement significatif
[Atanas94] [Howell94].
Les algorithmes d'ordonnancement peuvent également être dits statiques ou dynamiques.
Un algorithme d'ordonnancement est dit statique lorsque l'ordonnancement est prévisible avant la
25](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-27-320.jpg)
![2 Ordonnancement Des Tâches
mise en fonctionnement du système, il faut pour cela connaître les tâches a priori. Un algorithme
d'ordonnancement est dit dynamique lorsque l'ordonnancement est créé au fur et a mesure de
l'arrivée des tâches dont on peut ne rien connaître a priori. Un ordonnancement statique est plus
fiable mais moins flexible qu'un ordonnancement dynamique (pour un ordonnancement statique
il faut connaître l'ensemble des tâches à réaliser, alors que pour un ordonnancement dynamique
ce n'est pas la peine de toutes les connaître) [Atanas94].
A partir de ces différentes propriétés qui sont associées aux algorithmes d'ordonnancement,
une classification de ces algorithmes ressort :
• les ordonnanceurs que l'on peut qualifier de "tout planifiés". Ces ordonnanceurs sont
des ordonnanceurs offline et statiques. En effet, un ordonnancement est créé à partir d'une
table d'ordonnancement qui est construite à l'aide des caractéristiques des différentes tâches.
Cet ordonnancement est ensuite appliqué sur le système. Cette approche ne peut s'appliquer
que pour l'ordonnancement de tâches périodiques (ou qui ont été transformées en tâches
périodiques) puisqu'il faut connaître à priori l'ensemble des tâches et de leurs caractéristiques.
Cette approche est hautement prédictible mais n'est pas flexible : un changement sur une des
tâches ou une de ses caractéristiques entraîne la reconstruction totale de la table [Krithi94] ;
• les ordonnanceurs que l'on peut qualifier d'ordonnanceurs "à base de priorités". Ces
ordonnanceurs sont online mais peuvent être statiques ou dynamiques. Des priorités sont
affectées aux tâches, l'ordonnanceur va ordonnancer les tâches suivant la valeur de la priorité
qui leur est affectée. Pour ce type d'ordonnancement apparaît la notion de préemptivité (si une
tâche de basse priorité est en train d'être exécutée et qu'une tâche de priorité plus haute est
déclenchée, la tâche de basse priorité sera interrompue et le processeur sera affecté à la
nouvelle arrivée) [Krithi94]. Un algorithme d'ordonnancement peut être à priorités fixes
(statiques) ou dynamiques [Atanas94]. Dans le cas d'un ordonnancement à priorités fixes, on
va associer à chaque tâche une priorité, cette priorité va rester la même tout au long du
fonctionnement du système. Dans le cas d'un ordonnancement à priorités dynamiques la
valeur de la priorité d'une tâche va évoluer au cours du fonctionnement du système ;
• les ordonnanceurs que l'on peut qualifier de "dynamiques". Ces ordonnanceurs sont
online et dynamiques. Il apparaît deux approches "dynamiques", les approches "Dynamic
Planning-Based" et les approches "Dynamic Best-Effort". Les approches "Dynamic Planning-
Based" lorsqu'une tâche apparaît vont, avant de l'exécuter, créer un plan d'exécution de cette
tâche et vérifier si ce plan va garantir son exécution. Si l'exécution de cette tâche n'est pas
26](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-28-320.jpg)
![2 Ordonnancement Des Tâches
garantie alors d'autres alternatives seront envisagées (tel l'envoi de la nouvelle arrivée sur un
autre nœud du système pour un système distribué) [Krithi94]. Pour les approches "Dynamic
Best-Effort", les tâches vont être ordonnancées mais en aucun cas, leurs dates limites ne
seront garanties [Krithi94].
Pour le génie automatique, les ordonnanceurs du type "tout planifiés" ne peuvent pas
répondre aux problèmes posés par l'apparition à caractère aléatoire des événements issus du
système contrôlé. En effet il est impossible de planifier, avant la mise en route du système,
l'affectation des tâches sur le ou les processeurs du système contrôlant car on ne connaît pas les
dates de demande d'exécution. Les ordonnanceurs du type "dynamiques" ne peuvent pas
s'appliquer dans le domaine de l'automatique car les systèmes que nous étudions sont des
systèmes contraints et que dans le cas de ces ordonnanceurs on ne sait pas a priori si toutes les
dates limites pourront être garanties. Par contre les ordonnanceurs du type "à base de priorités"
sont très prisés par les acteurs du Génie Automatique. Nous allons donc dans la suite de notre
étude détailler ce type d'ordonnanceurs.
V- Création d'ordonnancements plus complexes:
Les algorithmes Rate Monotonic et Earliest Deadline sont complétés par d'autres
algorithmes ou protocoles dans le but de pouvoir répondre à des spécifications du système plus
compliquées (la prise en compte de tâches apériodiques, des protocoles tels le partage des
données ..., le traitement des surcharges transitoires).
V-1- Introduction des problèmes "d'inversion de priorités" (dus aux partages de données
par exemple):
Comme nous l'avons déjà vu, un algorithme d'ordonnancement est préemptif lorsqu'au
cours de l'ordonnancement il peut interrompre l'exécution d'une tâche et allouer le temps
processeur à une autre tâche. Par exemple lorsqu'une tâche de plus haute priorité arrive, le Rate
Monotonic ou le Earliest Deadline vont interrompre l'exécution de la tâche qui est en cours pour
exécuter la nouvelle arrivée. Une tâche peut être préemptée plusieurs fois sans aucune pénalité.
Les algorithmes non préemptifs ne peuvent pas interrompre l'exécution d'une tâche de cette façon
[Burns90] [Atanas94] [Sha93].
Dans les systèmes temps réel, les tâches interagissent pour satisfaire des spécifications plus
larges du système. Les formes que prennent ces interactions sont variées, allant de la simple
27](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-29-320.jpg)
![2 Ordonnancement Des Tâches
synchronisation jusqu'à la protection par exclusion mutuelle sur les ressources non partageables,
et les relations d'antériorité. Pour cela, il existe des événements, des langages de programmation
concurrente fournissant des primitives de synchronisation (drapeaux, contrôleurs...). La difficulté
principale avec ces drapeaux, contrôleurs ou autres messages de base des systèmes, est que des
tâches à haute priorité peuvent être bloquées par des tâches à priorité plus basse. Ce phénomène
est connu sous le nom d'inversion de priorité. Quatre approches permettent de résoudre ce
problème :
• une approche appelée "prévention d'inversion de priorité"[Howell94],
• une approche appelée "héritage des priorités" [Klein90] dont le "Ceiling
Protocol" est un algorithme particulier [Klein90] [Di Natal]. Le travail de ce protocole lié
avec un ordonnanceur Rate Monotonic a été étudié par Sha et al. [Rajkumar90], et le
même protocole lié avec un ordonnanceur Earliest Deadline a été étudié par Chen et Lin
[Chen90],
• une approche appelée "Stark Ressource" [Di Natal].
L’adjonction de tels protocoles ne nous permet plus d'avoir une estimation de
l'ordonnançabilité des différentes tâches à ordonnancer.
V-2- Traitement des tâches apériodiques ou sporadiques : les algorithmes "bandwith
preserving":
Beaucoup de systèmes temps réel doivent traiter des tâches périodiques ainsi que des
tâches apériodiques. Quand on veut prendre en compte des événements apériodiques, il faut
utiliser une approche dynamique, telle le Earliest Deadline. Mais malgré cela, l'exécution en cas
de surcharges transitoires pose des problèmes (Les dates limites qui ne sont pas respectées ne
sont pas forcément celles dont l'importance pour le système est la moindre), ce cas est traité dans
le paragraphe suivant.
Le Rate Monotonic a été adapté pour pouvoir gérer des tâches apériodiques. Pour cela, une
tâche périodique aura la fonction de servir une ou plusieurs tâches apériodiques. Différents
algorithmes permettent de gérer cela :
• le "Priority Exchange"[Sha87],
• le "Deferrable Server" [Sha87],
• le "Sporadic server" [Harbour91] [Sha87],
• le "Slack Stealing" [Davis93].
28](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-30-320.jpg)
![2 Ordonnancement Des Tâches
V-3- Traitements en cas de surcharges transitoires:
(dus au fait que certaines tâches sont apériodiques).
Le fait de devoir gérer des tâches apériodiques peut entraîner un phénomène de surcharges
transitoires. Il peut se présenter des situations pour lesquelles il n'est pas possible de respecter les
dates limites, le système est alors dit en exécution de surcharge transitoire.
Malheureusement, une application directe du Rate Monotonic n'est pas appropriée dans le
cas de telles surcharges. Par exemple dans l'approche Rate Monotonic, une surcharge transitoire
va amener la tâche dont la période est la plus longue à dépasser sa date limite. Cette tâche peut
cependant être plus critique que les autres. La difficulté vient du fait que le concept de priorité
pour le Rate Monotonic est une indication de la période qui peut ne pas être une indication de
l'importance de la tâche vis à vis du système. Ce problème peut être résolu en transformant la
période dans le cas d'une tâche importante [Burns90].
Le Earliest Deadline est un algorithme optimal lorsqu'il n'y a pas de surcharge. Le
phénomène typique qui se produit en cas de surcharge avec le Earliest Deadline est l'effet
domino [Di Natal]. Pour contrôler les retards des tâches sous des conditions de surcharges, on
associe à chaque tâche une valeur reflétant l'importance de chaque tâche dans le système. Alors
la gestion des tâches à partir de ces valeurs peut être réalisée par l'algorithme de Smith" [Di
Natal]. Malheureusement, les contraintes d'antériorité sur les tâches sont souvent générales. Une
heuristique a été proposée dans le projet SPRING, où les dates limites et les algorithmes de coût
ont été combinés avec d'autres algorithmes pour revoir dynamiquement ces valeurs et accorder
les dates limites avec les contraintes d'antériorité. Certains algorithmes heuristiques, proposés
pour gérer les surcharges, améliorent l'exécution du Earliest Deadline [Livny91]
[Thambidurai89].
29](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-31-320.jpg)


![4 JAVA Langage De L’Avenir
totalement orienté objet, comparé au C++ dans lequel il est facile de retomber dans la
programmation structurée.
Note
En Java, comme dans tous les langages, il y a plusieurs façon de faire qui donne le
même résultat. Nous entendons par “façon de faire” que le code source est différent mais que
l’exécution du programme est identique. Ce phénomène est d’autant plus vrai pour ce qui est
de la programmation d’interfaces graphiques utilisateurs (GUI). En effet, on peut avoir deux
exécutions identiques mais avec des codes sources totalement différents. De plus, certains
fabricants de logiciels servant à écrire du code source en Java (comme Borland JBuilder et
Microsoft Visual J++) ont créés plusieurs nouvelles classes pouvant faciliter ou accélérer la
rédaction du code source.
III- Programme simple:
En Java, il est possible de faire deux types de programme: des applets et des
applications. Les applets sont destinées exclusivement aux pages web sur Internet tandis que
les applications sont semblables à des programmes développés en C, à savoir toutes les
applications autonomes, qu’elles soient développées avec une interface graphique ou non.
Le langage Java étant un langage orienté objet, tout le code doit se retrouver à l’intérieur
de classes. Nous pouvons en avoir plusieurs, mais il se peut que vous en aillez qu’une seule.
Le nom de la classe doit absolument être identique au nom du fichier *.java contenant le code
source. Par exemple, le fichier App1.java doit obligatoirement contenir la classe App1. Cette
classe est appelée la classe principale du programme.
La classe principale doit avoir, dans le cas d’une application et non d’une applet, la
méthode “main”. Cette méthode est appelée automatiquement lors du démarrage de
l’application. Lorsque la méthode “main” est terminée, l’application est aussi terminée.
La seule différence est le mot “args” qui est une variable, donc qui peut s’écrire
presque n’importe comment. Analysons chacun des mots qui composent la méthode
principale :
public : Signifie que la méthode est accessible à l’extérieur de la classe dans laquelle elle
se trouve. Cela permet à l’interpréteur d’appeler la méthode “main”.
static: Indique que la méthode “main” s’applique à toute la classe.
void: Signifie que la méthode ne retourne rien.
main: Nom de la méthode. Doit demeurer inchangé.
String args[]: Tableau contenant des chaînes de caractères. Ce sont les commandes
passées à l’application.
32](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-34-320.jpg)








![5 Modélisation Des Dépendances
Deux instructions écrivant dans la même location (cellule) de stockage provoquent une
dépendance de sortie. Autrement dit, une dépendance de sortie implique que deux instructions
assignent des valeurs à une même variable, et entre ces deux instructions, il n’y a aucune
utilisation de cette variable. Dans ce cas, la suppression de la première instruction n’altère pas
le résultat final.
Soit le fragment de programme suivant :
S1: X = Y + Z
S2: C = X * 22
S3: X = A – B
L’instruction S1 doit s’exécuter avant S3 vu que l’instruction intervenante S2 utilise le
résultat produit par S1, donc il y a une dépendance de flux de S1 à S2.
Dans cet exemple, une anti-dépendance se produit entre S2 et S3 vu que S2 lit la valeur
de X qui sera écrasée par S3. Par conséquent, S2 doit s’exécuter avant S3. Autrement, S3
assigne une valeur à une variable qui a été utilisée par S2.
Les dépendances de flux sont les dépendances les plus fréquentes, dans lesquelles un
résultat produit par une instruction, est utilisé par une autre.
Les anti-dépendances et les dépendances de sortie se produisent quand le programmeur
ou le compilateur réutilisent les cellules de stockage afin de réduire les besoins en mémoire du
programme.
On peut noter que la renominalisation de variables peut être utilisée pour éliminer ces
deux types de dépendances. Par exemple, au lieu de réutiliser un seul tableau pour deux
calculs indépendants dans de différents endroits du programme, le programmeur aurait pu
allouer deux tableaux différents (séparés). Le tableau qu’on a rajouté va éliminer la
dépendance de sortie et les anti-dépendances pour le premier tableau. Cela permet
d’augmenter le degrés du parallélisme, mais ça vient à l’encontre du surcoût en espace
mémoire pour le tableau additionnel.
En examinant les instructions de boucles (While, Repeat, …), chacune de ses
instructions peut être exécutées plusieurs fois, ce qui peut engendrer des relations de
dépendances entre les différentes itérations et c’est ce qu’on appelle les dépendances
d’itération. Soit le fragment de programme suivant :
S1: Do I = 2,n
S2: a[I] = a[I] + c
S3: b[I] = a[I - 1] * b[I]
EndDo
Dans cet exemple, il n’y a pas de dépendance entre les instructions S2 et S3 au sein de
chaque itération, mais il y a une dépendance d’itération entre les instructions S3 et S2 qui
appartiennent respectivement à deux itérations successives.
En effet, quand I = k, l’instruction S3 utilise la valeur de a[k-1] assignée par S2 durant
l’itération k – 1. De ce fait, on dit qu’il y a une dépendance d’itération si une variable est
modifiée par une itération et utilisée par une autre.
Intuitivement, une dépendance de contrôle d’une instruction Si à une instruction Sj
existe quand l’instruction Sj doit être exécutée seulement si l’instruction Si génère une
certaine valeur. Ce type de dépendance se produit, par exemple, quand Si est une instruction
conditionnelle et Sj ne sera exécutée que si la condition est satisfaite.
Les dépendances de contrôle peuvent limiter le parallélisme en s’attardant dans une
boucle. Ferrant & al définissent formellement les dépendances de contrôle telles que: «les
dépendances de contrôle sont un concept clé dans l’optimisation des programmes et le
parallélisme. Une instruction w reçoit une dépendance de contrôle d’une instruction u si u est
une condition qui affecte l’exécution de w».
44
44](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-46-320.jpg)
![5 Modélisation Des Dépendances
Programme
Extraction des dépendances
Dépendances multiprocédurales Dépendances de ressources
Dépendances d’appel Dépendances de contrôle
Dépendances résumées
Dépendances de données
Dépendances de sortie Dépendances d’itération
Dépendances de flux Anti – dépendances
Caractéristiques générales.
Caractéristiques des programmes multiprocéduraux.
Fig. III-1: Schématisation des types de dépendances existantes au sein d’un programme
Les tests symboliques de la dépendance de données peuvent déterminer s’il existe des
dépendances ou non entre des instructions d’un programme qui accèdent à un tableau
(variables indicées) avec des indices complexes. Par exemple, considérons la boucle suivante:
Do I = L,H
M[a * I + b] = X[I] + Y[I]
Z[I] = 2 * M[c * I + d]
EndDo
Les itérations de cette boucle peuvent être exécutées en parallèle en utilisant une
stratégie d’ordonnancement, s’il n’y a pas des dépendances d’itération croisées dû aux
références dans le tableau M[]. Pour déterminer si une telle dépendance existe, l’analyseur
symbolique de la dépendance de données doit résoudre l’équation de «Diophantine»
aI1+b=cI2+d. Cette équation est sous la contrainte que: L <= I1 <= I2 <= H, où I1 et I2 sont
deux valeurs spécifiques de l’indice de la boucle, L et H sont les bornes inférieure et
45
45](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-47-320.jpg)
![5 Modélisation Des Dépendances
supérieure sur l’indice de la boucle et a, b, c, et d sont des entiers. S’il n’existe aucune
solution alors il n’y a pas de dépendance entre les deux instructions dans cette boucle.
Des techniques pour résoudre ces équations ont été étendues pour analyser autres
indices et qui sont plus complexes.
Dans le cas où le programme contient des appels de procédures (programme
multiprocédural), on peut trouver deux autres formes de dépendances: dépendances d’appel et
dépendances résumées. La première modélise l’instruction d’appel et le passage de
paramètres. La seconde représente l’influence d’exécution des paramètres effectifs d’entée sur
les paramètres effectifs de sortie, en faisant abstraction de la procédure.
VI- Représentation des dépendances:
Définition:
Un programme est dit monolitique s’il ne contient pas de procédures, sinon il est dit
multiprocédural.Pour un programme monolitique, les dépendances sont représentées par un
graphe orienté appelé Graphe de Dépendance de Programme (GDP). Les nœuds de ce graphe
sont les éléments de base du programme qui sont en général les instructions. Ces nœuds sont
liés par des arcs représentant les dépendances extraites de ce programme. Un élément de base
peut être une instruction d’affectation, d’écriture, d’alternance ou d’itération. A chacun de ces
éléments, on fait correspondre un nœud particulier. La racine du GDP est un nœud particulier
appelé Entrée (ou Entry en anglais ) représentant l’entête du programme. Les arcs
représentent les dépendances de données et de contrôle. L’extrémité initiale d’un arc de
dépendance de contrôle est obligatoirement le nœud Entrée ou un nœud de contrôle. Les arcs
issus du nœud Entrée sont toujours libellés à vrai, sachant que chaque arc est libellé soit par
vrai ou faux. Pour un programme multiprocédural, les dépendances sont représentées par un
Graphe de Dépendances de Système (GDS). Il est composé d’un ensemble de GDP reliés
entre eux par des arcs. Chacun des GDP d’un GDS représente les dépendances entre les
instructions d’une procédure donnée. Les arcs de connexion modélisent les dépendances
d’appel et les dépendances résumées.
Une dépendance d’appel est représentée soit par un arc reliant un nœud d’appel à un
nœud d’entrée (le nom de la procédure), soit par des arcs reliant des nœuds effectifs à des
nœuds formels. Il y a un nœud effectif d’entée (de sortie) pour chaque paramètre formel
d’entrée (de sortie). Les variables globales sont, en général, traitées comme étant des
paramètres effectifs supplémentaires. Les dépendances résumées sont représentées par des
arcs reliant les nœuds effectifs d’entrée à ceux de sortie.
Dans une approche proposée par Jackson et Rollins[Jackson 94], on représente, au sein
de chaque GDP, les actions sur les variables par un nœud et les dépendances entre variables
par les arcs. Les instructions d’appel sont modélisées par des arcs résumées.
Notez qu’un arc de dépendance de données d’un nœud v à un nœud u signifie que le
comportement du système peut changer si l’ordre relatif des composants représentés par v et u
est inversé. Cependant, un arc de dépendance de contrôle d’un nœud v à un nœud u signifie
que durant l’exécution, en cas où le prédicat représenté par v est évalué et sa valeur relie le
libellé de l’arc à u, donc la composante du programme représentée par u sera éventuellement
exécutée et fournira au système une terminaison normale.
Une autre vision de nos arcs de dépendances de données partage ces derniers en deux
types : les arcs de dépendances de flux et les arcs de dépendances def-ordre.
Un arc de dépendance de flux relie un nœud v, qui représente une affectation d’une
variable x, au nœud u représentant l’ensemble des utilisations possibles de cette
affectation.
Un arc def-ordre relie deux nœuds v et u qui représentent des affectations de la variable
x et où ces deux affectations atteignent une utilisation commune et v précède lexicalement u.
46
46](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-48-320.jpg)

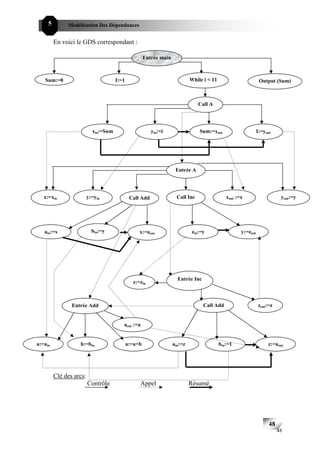




![6 Les Dépendances Orientées Objets
Représentation des programmes orientés objets (les dépendances orientées objets):
I-Introduction:
Les caractéristiques orientées objets, telles que les classes et les objets, l’héritage, le
polymorphisme, la liaison dynamique et les portées, interviennent dans le développement
d’une représentation efficace d’un programme orienté objet.
Une classe définit les attributs qu’une de ses instances va posséder. Les attributs d’une
classe se composent de:
1. Instance de variables qui implémentent l’état de l’objet.
2. Méthodes qui implémentent les opérations sur l’état de l’objet.
On a souvent conçu, implémenté et testé les classes sans connaître les environnements
d’appel. Par conséquent, une représentation graphique efficace, pour les logiciels orientés
objets, doit se composer d’une représentation des classes qui peuvent être réutilisées dans la
construction de d’autres classes et applications utilisant ces dernières.
Les classes dérivées sont définies à travers l’héritage, qui permet à la classe dérivée
d’hériter des attributs à partir de leurs classes parentes, et étendre, restreindre, redéfinir ou de
les remplacer en quelque sorte.
Le fait que l’héritage facilite la réutilisation de code, une représentation graphique
efficace d’une classe dérivée doit permettre la réutilisation des informations d’analyse. La
construction de la représentation d’une classe dérivée doit réutiliser les informations d’analyse
calculées pour les classe de base, et ne détermine que les informations qui sont définies dans
la classe dérivée.
Le polymorphisme est une caractéristique importante des langages orientés objets, qui
permet à l’exécution (runtime) de choisir l’un des appels aux méthodes faisant partie de
l’ensemble des destinations possibles.
Une représentation statique d’un choix dynamique exige que toutes les destinations
possibles soient incluses, à moins que le type peut être déterminé statiquement.
Une représentation doit prendre en considération les dépendances des instances de
variables entre les appels aux méthodes de l’objet par un programme d’appel, même si ces
instances ne sont pas visibles à ce programme.
II- Applications orientées objets et leurs modèles de représentations:
Afin de pouvoir modéliser les caractéristiques orientées objets, on doit développer des
GDS pour les applications orientées objets, sur lesquels un algorithme de troncature inter-
procédurale [14,23] peut être appliqué. On construit ces GDS pour des classes uniques,
groupes de classes interactives et des programmes orientés objets complets.
Pour chaque classe C dans le système, on construit un GDC (Graphe de Dépendances
de la Classe), qu’on réutilise dans la construction des classes qui dérivent de C et celles qui
l’instancient.
Pour un Système Incomplet (SI) se composant d’une seule classe ou un nombre de
classes interactives, on construit un Graphe de Dépendance de Procédure (GDP), qui simule
tous les appels possibles aux méthodes publiques dans la classe.
Pour un Système orienté objet Complet (SC), on construit un GDP à partir du
programme principal dans le système.
L’approche adoptée dans la représentation s’intéresse à l’efficacité dans la construction
et le stockage pour réutilisation des composantes précédemment calculée dans une
représentation.
46](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-55-320.jpg)
![6 Les Dépendances Orientées Objets
Un GDS [4] est une collection de GDP, un pour chaque procédure. Un GDP [10]
représente une procédure comme un graphe, dans lequel les nœuds sont les instructions ou les
expressions prédicatives. Les arcs de dépendances de données représentent un flux de données
entre des instructions ou des expressions, et les arcs de dépendances de contrôle représentent
des conditions de contrôle, sur lesquelles l’exécution d’une instruction ou une expression en
dépend.
Chaque GDP contient un nœud Entrée qui représente l’entrée dans la procédure.
Pour modéliser le passage des paramètres, un GDS associe, à chaque nœud d’entrée
d’une procédure, les nœuds «Formal-in» et «Formal-out».
Un GDS comporte un nœud «Formal-in» pour chaque paramètre formel de la
procédure, et un nœud «Formal-out» pour chaque paramètre formel qui peut être modifié[17]
par la procédure.
Un GDS associe, à chaque position d’appel dans la procédure, un nœud d’appel et un
ensemble de nœuds «Actual-in» et «Actual-out».
Un GDS contient un nœud «Actual-in» pour chaque paramètre effectif à la position
d’appel, et un nœud «Actual-out» pour chaque paramètre effectif qui peut être modifié par la
procédure appelée.
A l’entrée de la procédure et aux positions des appels, les variables globales sont
traitées comme des paramètres. Par conséquent, il y a des nœuds «Actual-in»,«Actual-out»,
«Formal-in» et «Formal-out» pour ces variables globales.
Notons aussi que les GDS relient les GDP aux positions des appels.
Un arc d’appel relie un nœud d’appel de la procédure au nœud Entrée du GDP de la
procédure appelée.
Les arcs «Parameter-in» et «Parameter-out» représentent le passage des paramètres. Les
arcs «Parameter-in» relient «Actual-in» et «Formal-in», et les arcs «Parameter-out» relient les
nœuds «Formal-out» et «Actual-out».
Pour faciliter le calcul d’une tranche interprocédurale qui considère le contexte d’appel,
un GDS représente le flux des dépendances à travers des endroits d’appel.
Un flux transitif de dépendance se produit entre un nœud «Actual-in» et un nœud
«Actual-out», si la valeur associée au nœud «Actual-in» affecte celle associée au nœud
«Actual-out». Le flux transitif de dépendance peut être généré par des dépendances de
données et/ou de contrôle. Un arc résumé modélise le flux transitif de dépendances à travers
un appel de procédure.
III-Les GDS des programmes orientés objets:
III-1-Graphe de Dépendances des Classes:
Cette section décrit la construction du GDC pour des classes singulières, des classes
dérivées, et des classes en interaction. De plus, elle discutera la manière avec laquelle on
représente le polymorphisme.
III-1-1-Représentation des classes de base:
Pour faciliter l’analyse et la réutilisation, on représente chaque classe dans un système
par un Graphe de Dépendances de la Classe (GDC).[25]
Un GDC capture les relations de dépendances de données et de contrôles qui peuvent
être déterminées à propos d’une classe sans connaître les environnements d’appel.
Chaque méthode dans un GDC est représentée par un GDP. Chaque méthode a un
nœud Entrée de la méthode représentant son entrée.
Un GDC contient aussi un nœud Entrée de la Classe qui est relié au nœud Entrée de la
méthode, pour chaque méthode dans la classe par un arc membre de la classe.
47](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-56-320.jpg)

![6 Les Dépendances Orientées Objets
Notre construction du GDC rajoute aussi des nœuds « Actual-in » et « Actual-out » au
nœud d’appel pour relier les nœuds «Formal-in» et «Formal-out» dans le constructeur de C2.
Quand il y a une position d’appel d’une méthode M1 de C1 à la méthode M2
appartenant à l’interface publique de C2, notre construction rajoute un arc d’appel entre le
nœud d’appel dans C1 et le nœud d’entrée de M2, sans oublier le rajout des arcs du
paramétrage.
Le chaînage de ces deux GDC forme un nouveau GDC représentant un système partiel.
III-1-4-Représentation du polymorphisme:
Un GDC doit représenter les appels polymorphiques de méthodes, qui se produisent
quand un appel de méthode est lancé, et la destination de l’appel est inconnue au moment de
la compilation.
Un GDC utilise un nœud Choix Polymorphique pour représenter le choix dynamique
parmi les destinations possibles. Un nœud d’appel correspondant à un appel polymorphique
possède un arc d’appel incidant à un nœud de choix polymorphique.
Un nœud de choix polymorphique a des arcs d’appel incidant aux sous-graphes
représentant les appels pour chaque destination possible.
Le nœud de choix polymorphique représente la sélection dynamique d’une destination.
Une analyse statique, à l’encontre, doit considérer toutes les possibilités.
III-2-Systèmes Incomplets:
Les classes et ses bibliothèques sont souvent développées indépendamment des
programmes d’application qui les utilisent.
Pour représenter ces systèmes incomplets pour analyse, on simule les environnements
d’appels possibles en utilisant un frame.[12]
Un frame représente un pilote universel pour une classe, qui nous permet de simuler
l’appel des méthodes publiques dans n’importe quel ordre.
En premier lieu, un frame appelle le constructeur de la classe, et entre par la suite dans
une boucle qui possède des appels à chaque méthode publique dans la classe. Pour chacune
des itérations de cette boucle, le contrôle peut passer à n’importe quelle méthode publique. A
la fin de cette boucle, le frame appelle le destructeur de la classe.
Un frame est le programme main d’un GDS pour un système incomplet. Par
conséquent, on l’utilise pour construire un GDP. L’appel au constructeur, la boucle du frame
et l’appel au destructeur sont tous en dépendance de contrôle avec le nœud Entrée du frame.
La boucle du frame est aussi en dépendance de contrôle avec elle même. Finalement, l’appel
du frame est en dépendance de contrôle avec sa boucle.
L’appel du frame est remplacé par des appels aux méthodes publiques dans la classe, et
les nœuds paramètres sont rajoutés aux endroits des appels.
Pour créer un GDP d’un frame d’une classe particulière, on remplace le nœud d’appel
du frame par les nœuds d’appel pour chaque méthode publique dans la classe.
Notez que, vu que les variables gardent leurs valeurs entre les appels des méthodes, il
peut y avoir des dépendances de données entre les endroits des appels, même si les variables
ne sont pas visibles dans le programme d’appel. pour expliquer ces dépendances de données,
notre construction rajoute des arcs de dépendances de données entre les nœuds « Actual-out »
de chaque appel de méthode et les nœuds « Actual-in » correspondant à tout autre appel de
méthode.
On doit signaler qu’on ne peut avoir un flux (propagation) de valeurs à travers le
constructeur de la classe, à l’exception des paramètres formels, vu qu’il n’existe aucune
valeur des instances de variables précédemment utilisées. De même, on ne reçoit aucun flux
49](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-58-320.jpg)


![7 Les Tranches – Concepts De Base
Les tranches – Concepts généraux-
I-Introduction:
La troncature des programmes est une opération qu’on effectue sur les relations de
dépendances et qui a plusieurs applications telles que le débogage, la compréhension de code,
tests des programmes et l’analyse des métriques. Elle permet d’extraire des tranches dont le
comportement est indiscernable du programme initial en respectant un critère de troncature
composé d’un point p du programme et d’un sous-ensemble de variables V de ce programme.
II-Définition d’une tranche:
Les tranches sont des programmes exécutables qui sont construits par élimination
(suppression) de zéro ou plusieurs instructions du programme initial.
Une tranche de programme, par rapport à un point p et une variable v, consiste en des
instructions du programme et de ses prédicats qui peuvent affecter la valeur de v au point p.
Son comportement est identique à celui du programme d’origine par rapport à un critère
donné, c’est à dire qu’une tranche est un fragment du programme d’entrée, isolé par rapport à
une instruction critique dans le programme.
La variable v et le point p définissent le critère de troncature noté C=<p,v>. En d’autres
termes, une tranche de programme est un programme de taille réduite dont le comportement
par rapport à un critère donné est identique à celui du programme source.
III-Extraction des tranches de programmes – Procédés et Algorithmes-:
Les algorithmes utilisés pour l’extraction des tranches se basent sur l’analyse du flux de
données et de contrôle en déterminant ainsi les tranches inter et intra-procédurales.
Ottenstein et Ottenstein [ ] définissent un algorithme efficace utilisant une méthode de
parcours de graphe sur GDP. Horwitz, Reps et Binkley utilisent aussi les graphes de
dépendances et ils ont développé une représentation interprocédurale du programme qui est le
GDS et un algorithme de parcours du graphe en deux passes exploitant ce GDS.
Notez que le type de parcours du GDS définit le type de la tranche, de ce fait, on a deux
types de tranches:
1. Une tranche arrière [Weiser 84]: c’est une tranche composée de toutes les
instructions et prédicats dont dépend le calcul de la valeur de v au point p.
2. Une tranche avant [Binkley95 – Jackson94 – Reps95]: c’est une tranche composée
de toutes les instructions et prédicats qui peuvent dépendre de la valeur de v au point
p. Autrement dit, la tranche avant est le dual de la tranche arrière.
D’après [Binkley93], une tranche interprocédurale d’un GDS par rapport à un nœud v
est calculée en utilisant deux passes sur le graphe. Les arcs résumés sont utilisés pour
permettre de passer d’un nœud d’appel à un autre sans avoir à descendre vers la procédure
appelée. Par conséquent, ceci n’a pas besoin de garder une trace explicite du contexte d’appel
pour s’assurer que les liaisons d’une exécution légale se sont traversées.
Les deux passes opèrent sur le GDS, en traversant les arcs afin de trouver l’ensemble
des instructions qui peuvent atteindre (affecter) un ensemble donné de nœuds, tout au long de
certains types d’arcs.
Le parcours dans la première passe commence à partir de tout nœud v et va en marche
arrière (depuis la cible jusqu’à la racine) à travers les arcs de flux, arcs de contrôle, arcs
d’appel, arcs résumés et les arcs «Parameter-in» des paramètres d’entrée, mais non plus à
travers les arcs «def-ordre» ou «Parameter-out» des paramètres de sortie.
Le parcours dans la deuxième passe commence à partir de tous les nœuds atteints dans
la première passe et part en marche arrière à travers les arcs de flux, arcs de contrôle, arcs
52](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-61-320.jpg)
![7 Les Tranches – Concepts De Base
résumés et les arcs «Parameter-out» des paramètres de sortie, mais non plus à travers les arcs
«def-ordre» ou les arcs «Parameter-in» .
Le résultat d’une tranche interprocédurale se compose des ensembles de nœuds
rencontrés (parcourus) durant les deux phases (c’est un sous-graphe du graphe de départ).
Pour la troncature intra-procédurale, la tranche d’un graphe de dépendances peut être
utilisée pour produire un programme exécutable par restriction du système initial aux
éléments dont les nœuds sont dans la tranche du graphe de dépendances.
Il est totalement faux de considérer le même raisonnement sur une tranche directement
produite à partir d’un GDS vu qu’on peut trouver des instructions syntaxiquement illégales,
parce qu’elles contiennent des paramètres incompatibles. Ça est dû au fait que deux
instructions d’appel, représentant des appels d’une procédure, contiennent des sous-ensembles
différents de paramètres de la procédure.
Il y a deux problèmes relatifs à l’incompatibilité:
1. Deux endroits d’appel pour la même procédure peut inclure des nœuds «Actual-in»
différents.
2. Deux endroits d’appel pour la même procédure peut inclure des nœuds «Actual-out»
différents.
L’extraction de tranche (troncature) a grandement évolué depuis sa naissance dans
Weiser[1984], et plusieurs nouveaux algorithmes destinés à résoudre ce problème ont vu le
jours. Le plus connu est celui utilisant le concept des graphes de dépendances des
programmes (GDP)[Ferrante et Ottenstein 1987, Horwitz et al 1990, Ottenstein et Ottenstein
1984].
Le GDP est une structure de données adéquate principalement pour la troncature, parce
qu’il intègre l’ensemble des flux de données et de contrôle en un seul graphe, et par
conséquent, réduit la troncature de programme en un problème de parcours d’un
graphe[Ottenstein et Ottenstein 1984].
Dans le contexte des application temps réel, on admet les hypothèses suivantes
concernant la structure des programmes:
Toute condition contient seulement une variable booléenne simple.
Les instructions de saut inconditionnel tel que Goto et break ne sont pas présentes
dans le code de la tâche.
Algorithme de la troncature des programmes:
On va s’intéresser à la troncature exécutable, arrière et statique des programmes, c’est à
dire que:
Chaque tranche est exécutable comme un programme propre.
Les tranches sont calculées selon des données statiques disponibles, données arrières
et les informations du flux de contrôle.
Conceptuellement, une tranche arrière d’un programme P, par rapport à un point p et
une expression e, est composée des instructions de P et les prédicats de contrôle qui peuvent
affecter la valeur de e au point p.
Le couple (p,e) est généralement appelé le critère de la troncature et la tranche associée
est notée P/(p,e). L’idée est que pour déterminer la valeur de e à p, on a besoin seulement
d’exécuter la tranche P/(p,e).
L’algorithme d’extraction a besoin de considérer les trois types de dépendances de
données, de flux, anti-dépendances et dépendances de sortie. Ça peut être effectué de manière
directe par extension de la définition du GDP (ou GDS) pour avoir un GDPE (Graphe de
Dépendances de Programme Etendu).
53](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-62-320.jpg)


![8 Les Tranches Orientées Objets
Les tranches dans les Systèmes Orientés Objets:
I-Introduction:
La troncature des programme a plusieurs applications telles que le déboggage, la
compréhension de code, tests des programmes et analyses des métriques.
Weiser [20] définit une tranche en respectant un critère de troncature qui consiste en un
point p et un sous-ensemble de variables V du programme. Ces tranches sont des programmes
exécutables qui sont construits par suppression de zéro ou plusieurs instructions du
programme original.
Son algorithme utilise l’analyse du flux de données et les graphes de flux de contrôle
pour calculer les tranches inter et intra-procédurales.
Ottestein & Ottenstein [20]définissent un critère de troncature en se référant à un point p
du programme et une variable v qui est définie ou utilisée au point p. Ils utilisent un
algorithme de parcours de graphe sur le GDP pour calculer une tranche qui se compose de
toutes les instructions et prédicats du programme qui peuvent affecter la valeur de v au point
p.
Horwitz, Reps et Binkley [14] utilisent aussi les graphes de dépendances pour calculer
les tranches. Ils ont développé la représentation interprocédurale du programme qui est le
GDS et un algorithme de parcours du graphe en deux passes qui exploite ce GDS.
L’algorithme des deux phases calcule des tranches inter-procédurales plus précises
parce qu’il utilise les informations résumées aux endroits d’appels en considérant le contexte
d’appel des procédures appelées.
II-Environnement de l’algorithme et son application :
Pour dresser les caractéristiques orientées objets, on a développé des GDS pour les
applications orientées objets sur lesquels un algorithme de troncature interprocédurale [14,
23] sera appliqué.
On doit noter que la technique adoptée permet le calcul de tranches pour des classes
uniques (seules) ainsi que les tranches pour des systèmes complets.
Les GDS définis pour les programmes orientés objets sont adéquats pour l’application
de l’algorithme d’atteinte du graphe de deux phases afin de calculer les tranches. Cet
algorithme utilise un critère de troncature <p,x> dans lequel p est une instruction et x est une
variable qui est définie ou utilisée au point p.
Les développeurs de logiciels orientés objets empêchent les utilisateurs d’une classe de
manipuler de manière directe les instances des variables à l’intérieur d’un objet (l’état de
l’objet), en fournissant des méthodes comme une interface afin de situer et observer l’état de
l’objet. Par conséquent, les systèmes orientés objets substituent plusieurs références de
variables avec des appels de méthodes qui retournent simplement une valeur.
Pour nous permettre de tronquer sur les valeurs retournées par une méthode, on utilise
un critère de troncature peu modifié. Notre critère de troncature <p,x> se compose d’une
instruction et une variable ou un appel de méthode x.
Si x est une variable, elle doit être définie ou utilisée à p. Si x est un appel de méthode,
cette dernière doit être appelée à p.
Tant que notre construction du GDS crée des arcs résumés, qui sont utilisés pour
préserver le contexte de l’appel, on calcule les tranches qui satisfont notre critère sur nos GDS
en utilisant l’algorithme des deux phases.
Durant la première phase de l’algorithme de troncature, les arcs résumés facilitent la
troncature à travers les nœuds d’appel (de l’un à l’autre), qui ont des dépendances transitives
sur des nœuds «Actual-in».
56](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-65-320.jpg)
![8 Les Tranches Orientées Objets
Durant la deuxième phase de l’algorithme, on descend dans les méthodes appelées
(procédures) à travers les arcs «Parameter-out».
Vu qu’on calcule une tranche, comme si toutes les séquences possibles des appels aux
méthodes publiques étaient possibles, le calcul peut inclure dans ses résultats plus
d’instructions par rapport à une même tranche prise à partir d’un programme d’application
qui spécifie une séquence d’appels particulière de méthodes publiques.
Cependant, durant le développement, ce type de tranches peut être utile tant qu’elles
indiquent les dépendances qui peuvent exister entre les instructions dans la classe, et peut
aider dans la compréhension , le déboggage ou le test de la classe.
Notez bien que les notions de tranche avant et tranche arrière se conservent pour les
applications orientées objets de même que pour une application classique simple.
III- Extraction de tranche (Tranche Arrière):
La première phase de l’algorithme de troncature interprocédurale traverse en marche
arrière le long de tous les arcs du GDS à l’exception des arcs «Parameter-out» et marque les
nœuds atteints.
La deuxième phase traverse en arrière, à partir de tous les nœuds marqués durant la
première phase, le long de tous les arcs à l’exception de ceux d’appel et «Parameter-in», et
marque les nœuds atteints.
La tranche est l’union des nœuds marqués durant les deux phases.
III- Troncature d’objet:
Dans un programme orienté objet, quand un objet est instancié à partir d’une classe, les
membres de données et méthodes de la classe sont instanciés pour cet objet.
Le fait qu’on utilise une seule représentation pour toutes les instances d’une méthode,
toutefois, l’ensemble des instructions dans une méthode identifié par un algorithme de
troncature, tel que Horwitz & al[7], inclut les instructions dans des différentes instances de la
méthode.
Pour l’étude des tâches, on doit s’accentuer sur un seul objet à la fois. Pour cela, on veut
identifier l’ensemble des instructions dans les méthodes d’un objet particulier, qui peut
affecter le critère de troncature. C’est la troncature d’objet.
L’extraction d’une tranche d’un objet O, par rapport à un critère (v,p), on doit en
premier lieu avoir la tranche complète à partir du GDS par rapport à (v,p). Ensuite, on
identifie les endroits d’appel (envoi de message), qui ont été marqués par l’algorithme de
troncature. Les méthodes invoquées par ces sites d’appels sont les seules méthodes de O qui
peuvent affecter (v,p). Par la suite, on identifie les instructions dans ces méthodes qui sont
incluses dans la tranche vu l’invocation des endroits d’appel sélectionnés. On appelle ces
instructions la tranche de O.
Pour identifier les endroits d’appel et d’envoi de message, qui ont été marqués par
l’algorithme de troncature, on examine les nœuds, le sous graphe de flux de l’objet O dans la
méthode ou la procédure dans laquelle O est construit. Si O est passé comme un paramètre à
une autre méthode ou procédure, on traverse l’arc de liaison à l’endroit d’appel , et on
continue à examiner le sous graphe de flux de l’objet paramètre formel dans la méthode ou la
procédure appelée. Le parcours se poursuit jusqu’à ce que tous les sites d’appel de l’objet
soient examinés.
Une instruction S dans une méthode d’un objet peut affecter (v,p) de plusieurs manières.
Premièrement, S peut affecter un paramètre «Actual-out» Aout dans un endroit d’appel (envoi
de message) de l’objet O, qui appelle M, et Aout à son tour peut affecter (v,p). Ce cas se
produit quand l’exécution de P doit se passer après le retour de l’appel. l’ensemble des Aout
est l’ensemble des nœuds «Actual-out», qui sont marqués par les deux phases de l’algorithme
57](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-66-320.jpg)



![10 Restructuration Des Programmes Orientés Objets (Java)
Restructuration des programmes
Concepts de base – Application aux Programmes Orientés Objets:
I-Introduction:
La restructuration de programmes est une méthodologie de transformation et
modification de la structure interne de codes, tout en conservant leurs sémantiques.
L’adoption de cette technique a grandement facilité la compréhension des programmes et la
maintenance des logiciels, elle permet de plus d’avoir un code optimisé, améliorer
l’ordonnançabilité, la décomposition, la conversion et la réutilisation de composantes de
programmes. Elle est un moyen efficace pour l’étude comportementale des programmes.
Dans notre étude, cette technique sera appliquée aux programmes temps réels, où le
facteur temps représente un paramètre essentiel pour l’analyse du comportement du système.
L’évolution de tels systèmes peut importer des modifications sur les caractéristiques temps
réels des tâches (échéances, temps d’exécution,…)[POS92], ou surcharger les ressources. De
ce fait, la restructuration devient une nécessité devant le développement d'un programme
d’une application temps réel qui tend à devenir peu structuré. De plus, la restructuration
semble être le moyen adéquat et une option importante pour le contrôle des coûts de la
maintenance des logiciels. Il existe d’autres raisons pour la restructuration telles que :
Faciliter les tests.
Réduction potentielle de la complexité des programmes.
Etendre la durée de vie des programmes en maintenant une flexibilité à travers une
bonne structure.
Mise en place de standards pour les structures des programmes.
Préparer les programmes pour faire l’objet d’entrée à des outils (parallélisme,
test,..).
Préparer les programmes pour la conversion.
Préparer pour ajouter de nouvelles caractéristiques au logiciel.
La restructuration est aussi appliquée en cours de développement des logiciels, surtout
en cas de non possession de méthodes de programmation rigoureuses, en ayant comme
objectif l’amélioration des performances du logiciel. On en déduit que la restructuration n’est
une fin d’autant qu’elle ne soit un moyen pour réaliser des objectifs fixés tels que :
Rendre le code en cours d’étude plus facile à comprendre, sans altérer ses
dépendances de données ou de contrôle.
Formatage du code (restructuration textuelle).
Souplesse dans la détermination du flux de contrôle.
Durant la phase de développement d’une application, on peut être amené à concevoir
des tâches non ordonnançables. Cela peut entraîner l’échec du système dans l’exécution à
temps d’une tâche temps réel, causé par une violation d’échéance[STE97]. Pour palier à ce
type de problème, les programmeurs procèdent manuellement, à d’intenses activités de
modifications, de déplacement de portions de codes, de prise de mesure et de restructuration.
Un tel processus est lent, coûteux et non contrôlable[CHU95,GER97]. Il se pourrait que dans
certains cas, que tout un système doit être reconçu.
II-Approche de restructuration:
Nous savons déjà que la restructuration est un moyen de changement de la structure
interne d’un programme en gardant sa sémantique intacte.
En cas de l’application de ce concept pour améliorer l’ordonnançabilité, on obtient
comme résultat, des échéances flexibles. Nous pouvons assurer la flexibilité en restructurant
61](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-70-320.jpg)



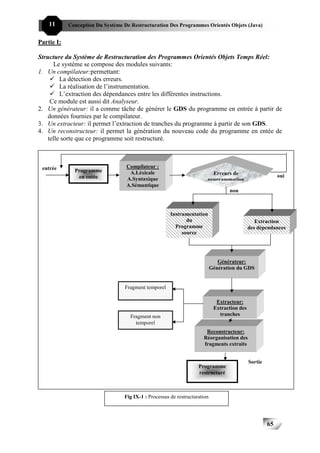
![11 Conception Du Système De Restructuration Des Programmes Orientés Objets (Java)
Ce module est basé sur les résultats offerts par l’extracteur. Ce dernier permet l’extraction du
fragment temporel et du fragment non temporel du programme source. De ce fait, le
reconstructeur va tenter de placer le fragment non temporel après celui du temporel. Par
conséquent, le code produit représente un programme restructuré qui permet de respecter les
échéances des tâches et assurant ainsi une exécution correcte et sûre.
On peut schématiser le fonctionnement de ce système ainsi:
Partie II:Approche De Restructuration
Modèle Basé Tranches pour la Restructuration d’Applications Temps Réel Objets
I- Introduction:
Le monde du temps réel s’est élargi considérablement ces dernières années, ce qui a
permis par conséquent d’améliorer les méthodes d’ingénierie. Plus particulièrement, les
méthodes orientées objets ont été étendues et couplées avec les propriétés temps réel, en
fournissant des mécanismes au modèle d’activité temporel[Ishik92][Kim97].
On va considérer le domaine des applications temps réel, où les tâches sont accomplies
régulièrement afin de contrôler des processus physiques ou un fonctionnement de moniteur. Il
est extrêmement important de rencontrer des contraintes de temps dans de tels systèmes. Pour
satisfaire leurs échéances, les tâches doivent être ordonnancées d’une manière appropriée. Les
algorithmes d’ordonnancement des tâches dans les systèmes temps réel [Liu73][Klein94]
permettent de s’assurer que toutes les tâches peuvent être accomplies au bout de leurs
échéances de telle sorte qu’aucune d’elles ne dépasse son temps d’exécution dans le plus pire
des cas. Une tâche qui dépasse son temps prévu, peut mener à la perte de l’échéance et l’échec
de tout le système.
Notons qu’une violation d’une échéance rend les tâches non ordonnançables. Dans ce
cas, on fait appel à des techniques manuelles et de force brute pour remettre les tâches dans
une situation d’ordonnaçabilité. Les développeurs accomplissent des opérations intensives et
manuelles telles que l’instrumentation, prise de mesure, déplacement de fragments de
programmes et éventuellement une reconception du système. Malgré ce que fournissent les
caractéristiques du modèle orienté objet, telles que l’héritage et le polymorphisme, en terme
de réutilisabilité et flexibilité, elles rendent le système plus difficile pour l’étude et un
processus pénible et coûteux[Wilde92]. Les développeurs doivent extraire et comprendre
l’interdépendance du comportement temporel d’objet, dans le but d’analyser et réarranger son
code interne. Dans plusieurs applications, les objets sont rassemblés dans des groupes pour
donner le service du temps réel afin de répondre à quelques buts. Avec ce groupe, les objets
forment les relations Client-Serveur. De plus, le nombre relativement important et la petite
taille des méthodes dans des programmes orientés objets typiques augmentent le nombre de
ces relations[Bihari92][Wilde92].
Dans la perspective de l’ordonnanceur rate-monotonic, Gerber et Hong[Gerber97] ont
montré qu’ils peuvent améliorer l’ordonnançabilité en divisant une tâche de programme en
deux fragments. Le premier dépend d’un événement observable, et le deuxième concerne le
calcul interne, qui peut être retardé. Cependant, la présente approche traite seulement les
programmes monolitiques et procéduraux simples, indépendamment des contraintes de
synchronisation introduites en augmentant le nombre de tâches.
Afin d’achever l’ordonnançabilité, on propose une approche semi-automatique qui est
l’extension de solutions précédentes et qui est adaptée au modèle temps réel objet. D’une
66](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-75-320.jpg)
![11 Conception Du Système De Restructuration Des Programmes Orientés Objets (Java)
manière spécifique, quand on trouve un ensemble de tâches surchargé et non ordonnançable,
un analyseur d’ordonnancement choisit les tâches appropriées pour les restructurer. On met en
œuvre le module de restructuration en faisant appel au concept de l’analyse de dépendance du
système orienté objet.
Par conséquent, notre approche de restructuration est basée sur deux concepts :les
tranches de programme et la technique d’ordonnancement à priorité fixe. Les tranches de
programme, définies en premier lieu par Weiser[Weiser84], sont basées sur l’analyse du flux
de données statique sur le graphe de flux du programme. C’est une technique d’isolation des
Threads de calcul dans les programmes. Une tranche de programme consiste en les parties du
programme qui affectent potentiellement les valeurs calculées par rapport à quelques points
d’intérêt. Un point d’intérêt de tranche est généralement spécifié par une position dans le
programme avec un sous ensemble de variables du programme. Par exemple, on peut isoler
une tranche par rapport à une instruction critique ou une méthode dans un programme, une
instruction qui émet une commande à un actionneur ou une instruction d’une alarme dans une
tâche de contrôle. Les tranches statiques d’un programme ont été appliquées avec succès dans
les outils de programmation pour les langages non orientés objets tels que Pascal[Horwitz90]
[Ben97], pour le déboggage, le test, ou la maintenance des logiciels. Mais avec quelques
extensions, elles sont toujours efficaces dans le domaine de l’orienté
objet[Larsen96][Lang97][Hang98].
En utilisant le concept des tranches de programme, notre méthode de restructuration
permet d’améliorer l’ordonnançabilité d’un ensemble de tâches de deux façons. D’abord, on
respecte toujours les différentes dépendances dans le code d’une tâche non ordonnançable, on
s’assure que les instructions qui affectent l’échéance (fragment temporel) soient exécutées en
premier lieu. Le fragment de code qui correspond au calcul interne (fragment non temporel)
peut être différé. De plus, elle permet la décomposition d’une ou plusieurs tâches en sous
tâches, de telle sorte qu’on puisse utiliser des méthodes d’ordonnancement à priorité fixe
généralisées[Härbour94], qui peuvent augmenter l’ordonnançabilité d’un ensemble de tâches,
mieux qu’appliquer l’algorithme rate-monotonic. En restructurant une tâche choisie parmi
l’ensemble de tâches d’origine, on peut augmenter l’ordonnançabilité totale.
On a appliqué notre solution sur les applications temps réel Java, vu qu’il est
actuellement le langage le plus utilisé et qui est purement objet, ressemblant au langage
populaire C++, mais plus simple. En effet, en combinant les conventions spéciales du temps
réel de la machine virtuelle de Java avec les facilités de ce dernier, Java autant qu’un langage
objet pur, permet le traitement d’activités temps réel (ramasse miette, multithread, protection,
simplicité et portabilité)[Hamilton96].
II- Modèle Temps Réel Objet:
Le modèle de calcul uniforme du paradigme orienté objet permet d’avoir une bonne
représentation des entités du temps réel, du point de vu physique ou logique[Bihari92]. Par
exemple, dans un logiciel de contrôle d’un manipulateur, les objets du logiciel représentent le
manipulateur soit même, les actionneurs et les entités conceptuelles du planificateur. Les
contraintes de temps[Das85] peuvent être représentées dans le modèle du temps réel objet, qui
offre des constructions au développeur permettant de spécifier les implémentations d’objets
spécifiques et des messages d’efficience et de prévision acceptables[Bihari92][Ish92].
II-1- Approches d’ordonnancement:
Le problème le plus fondamental et classique dans les systèmes temps réel est
l’ordonnancement d’un ensemble de tâches périodiques, qui s’exécutent sur un seul
CPU[Gerber97]. Ce modèle peut être décrit par : (1)une tâche est un programme ayant un seul
Thread (bloc temporel), qui s’exécute indéfiniment avec une périodicité positive, où ce type
67](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-76-320.jpg)
![11 Conception Du Système De Restructuration Des Programmes Orientés Objets (Java)
de programme est la construction de bloc commune trouvée dans les applications temps réel,
et (2) un ensemble de tâches est une collection de tâches périodiques.
Une tâche périodique, notée t, est une séquence infinie d’instances de tâches demandée
avec un taux fixe dans un environnement temps réel. Considérons un ensemble de n tâches
périodiques t1, t2, …, tn. Chaque tâche est caractérisée par trois composantes (Ci, Ti, Di),
1<=i<=n. Ci est le temps d’exécution dans le plus pire des cas de la tâche ti (chacune des
instances de tâche a le même taux de calcul). Ti est la période de la tâche. Di est l’échéance de
la tâche ti, par lequel elle doit être complétée. Un ordonnanceur temps réel[Klein94] décide
quand est ce que chaque tâche requisitionne le processeur. Un traitement théorique de
l’ordonnancement avec priorité fixe, apparue en 1973, quand Liu et Layland[Liu73] ont
introduit l’algorithme rate-monotonic pour des tâches périodiques et indépendantes.
Dans [Härbour94], Harbour et al, a considéré une classe de problèmes plus générale, et
fournit une structure pour l’analyse de l’ordonnançabilité dans le contexte de l’algorithme
d’ordonnancement avec priorité fixe d’un ensemble de tâches composées de sous tâches, qui
ont des niveaux de priorité différents. Comparé avec la technique rate-monotonic, il a été
démontré que cette méthode offre une meilleure ordonnançabilité.
II-2- Application temps réel en Java:
Evidemment, les développeurs temps réel ont besoin de langages orientés objets simples
supportant le développement rapide, la portabilité, la robustesse, la reconfiguration rapide, la
sécurité et une haute performance. Java, comme étant un système orienté objet pur, possède
des caractéristiques avancées telles qu’une efficace fonction de ramasse miettes, le
multithreads et l’absence du type pointeur afin d’améliorer la sécurité[Hamilton96].
Quelques problèmes particuliers du domaine des systèmes temps réel embarqués sont
adressés par la conception d’un environnement de programmation temps réel Java. Les
implémentations temps réel Java sont devenues utiles pour la programmation des applications
temps réel www distribuées (exemple : gestion de stock et commerce, animation interactive,
les jeux, et la téléconférence), et pour l’implémentation d’applications temps réel embarquées
plus traditionnelles (exemple : dans les systèmes de navigation, interface de traitement vocal
et graphique, contrôle du trafic aérien, environnement de la réalité virtuelle et les systèmes de
défense à missile).
III- Fragmentation de programmes orientés objets:
Dans le but d’avoir des échéances de tâches flexibles, vu que l’ordonnançabilité est
améliorée tant que la flexibilité des échéances augmente, on effectue une transformation sur le
programme de la tâche, de telle sorte que cette dernière puisse aller au delà de son échéance.
On peut procurer cette avantage en ramenant le fragment non temporel à s’exécuter après le
fragment temporel. Ensuite, les fragments sont recomposés séquentiellement, afin de
constituer un nouveau programme de la tâche en question, qui est sémantiquement équivalent
à celui d’origine.
La figure 1.a représente le comportement d’exécution d’une tâche périodique. Les
parties ombrées dans les figures 1.a et 1.b représentent les composants temporels du
programme de la tâche. Dans la (k+1)ième période, l’exécution de cette tâche va au delà de
son échéance et devient, par conséquent, non ordonnançable
cas où les instructions temporelles devraient s’achever au bout de la période prescrite,
l’exécution de la tâche entière est acceptable
III-1- Représentation des dépendances:
68](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-77-320.jpg)
![11 Conception Du Système De Restructuration Des Programmes Orientés Objets (Java)
On calcule un fragment de programme en utilisant le concept de tranche de programme,
basé sur la représentation du programme. Les chercheurs ont considéré plusieurs manières
pour la représentation des programmes orientés objets[Larsen96][Lang97][Hang98]. Les
caractéristiques orientées objets, telles que les classes et les objets, l’héritage, le
polymorphisme et la liaison dynamique interviennent dans le développement d’une
représentation efficace d’un programme orienté objet. Une classe définit les attributs qu’une
instance d’une classe (objet) va posséder. Les attributs d’une classe consiste en l’instance des
variables qui implémentent l’état de l’objet, et des méthodes modélisant les opérations sur
l’état de l’objet.
Un bon graphe de représentation d’une application orientée objets doit inclure la
représentation de classes qui peuvent être réutilisées dans la construction de d’autres classes et
applications utilisant ces dernières. Les classe dérivées sont définies à travers l’héritage, qui
permet à la classe dérivée d’hériter des attributs provenant de ses classes parentes, de les
étendre, restreindre, redéfinir ou les remplacer en quelque sorte. Tout comme ce que fournit
l’héritage en facilitant la réutilisation de code, un bon graphe de représentation pour une
classe dérivée doit faciliter la réutilisation des informations des classes. Le polymorphisme est
une caractéristique importante pour les langages orientés objets qui permet durant l’exécution
le choix d’une des destinations parmi celles de l’ensemble des appels de méthode.
Une représentation statique d’un choix dynamique exige que toutes les destinations
possibles doivent être incluses, à moins que le type puisse être déterminé statiquement.
Malgré la limite de la visibilité des variables d’une instance d’objet (état), ces variables
d’instance retiennent ses valeurs entre les appels de méthode à l’objet.
Une représentation doit compter pour les dépendances des variables des instances entre
les appels aux méthodes de l’objet par un programme d’appel, même si les variables
d’instance ne sont pas visibles au programme d’appel. Pour pouvoir le réaliser, on construit
un Graphe de Dépendance Etendu du Système (EGDS:Extended System Dependance Graph),
basé sur la représentation des différents concepts orientés objets, principalement ceux
proposés dans [Hang98], avec quelques adaptations qu’on introduit, et qui sont nécessaires
pour notre processus de restructuration.
Méthode d’Objet. Contrairement aux travaux décrits dans [Larsen96][Hang98], dans chacune
des méthodes de l’objet, on a besoin de considérer tous les trois types de dépendances de
données:flux, sortie et anti-dépendance, car les transformations modifient l’ordre des
instructions. Cela peut être fait directement par un Graphe de Dépendance de Méthode
(MDG:Method Dependance Graph): Le MDG est formé de (N,E) avec:
Les nœuds N représentent les instructions, i.e., assignation, prédicat de contrôle, appel de
méthode, ou une instruction temporisée (telle qu’une entrée ou une sortie). De plus, il y a
un nœud particulier « Entry » qui représente la racine de la tâche.
Les arcs E, qui sont de deux types: un arc v1 v2, qui indique une dépendance de
contrôle entre v1 et v2. De ce fait, soit (1)v1 est un Entry, et v2 n’est pas lié ni à une
boucle ou une condition, ou bien, (2) v1 représente un prédicat de contrôle, et v2 est
immédiatement dans une boucle ou une condition dont le prédicat est représenté par v1.
un arc v1 v2 dénote un flux, une sortie ou une anti-dépendance. Pour cela, un contrôle
peut atteindre v2 après v1 via une trajectoire au long de laquelle il n’y a aucune définition
d’une variable m :
v1 définit m, et v2 l’utilise (dépendance de flux).
v2 définit m, et v1 l’utilise (anti-dépendance).
v1 et v2 définissent tous les deux m (dépendance de sortie).
69](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-78-320.jpg)
![11 Conception Du Système De Restructuration Des Programmes Orientés Objets (Java)
En outre, on traite l’action de construction d’objet (new) comme une instruction d’appel.
On la représente par la suite par un nœud Entry, relié par des arcs de dépendance de contrôle
aux nœuds représentant ses membres de données.
Membres de Données d’Objet. On suppose de plus que les membres d’un objet peuvent être
accédés seulement à travers une méthode. Enfin, on traite les membres de données statiques
comme étant des variables globales et les méthodes statiques comme des méthodes globales,
parce qu’elles ne s’associent à aucun objet particulier durant l’exécution. Pour pouvoir
représenter un objet récepteur de message, on poursuit le schéma de Larsen et
Horrold[Larsen98]. Un site d’appel contient des nœuds de membres de données «Actual-in»
représentant les membres de données qui sont référencés, et des nœuds de membres de
données «Actual-out» représentant les membres de données modifiables par une méthode
appelée. Pour pouvoir supporter cette représentation, un nœud «Method Entry» contient les
nœuds de membres de données «Formal-in» représentant les membres de données référencées
dans la méthode, et les nœuds de membres de données «Formal-out» représentant les
membres de données modifiables dans la méthode. Les nœuds de membres de données
«Formal-in» sont libellés par des assignations qui copient la valeur des membres de données
d’un objet dans la portée de la méthode au début de cette dernière, et les nœuds des membres
de données «Formal-out» sont libellés avec des assignations qui copient la valeur des
membres de données à partir de la portée de la méthode dans l’objet, à la fin de cette dernière
encore. Suivant cette approche, les dépendances de données relatives aux membres de
données de la classe dans une méthode sont calculées de la même manière que celles pour une
procédure [Horwitz90][Hang98].
Objets Paramètres. Comme situé dans [Hang98], pour obtenir plus de précision quand un
objet est utilisé comme étant un paramètre, un objet paramètre est représenté comme un
arbre : la racine représente l’objet lui même, les fils de la racine représentent les membres de
données de l’objet, et les branches de l’arbre représentent les dépendances de données entre
l’objet et ses membres de données.
Afin de pouvoir calculer des dépendances de données, quand un arbre est utilisé dans la
représentation d’un objet, les utilisations ou les définitions sont associées aux nœuds des
membres de données.
Objet Polymorphique. Un objet polymorphique est représenté par un arbre[Hang94], dont la
racine représente cet objet et les fils de la racine représentent les objets de tout type possible.
Classe dans la Hiérarchie. Comme dans [Hang94], à travers une hiérarchie d’une classe, on
garde une copie de la représentation pour une méthode, et cette représentation peut être
partagée par différentes classes dans cette hiérarchie. Un nœud d’entrée de classe regroupe les
méthodes appartenant à une classe et utilisant ensemble les arcs des relations membres. Pour
identifier la classe d’origine, dans laquelle une méthode à été déclarée, on fait précéder le nom
d’une méthode par le nom de la classe d’origine.
Construction du ESDG. Comme dans Java, toute méthode ou variable fait partie d’une classe,
notons que les méthodes et variables statiques sont en dépendance de contrôle au nœud
d’entrée du programme P. Pour la construction du ESDG d’un programme, on poursuit les
étapes suivantes:
Etape 1- Construction des Graphes de Dépendance des Méthodes (MDG):
70](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-79-320.jpg)
![11 Conception Du Système De Restructuration Des Programmes Orientés Objets (Java)
On construit en premier lieu un MDG pour chaque méthode invoquées d’une manière directe
ou indirecte dans le programme. La construction est faite d’une manière ascendante (figure 2),
suivant la hiérarchie de la classe (une méthode statique va appartenir à la classe spéciale
correspondante à P). Le constructeur de classe est représenté comme une méthode avec les
variables formelles et effectives correspondantes seulement aux attributs de la classe qui sont
référencées dans le programme de la tâche.
Etape 2- Calcul des arcs résumés dans les endroits d’appel:
L’endroit d’appel d’une méthode est représenté par (1)un nœud d’entrée, relié par un arc de
contrôle au paramètre effectif, (2)les arcs résumés. Ensuite, on relie les MDG à leurs endroits
d’appel correspondants.
Etape 3- Construction des arcs de dépendances de données.
III-2- Les tranches dans les Systèmes Objets:
Nous sommes concernés par les tranches arrières. Pour plus de clarification, et afin de
permettre l’extraction de tranches par rapport à une valeur retournée par une méthode, on
reformule la définition d’une tranche comme suit : « une tranche d’un programme P par
rapport à un point p et une variable ou un appel de méthode m (si m est une variable, elle doit
être définie ou utilisée au point p), consiste en les instructions et prédicats de P, qui peuvent
affecter m au point d’exécution p ». Une paire <m,p>est généralement appelée le critère de la
troncature, et la tranche associée est notée P/<m,p>.
Horwitz et al[Horwitz90] calculent les tranches interprocédurales en résolvant un
problème d’atteinte de graphe sur le graphe de dépendance du système (SDG). Vu que le
ESDG qu’on calcule pour un programme orienté objet appartient à une classe du SDG définie
par Horwitz et al, on peut utiliser cette technique pour calculer une tranche, avec une petite
modification. La première passe de l’algorithme de troncature traverse en marche arrière à
travers tous les arcs, à l’exception des arcs «Parameter-out», et marque tous les nœuds
atteints. La deuxième passe traverse en marche arrière à partir de tout les nœuds marqués
durant la première passe, à travers tous les arcs, à l’exception des arcs d’appel et «Parameter-
in», et marque les nœuds atteints. La tranche est l’union des nœuds marqués durant les deux
passes.
La figure 3 schématise la tranche calculée par rapport au critère <<31>, <b>>, qui
correspond à la ligne 31 dans le programme Java de l’exemple, et la variable b. En
accomplissant les deux passes, la tranche est formée des nœuds ombrés dans le ESDG. La
ligne de numéro 31 indique que l’instruction qui émet (envoie) la variable b à l’actionneur.
Suivant l’événement basé paradigme [Hang98], l’échéance de la tâche est placé sur cette
action de sortie. Par conséquent, on détermine toutes les instructions qui influencent de telle
action pour former le fragment temporel. Le reste des instructions forment le fragment non
temporel, qui sera coller à la fin du temporel, afin d’obtenir un nouveau programme qui est
sémantiquement équivalent à celui d’origine.
IV- Processus de Restructuration:
Après la construction du ESDG suivant la procédure décrite précédemment, on
détermine la tranche par un marquage arrière des nœuds atteints, commençant à partir des
nœuds déterminés par le critère de troncature. De plus, on classe les méthodes en deux
catégories : (1) les méthodes finales qui n’appellent aucune autre méthode, notée F, (2) les
méthodes intermédiaires qui sont appelées par d’autres méthodes et appellent autres
méthodes, notée I.
Le processus de restructuration consiste en:
71](https://image.slidesharecdn.com/restructurationjavatempsreelmouats-130226161850-phpapp01/85/Restructuration-d-applications-Java-Temps-reel-80-320.jpg)




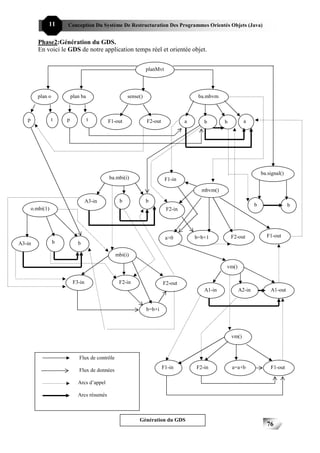
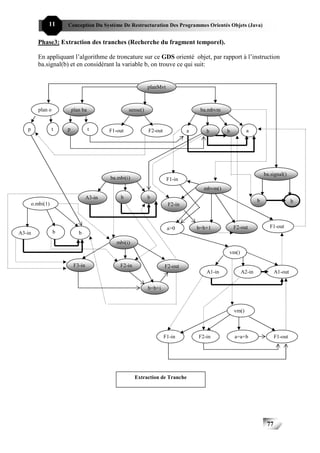



Ce mémoire présente la restructuration d'applications Java temps réel en analysant la décomposition des systèmes et les défis liés à leur conception et leur mise en œuvre. Il aborde des concepts tels que la cohérence temporelle des informations, l'hordonnancement des processus, ainsi que la distinction entre systèmes temps réel durs et souples. L'importance des temps de réponse et de la fiabilité dans ces systèmes est mise en avant, ainsi que les stratégies pour optimiser leur performance.

































































