Télécharger pour lire hors ligne























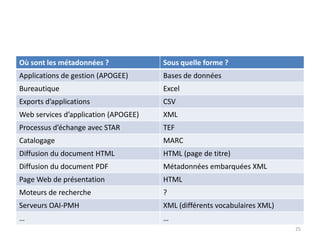





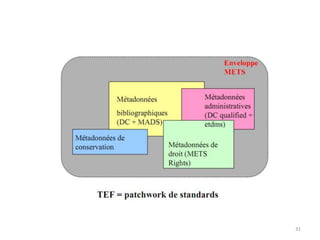

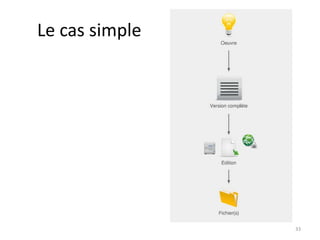
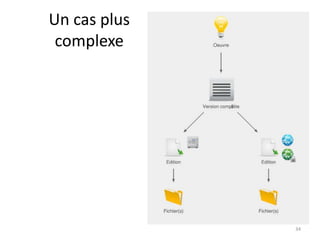
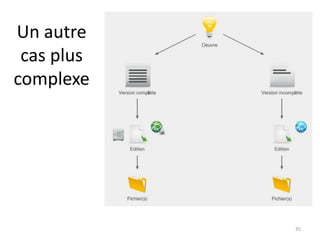

























Ce document aborde les métadonnées liées aux thèses, soulignant leur importance pour la structuration et la réutilisation des informations. Il discute des différents formats et modèles, notamment le format TEF, ainsi que des conditions favorables à la circulation et au recyclage des métadonnées. Enfin, il souligne la nécessité d'utiliser des référentiels et des identifiants pour améliorer l'intégration des métadonnées dans le web sémantique.




































































































